- Research Article
- Open access
- Published:
A Decision-Tree-Based Algorithm for Speech/Music Classification and Segmentation
EURASIP Journal on Audio, Speech, and Music Processing volume 2009, Article number: 239892 (2009)
Abstract
We present an efficient algorithm for segmentation of audio signals into speech or music. The central motivation to our study is consumer audio applications, where various real-time enhancements are often applied. The algorithm consists of a learning phase and a classification phase. In the learning phase, predefined training data is used for computing various time-domain and frequency-domain features, for speech and music signals separately, and estimating the optimal speech/music thresholds, based on the probability density functions of the features. An automatic procedure is employed to select the best features for separation. In the test phase, initial classification is performed for each segment of the audio signal, using a three-stage sieve-like approach, applying both Bayesian and rule-based methods. To avoid erroneous rapid alternations in the classification, a smoothing technique is applied, averaging the decision on each segment with past segment decisions. Extensive evaluation of the algorithm, on a database of more than 12 hours of speech and more than 22 hours of music showed correct identification rates of 99.4% and 97.8%, respectively, and quick adjustment to alternating speech/music sections. In addition to its accuracy and robustness, the algorithm can be easily adapted to different audio types, and is suitable for real-time operation.
1. Introduction
In the past decade a vast amount of multimedia data, such as text, images, video, and audio has become available. Efficient organization and manipulation of this data are required for many tasks, such as data classification for storage or navigation, differential processing according to content, searching for specific information, and many others.
A large portion of the data is audio, from resources such as broadcasting channels, databases, internet streams, and commercial CDs. To answer the fast-growing demands for handling the data, a new field of research, known as audio content analysis (ACA), or machine listening, has recently emerged, with the purpose of analyzing the audio data and extracting the content information directly from the acoustic signal [1] to the point of creating a "Table of Contents" [2].
Audio data (e.g., from broadcasting) often contains alternating sections of different types, such as speech and music. Thus, one of the fundamental tasks in manipulating such data is speech/music discrimination and segmentation, which is often the first step in processing the data. Such preprocessing is desirable for applications requiring accurate demarcation of speech, for instance automatic transcription of broadcast news, speech and speaker recognition, word or phrase spotting, and so forth. Similarly, it is useful in applications where attention is given to music, for example, genre-based or mood-based classification.
Speech/music classification is also important for applications that apply differential processing to audio data, such as content-based audio coding and compressing or automatic equalization of speech and music. Finally, it can also serve for indexing other data, for example, classification of video content through the accompanying audio.
One of the challenges in speech/music discrimination is characterization of the music signal. Speech is composed from a selection of fairly typical sounds and as such, can be represented well by relatively simple models. On the other hand, the assortment of sounds in music is much broader and produced by a variety of instruments, often by many simultaneous sources. As such, construction of a model to accurately represent and encompass all kinds of music is very complicated. This is one of the reasons that most of the algorithmic solutions developed for speech/music discrimination are practically adapted to the specific application they serve. A single comprehensive solution that will work in all situations is difficult to achieve. The difficulty of the task is increased by the fact that on many occasions speech is superimposed on the music parts, or vice versa.
1.1. Former Studies
The topic of speech/music classification was studied by many researchers. Table 1 summarizes some of these studies. It can be seen from the table that, while the applications can be very different, many studies use similar sets of acoustic features, such as short time energy, zero-crossing rate, cepstrum coefficients, spectral rolloff, spectrum centroid and "loudness," alongside some unique features, such as "dynamism." However, the exact combinations of features used can vary greatly, as well as the size of the feature set. For instance, [3, 4] use few features, whereas [1, 2, 5, 6] use larger sets. Typically some long-term statistics, such as the mean or the variance, and not the features themselves, are used for the discrimination.
The major differences between the different studies lie in the exact classification algorithm, even though some popular classifiers (K-nearest neighbour, Gaussian multivariate, neural network) are often used as a basis. Finally, in each study, different databases are used for training and testing the algorithm. It is worth noting that in most of the studies, especially the early ones, these databases are fairly small [6, 7]. Only in a few works large databases are used [8, 9].
1.2. The Algorithm
In this paper we present an efficient algorithm for segmentation of audio signals into speech or music. The central motivation to our study is consumer audio applications, where various real-time enhancements are often applied to music. These include differential frequency gain (equalizers) or spatial effects (such as simulation of surround and reverberation). While these manipulations can improve the perceptive quality of music, applying them to speech can cause distortions (for instance, bass amplification can cause an unpleasant booming effect).
As many audio sources, such as radio broadcasting streams, live performances, or movies, often contain sections of pure speech mixed between musical segments, an automatic real-time speech/music discrimination system may be used to allow the enhancement of music without introducing distortions to the speech.
Considering the application at hand, our algorithm aims to achieve the following:
(i)Pure speech must be identified correctly with very high accuracy, to avoid distortions when enhancements are applied.
(ii)Songs that contain a strong instrumental component together with voice should be classified as music, just like purely instrumental tracks.
(iii)Audio that is neither speech, nor music (noise, environmental sounds, silence, and so forth) can be ignored by the classifier, as it is not important for the application of the manipulations. We can therefore assume that a priori the audio belongs to one of the two classes.
(iv)The algorithm must be able to operate in real time with a low computational cost and a short delay.
The algorithm proposed here answers all these requirements: on one hand, it is highly accurate and robust, and on the other hand, simple, efficient, and adequate for real-time implementation. It achieves excellent results in minimizing misdetection of speech, due to a combination of the feature choice and the decision tree. The percentage of correct detection of music is also very high. Overall the results we obtained were comparable to the best of the published studies, with a confidence level higher than most, due to the large size of test database used.
The algorithm uses various time domain parameters of the audio signal, such as the energy, zero-crossing rate, and autocorrelation as well as frequency domain parameters (spectral energy, MFCC, and others).
The algorithm consists of two stages. The first stage is a supervised learning phase, based on a statistical approach. In this phase training data is collected from speech and music signals separately, and after processing and feature extraction, optimal separation thresholds between speech and music are set for each analyzed feature separately.
In the second stage, the processing phase, an input audio signal is divided into short-time segments and feature extraction is performed for each segment. The features are then compared to their corresponding thresholds, which were set in the learning phase, and initial classification of the segment as speech or music is carried out. Various post-decision techniques are applied to improve the robustness of the classification.
Our test database consisted of 12+ hours of speech and 20+ hours of music. This database is significantly larger than those used for testing in the majority of the aforementioned studies. Tested on this database, the algorithm proved to be highly accurate both in the correctness of the classification and the segmentation accuracy. The processing phase can also be applied in a real-time environment, due to low computation load of the process, and the fact that the classification is localized (i.e., a segment is classified as speech or music independently of other segments). A commercial product based on the proposed algorithm is currently being developed by Waves Audio, and a provisional patent has been filed.
The rest of the paper is arranged as follows: in Section 2 we describe the learning procedure, during which the algorithm is "trained" to distinguish between speech and music, as well as the features used for the distinction. Next, in Section 3, the processing phase and the classification algorithm are described. Section 4 provides evaluation of the algorithm in terms of classification success and comparison to other approaches, and is followed by a conclusion (Section 5).
2. The Learning Phase
2.1. Music and Speech Material
The music material for the training phase was derived mostly from CDs or from databases, using high bitrate signals with a total duration of 60 minutes. The material contained different genres and types of music such as classical music, rock and pop songs, folk music, etc.
The speech material was collected from free internet speech databases, also containing a total of 60 minutes. Both high and low bitrate signals were used.
2.2. General Algorithm
A block diagram of the main algorithm of the learning phase is depicted in Figure 1. The training data is processed separately for speech and for music, and for each a set of candidate features for discrimination is computed. A probability density function (PDF) is then estimated for each feature and for each class (Figure 1(a)). Consequently, thresholds for discrimination are set for each feature, along with various parameters that characterize the distribution relative to the thresholds, as described in Section 2.5. A feature ranking and selection procedure is then applied to select the best set of features for the test phase, according to predefined criteria (Figure 1(b)). A detailed description of this procedure is given in Section 2.6.

A block diagram of the training phase. (a) Feature extraction and computation of probability density functions for each feature. (b) Analysis of the distributions, setting of optimal thresholds, and selection of the best features for discrimination.
2.3. Computation of Features
Each of the speech signals and music signals in the learning phase is divided into consecutive analysis frames of length  with hop size
with hop size  , where
, where  and
and  are in samples, corresponding to 40 milliseconds and 20 milliseconds, respectively. For each frame, the following features are computed:
are in samples, corresponding to 40 milliseconds and 20 milliseconds, respectively. For each frame, the following features are computed:
Short-Time Energy
The short-time energy of a frame is defined as the sum of squares of the signal samples normalized by the frame length and converted to decibels.

Zero-Crossing Rate
The zero-crossing rate of a frame is defined as the number of times the audio waveform changes its sign in the duration of the frame:

Band Energy Ratio
The band energy ratio captures the distribution of the spectral energy in different frequency bands. The spectral energy in a given band is defined as follows: Let  denote one frame of the audio signal (
denote one frame of the audio signal ( ), and let
), and let  denote the Discrete Fourier Transform (DFT) of
denote the Discrete Fourier Transform (DFT) of  . The values of
. The values of  for
for  correspond to discrete frequency bins from
correspond to discrete frequency bins from  to
to  , with
, with  indicating half of the sampling rate
indicating half of the sampling rate  . Let
. Let  denote the frequency in Hz. The DFT bin number corresponding to
denote the frequency in Hz. The DFT bin number corresponding to  is given by
is given by

For a given frequency band  the total spectral energy in the band is given by
the total spectral energy in the band is given by

Finally, if the spectral energies of the two bands  and
and  are denoted
are denoted  and
and  , respectively, the ratio is computed on a logarithmic scale, as follows:
, respectively, the ratio is computed on a logarithmic scale, as follows:

We used two features based on band energy ratio—the low energy ratio, defined as the ratio between the spectral energy below 70 Hz and the total energy, and the high energy ratio, defined as the ratio between the energy above 11 KHz and the total energy, where the sampling frequency is 44 KHz.
Autocorrelation Coefficient
The autocorrelation coefficient is defined as the highest peak in the short-time autocorrelation sequence and is used to evaluate how close the audio signal is to a periodic one. First, the normalized autocorrelation sequence of the frame is computed:

Next, the highest peak of the autocorrelation sequence between  and
and  is located, where
is located, where  and
and  correspond to periods between 3 milliseconds and 16 milliseconds (which is the expected fundamental frequency range in voiced speech). The autocorrelation coefficient is defined as the value of this peak:
correspond to periods between 3 milliseconds and 16 milliseconds (which is the expected fundamental frequency range in voiced speech). The autocorrelation coefficient is defined as the value of this peak:

Mel Frequency Cepstrum Coefficients
The mel frequency cepstrum coefficients (MFCCs) are known to be a compact and efficient representation of speech data [17, 18]. The MFCC computation starts by taking the DFT of the frame  and multiplying it by a series of triangularly shaped ideal band-pass filters
and multiplying it by a series of triangularly shaped ideal band-pass filters  , where the central frequencies and widths of the filters are arranged according to the mel scale [19]. Next, the total spectral energy contained in each filter is computed:
, where the central frequencies and widths of the filters are arranged according to the mel scale [19]. Next, the total spectral energy contained in each filter is computed:

where  and
and  are the lower and upper bounds of the filter and
are the lower and upper bounds of the filter and  is a normalization coefficient to compensate for the variable bandwidth of the filters:
is a normalization coefficient to compensate for the variable bandwidth of the filters:

Finally, the MFCC sequence is obtained by computing the Discrete Cosine Transform (DCT) of the logarithm of the energy sequence  :
:

We computed the first 10 MFC coefficients for each frame. Each individual MFC coefficient is considered a feature. In addition, the MFCC difference vector between neighboring frames is computed, and the Euclidean norm of that vector is used as an additional feature:

where  represents the index of the frame.
represents the index of the frame.
Spectrum Rolloff Point
The spectrum rolloff point [6] is defined as the boundary frequency  , such that a certain percent
, such that a certain percent  of the spectral energy for a given audio frame is concentrated below
of the spectral energy for a given audio frame is concentrated below  :
:

In our study  is used.
is used.
Spectrum Centroid
The spectrum centroid is defined as the center of gravity (COG) of the spectrum for a given audio frame and is computed as

Spectral Flux
The spectral flux measures the spectrum fluctuations between two consecutive audio frames. It is defined as

namely, the sum of the squared frame-to-frame difference of the DFT magnitudes [6], where  and
and  are the frame indices.
are the frame indices.
Spectrum Spread
The spectrum spread [1] is a measure that computes how the spectrum is concentrated around the perceptually adapted audio spectrum centroid, and calculated according to the following:

where  is the frequency associated with each frequency bin, and ASC is the perceptually adapted audio spectral centroid, as in [1], which is defined as
is the frequency associated with each frequency bin, and ASC is the perceptually adapted audio spectral centroid, as in [1], which is defined as

2.4. Computation of Feature Statistics
Each of the above features is computed on frames of duration  , where
, where  is in samples, typically corresponding to
is in samples, typically corresponding to  milliseconds of audio. In order to extract more data to aid the classification, the feature information is collected over longer segments of length
milliseconds of audio. In order to extract more data to aid the classification, the feature information is collected over longer segments of length  (2–6 seconds). For each such segment and each feature the following statistical parameters are computed:
(2–6 seconds). For each such segment and each feature the following statistical parameters are computed:
-
(i)
Mean value and standard deviation of the feature across the segment.
(ii)Mean value and standard deviation of the difference magnitude between consecutive analysis points.
In addition to that, for the zero-crossing rate, the skewness (third central moment, divided by the cube of the standard deviation) and the skewness of the difference magnitude between consecutive analysis frames are also computed.
For the energy we also measure the low short time energy ratio (LSTER, [9]). The LSTER is defined as the percentage of frames within the segment whose energy level is below one third of the average energy level across the segment.
2.5. Threshold Setting and Probability Density Function Estimation
In the learning phase, training data is collected for speech segments and for music segments separately. For each feature and each statistical parameter the corresponding probability density functions (PDFs) are estimated—one for speech segments and one for music segments. The PDFs are computed using a nonparametric technique with a Gaussian kernel function for smoothing.
Five thresholds are computed for each feature, based on the estimated PDFs (Figure 2).

Probability density function for a selected feature (standard deviation of the short-time energy). Left curve: music data; right curve: speech data. Thresholds (left to right): music extreme, music high probability, separation, speech high probability, speech extreme.
-
(1)
Extreme speech threshold—defined as the value beyond which there are only speech segments, that is, 0% error based on the learning data.
-
(2)
Extreme music threshold—same as 1, for music.
-
(3)
High probability speech threshold—defined as the point in the distribution where the difference between the height of the speech PDF and the height of the music PDF is maximal. This threshold is more permissive than the extreme speech threshold: values beyond this threshold are typically exhibited by speech, but a small error of music segments is usually present. If this error is small enough, and on the other hand a significant percentage of speech segments are beyond this threshold, the feature may be a good candidate for separation between speech and music.
-
(4)
High probability music threshold—same as 3, for music.
(5)Separation threshold—defined as the value that minimizes the joint decision error, assuming that the prior probabilities for speech and for music are equal.
For each of the first four thresholds the following parameters are computed from the training data:
-
(i)
inclusion fraction (
 )—the percentage of correct segments that exceed the threshold (for the speech threshold this refers to speech segments, and for the music threshold this refers to music segments);
)—the percentage of correct segments that exceed the threshold (for the speech threshold this refers to speech segments, and for the music threshold this refers to music segments); -
(ii)
error fraction (
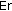 )—the percentage of incorrect segments that exceed the threshold. For speech thresholds these are the music segments, and for music thresholds these are the speech segments. Note that by the definition of the extreme thresholds, their error fractions are 0.
)—the percentage of incorrect segments that exceed the threshold. For speech thresholds these are the music segments, and for music thresholds these are the speech segments. Note that by the definition of the extreme thresholds, their error fractions are 0.
 )—the percentage of correct segments that exceed the threshold (for the speech threshold this refers to speech segments, and for the music threshold this refers to music segments);
)—the percentage of correct segments that exceed the threshold (for the speech threshold this refers to speech segments, and for the music threshold this refers to music segments);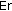 )—the percentage of incorrect segments that exceed the threshold. For speech thresholds these are the music segments, and for music thresholds these are the speech segments. Note that by the definition of the extreme thresholds, their error fractions are 0.
)—the percentage of incorrect segments that exceed the threshold. For speech thresholds these are the music segments, and for music thresholds these are the speech segments. Note that by the definition of the extreme thresholds, their error fractions are 0.2.6. Feature Selection
With a total of over 20 features computed on the frame level and 4–6 statistical parameters computed per feature on the segment level, the feature space is quite large. More importantly, not all features contribute equally, and some features may be very good in certain aspects, and bad in others. For example, a specific feature may have a very high value of  for the extreme speech threshold, but a very low value of
for the extreme speech threshold, but a very low value of  for the extreme music threshold, making it suitable for one feature group, but not the other.
for the extreme music threshold, making it suitable for one feature group, but not the other.
The main task here is to select the best features for each classification stage to ensure high discrimination accuracy and to reduce the dimension of the feature space.
The "usefulness" score is computed separately for each feature and each of the thresholds. The feature ranking method is different for each of the three threshold types (extreme speech/music, high probability speech/music, and separation).
For the extreme thresholds, the features are ranked according to the value of the corresponding inclusion fraction  . When
. When  is large, the feature is likely to be more useful for identifying typical speech (resp., music) frames.
is large, the feature is likely to be more useful for identifying typical speech (resp., music) frames.
For the high probability thresholds, we define the "separation power" of a feature as  . This particular definition is chosen due to its tendency, for a given inclusion/error ratio, to prefer features with higher inclusion fraction
. This particular definition is chosen due to its tendency, for a given inclusion/error ratio, to prefer features with higher inclusion fraction  . Since independence of features cannot be assumed a priori, we adjusted the selection procedure to consider the mutual correlation between features as well as their separation power. In each stage, a feature is chosen from the pool of remaining features, based on a linear combination of its separation power and its mutual correlation with all previously selected features. This is formalized as follows:
. Since independence of features cannot be assumed a priori, we adjusted the selection procedure to consider the mutual correlation between features as well as their separation power. In each stage, a feature is chosen from the pool of remaining features, based on a linear combination of its separation power and its mutual correlation with all previously selected features. This is formalized as follows:
-
(i)
let
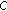 be the separation power (for the extreme thresholds we set
be the separation power (for the extreme thresholds we set 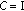 , whereas for the high probability thresholds we use
, whereas for the high probability thresholds we use 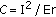 );
); -
(ii)
in the first stage select the first feature that maximizes
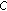 :
:  ;
; -
(iii)
the second feature
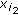 is computed so that
is computed so that
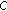 be the separation power (for the extreme thresholds we set
be the separation power (for the extreme thresholds we set 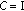 , whereas for the high probability thresholds we use
, whereas for the high probability thresholds we use 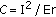 );
);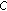 :
:  ;
;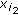 is computed so that
is computed so that
where  and
and  are weighting factors (typically
are weighting factors (typically  ), determining the relative contributions of
), determining the relative contributions of  and of the mutual correlation
and of the mutual correlation  :
:

-
(iv)
the
 th feature
th feature 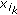 is computed using
is computed using
 th feature
th feature 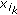 is computed using
is computed using
For the separation threshold we originally tried the Fisher Discriminant Ratio (FDR, [20]) as a measure of the feature separation power:

where  ,
,  are the mean values and
are the mean values and  ,
,  are the standard deviations, for speech and music, respectively. As in the first two stages, the features were selected according to a combination of the FDR and the mutual correlation.
are the standard deviations, for speech and music, respectively. As in the first two stages, the features were selected according to a combination of the FDR and the mutual correlation.
A small improvement was achieved by using the sequential floating (forward-backward) selection procedure detailed in [20, 21]. The advantage of this procedure is that it considers separation power of entire feature vector as a whole, and not just as combination of individual features.
To measure the separation power of the feature vectors, we computed the scatter matrices and
and  .
.  is the within-class scatter matrix, defined as the normalized sum of the class covariance matrices
is the within-class scatter matrix, defined as the normalized sum of the class covariance matrices  and
and  :
:

 is the mixture scatter matrix, defined as the covariance matrix of the feature vector (all samples, both speech and music) around the global mean.
is the mixture scatter matrix, defined as the covariance matrix of the feature vector (all samples, both speech and music) around the global mean.
Finally, the separation criterion is defined as

This criterion tends to take large values when the within-class scatter is small, that is, the samples are well-clustered around the class mean, but the overall scatter is large, implying that the clusters are well-separated. More details can be found in [20].
2.7. Best Features for Discrimination
Using the above selection procedure, the best features for each of the five thresholds were chosen. The optimal number of features in each group is typically selected by trying different combinations in a cross-validation setting over the training set, to achieve the best detection rates. Table 2 lists these features in descending order (best is first). Note that it is possible to take a smaller subset of the features.
As can be seen from the table, certain features, for example, the energy, the autocorrelation, and the 9th MFCC are useful in multiple stages, while some, like the spectral rolloff point, are used only in one of the stages. Also it can be noticed that some of the features considered in the learning phase were found inefficient in practice and were eliminated from the features set in the test phase. As the procedure is automatic, the user does not even have to know which features are selected, and in fact very different sets of features were sometimes selected for different thresholds.
3. Test Phase and Speech/Music Segmentation
The aim of the test phase is to perform segmentation of a given audio signal into "speech" and "music". There are no prior assumptions on the signal content or the probabilities of each of the two classes. Each segment is classified separately and almost independently of other segments. A block diagram describing the classification algorithm is shown on Figure 3.

General block diagram of the classficication algorithm.
3.1. Streaming and Feature Computation
The input signal is divided into consecutive segments, with segment size  . Each segment is further divided into consecutive and overlapping frames with frame size
. Each segment is further divided into consecutive and overlapping frames with frame size  (as in the learning phase) and hop size
(as in the learning phase) and hop size  , where typically
, where typically  . For each such frame, the features that were chosen by the feature selection procedure (Section 2.6) are computed. Consequently, the feature statistics are computed over the segment (of length
. For each such frame, the features that were chosen by the feature selection procedure (Section 2.6) are computed. Consequently, the feature statistics are computed over the segment (of length  ) and compared to the predefined thresholds, which were also set during the learning phase. This comparison is used as a basis for classification of the segment either as speech or as music, as described below.
) and compared to the predefined thresholds, which were also set during the learning phase. This comparison is used as a basis for classification of the segment either as speech or as music, as described below.
In order to provide better tracking of the changes in the signal, the segment hop size  , which represents the resolution of the decision, is set to a small fraction of the segment size (typically
, which represents the resolution of the decision, is set to a small fraction of the segment size (typically  ).
).
For the evaluation tests (Section 4) the following values were used:  milliseconds,
milliseconds,  milliseconds,
milliseconds,  seconds.
seconds.
3.2. Initial Classification
The initial decision is carried out for each segment independently of other segments. In this decision each segment receives a grade between  and 1, where positive grades indicate music and negative grades indicate speech, and the actual value represents the degree of certainty in the decision (e.g.,
and 1, where positive grades indicate music and negative grades indicate speech, and the actual value represents the degree of certainty in the decision (e.g.,  means speech/music with high certainty).
means speech/music with high certainty).
For each of the five threshold types computed in the learning phase (see Section 2.5) a set of features is selected, that are compared to their corresponding thresholds. The features for each set are chosen according to the feature selection procedure (see Section 2.6). After comparing all features to the thresholds, the values are computed as shown in Table 3 .
A segment receives a grade of  if one of the following takes place:
if one of the following takes place:
(i) and
and  (i.e., at least one of the features is above its corresponding extreme speech threshold; whereas no feature surpasses the extreme or the high probability music thresholds);
(i.e., at least one of the features is above its corresponding extreme speech threshold; whereas no feature surpasses the extreme or the high probability music thresholds);
(ii) and
and  (we allow
(we allow  if
if  is at least 2);
is at least 2);
(iii) and
and  , where
, where  ,
,  is the set of all features used with the high probability speech threshold (i.e., if a decision cannot be made using the extreme thresholds, we demand a large majority of the high probability thresholds to classify the segment as speech with high certainty).
is the set of all features used with the high probability speech threshold (i.e., if a decision cannot be made using the extreme thresholds, we demand a large majority of the high probability thresholds to classify the segment as speech with high certainty).
The above combination of rules allows classifying a segment as speech in cases where its feature vector is located far inside the speech half-space along some of the feature axes, and at the same time, is not far inside the music half-space along any of the axes. In such cases we can be fairly certain of the classification. It is expected that if the analyzed segment is indeed speech, it will rarely exhibit any features above the extreme or high probability music thresholds.
Similarly, a segment gets a grade of  (that is considered as music with high certainty) if one of the following takes place:
(that is considered as music with high certainty) if one of the following takes place:
(i) and
and  ,
,
(ii) and
and  ,
,
(iii) , and
, and  , where
, where  ,
,  is the set of all features used with the high probability speech threshold.
is the set of all features used with the high probability speech threshold.
If none of the above applies, the decision is based on the separation threshold as follows:

where  is the set of features used with the separation threshold. Note that
is the set of features used with the separation threshold. Note that  , and
, and  , so the received grade is always between
, so the received grade is always between  and 1, and in some way reflects the certainty with which the segment can be classified as speech or music.
and 1, and in some way reflects the certainty with which the segment can be classified as speech or music.
This procedure of assigning a grade to each segment is summarized in Figure 4.

A schematic flowchart of the initial decision made for each segment in the test phase.
3.3. Smoothing and Final Classification
In most audio signals, speech-music and music-speech transitions are not very common (for instance, musical segments are usually at least one minute long, and typically several minutes or longer). When the classification of an individual segment is based solely on data collected from that segment (as described above), erroneous decisions may lead to classification results that alternate more rapidly than normally expected. To avoid this, the initial decision is smoothed by a weighted average with past decisions, using an exponentially decaying "forgetting factor," which gives more weight to recent segments:

where  is the length of the averaging period,
is the length of the averaging period,  is the time constant, and
is the time constant, and  is the normalizing constant. Alternatively, we tried a median filter for the smoothing. Both approaches achieved comparable results.
is the normalizing constant. Alternatively, we tried a median filter for the smoothing. Both approaches achieved comparable results.
Following the smoothing procedure, discretization to a binary decision is performed as follows: a threshold value  is determined. Values above
is determined. Values above  or below
or below  are set to 1 or
are set to 1 or  , respectively, whereas values between
, respectively, whereas values between  and
and  are treated according to the current trend of
are treated according to the current trend of  , that is, if
, that is, if  is on the rise,
is on the rise,  and
and  otherwise, where
otherwise, where  is the binary desicion.
is the binary desicion.
Additionally, a four-level decision is possible, where values in  are treated as "weakly speech" or "weakly music." The four-level decision mode is useful for mixed content signals, which are difficult to firmly classify as speech or music.
are treated as "weakly speech" or "weakly music." The four-level decision mode is useful for mixed content signals, which are difficult to firmly classify as speech or music.
To avoid erroneous transitions in long periods of either music or speech, we adapt the threshold over time as follows: let  be the threshold at time
be the threshold at time  , and
, and  be the binary decision values of the current and the previous time instants, respectively. We have the following:
be the binary decision values of the current and the previous time instants, respectively. We have the following:

where  is a predefined multiplier,
is a predefined multiplier,  is the initial value of the threshold, and
is the initial value of the threshold, and  is a minimal value, which is set so that the threshold will not reach a value of zero. This mechanism ensures that whenever a prolonged music (or speech) period is processed, the absolute value of the threshold is slowly decreased towards the minimal value. When the decision is changed, the threshold value is reset to
is a minimal value, which is set so that the threshold will not reach a value of zero. This mechanism ensures that whenever a prolonged music (or speech) period is processed, the absolute value of the threshold is slowly decreased towards the minimal value. When the decision is changed, the threshold value is reset to  .
.
4. Evaluation and Results
4.1. Speech and Music Material
The speech material for the evaluation was collected from various free internet speech databases, such as the International Dialects of English Archive (http://www.ku.edu/~idea/), the World Voices Collection (http://www.world-voices.com/), the Indian institute of scientific heritage (http://www.iish.org/), and others. The test set contained both clean speech and noisy speech. Most of the data were MP3 files at bitrates of 128Kbps and higher or uncompressed PCM WAV files.
The music material for the test set contained music of different genres, such as classical, folk, pop, rock, metal, new age, and others. The source material was either in cd audio format (uncompressed) or mp3 (64 kbps and higher).
4.2. Evaluation of Long Tracks
The evaluation was performed on approximately 12 hours of speech and 22 hours of music from the above material. The results are summarized in Table 4. For music, the correct identification rate is 97.8% (98.9% excluding the electronic music). A breakdown of music detection rates into different genres is summarized in Table 5. It can be noticed that in electronic music and pop, the scores are lower than those of the other genres. For speech an identification rate of 99.4% has been achieved.
4.3. Evaluation of Alternating Sections
In this test, a signal was constructed from 80 alternating sections of speech (40 sections) and music (40 sections), each 30 seconds long. The proportion of correct detection is shown in Table 6. Since the first six seconds of each section are defined as transition time, only the steady-state portion of the signal is taken into account, that is, 960 seconds of each type, speech and music.
Most of the sections were identified perfectly. Among the speech sections only 2 out of 40 sections were problematic, where in one case the speech was excerpted from a TV soundtrack with background music, and the other contained strong background noise. Among the music, only 3 out of 40 sections had errors, 2 of them containing a strong vocal element. The high success rates are even more satisfying considering the fact that most of the speech sections were with a background noise.
4.4. Gradual Transitions
In radio and TV broadcasts, gradual speech-music and music-speech transitions are often present, for example between songs and the voice of the announcer. Because our algorithm supports soft speech/music classifications, it can recognize such gradual transitions. Figure 5 shows a transition between music and speech at the end of a song. After the first 8 seconds the music fades out and the announcer starts speaking over it, and for the last 4 seconds there is only the announcer's voice.

Gradual transition between music and speech. (a) The audio section (17 seconds). (b) The continuous speech/music classification curve.
4.5. Comparison with Other Approaches
In order to evaluate the algorithm in the context of existing work, we compared it to traditional approaches, such as the Support Vector Machine (SVM, [22, 23]) and the Linear Discriminant Analysis (LDA, [20]). For the training, our original training databases were used, and for the testing we chose the Scheirer-Slaney database, provided to us by Dan Ellis. The database consists of radio recordings, with 20 minutes of speech and 20 minutes of music. This allows us to compare our results directly with past studies that used the same database such as [6, 12, 16].
In our comparative tests, the optimal feature sets for each classifier (the proposed algorithm, SVM and LDA) were chosen using the automatic feature selection procedure detailed in Section 2.6. For the SVM the Gaussian (radial basis function) kernel was used, as it has some advantages compared to the linear SVM and others. The data for the SVM training was automatically scaled to zero mean and unit variance, and the free parameters were selected using grid search, and evaluated through cross-validation [24, 25].
The SVM and LDA algorithms were tested individually, as stand-alone classifiers, as well as in the general framework of our decision tree, replacing the separation stage of the initial classification (Section 3.2), that is,  was assigned according to the output of the classifier, and the postprocessing techniques described in Section 3.3 were applied to it. Additionally, we tested a combination of the two techniques—with LDA being used for feature selection, and SVM for the classification.
was assigned according to the output of the classifier, and the postprocessing techniques described in Section 3.3 were applied to it. Additionally, we tested a combination of the two techniques—with LDA being used for feature selection, and SVM for the classification.
The best results achieved for each classifier are shown in Figure 6. It can be seen that in all cases, the results are very good, and that the success rates attained by our algorithm are comparable and slightly better, with 99.07% correct detection. We further see that the usage of the full three-level decision tree, and the decision postprocessing techniques slightly improve the success rates of both SVM and LDA. The overall error rate of our decision tree algorithm (0.93%) is comparable, and somewhat surpasses the 1.3–1.5% rates reported in [6, 12, 16], although it should be noticed that, unlike in those studies, here the database was solely for testing, whereas the training was done on different data.

Comparison of five approaches: the proposed decision tree algorithm (TREE), Linear Discriminant Analysis (LDA), Support Vector Machine (SVM), and a combination of the SVM/LDA classifiers with the decision tree, in which the classifiers take the place of the separation stage. The best detection rates achieved with each classifier are shown, for speech, music and overall.
4.6. The Importance of Feature Selection
To verify the contribution of the feature selection procedure to the performance of the classifier, we conducted two experiments with the SVM classifier, using a base feature set of 28 different features. In the one experiment, the best 9 features were selected, and in the other one, all features were used. The results are summarized in Table 7. It can be seen that feature selection allows higher performance to be achieved.
5. Conclusion
In this paper we presented an algorithm for speech/music classification and segmentation, based on a multistage statistical approach. The algorithm consists of a training stage with an automatic selection of the most efficient features and the optimal thresholds, and a processing stage, during which an unknown audio signal is segmented into speech or music through a sieve-like rule-based procedure.
Tested on a large test set of about 34 hours of audio from different resources, and of varying quality, the algorithm demonstrated very high accuracy in the classification (98%, and over 99% under certain conditions), as well as fast response to transitions from music to speech and vice versa. The test database is among the largest used in similar studies and suggests that the algorithm is robust and applicable in various testing conditions.
The algorithm was tested against standard approaches such as SVM and LDA, and showed comparable, often slightly better, results. On the other hand, the decision tree uses simple heuristics, which are easy to implement in a variety of hardware and software frameworks. This together with its fast and highly localized operation makes it suitable for real-time systems and for consumer-grade audio processing applications. A commercial product based on the presented algorithm is currently being developed by Waves Audio, and a provisional patent has been filed.
Another advantage of the presented algorithm is the generic training procedure, which allows testing any number of additional features and selecting the optimal feature set using an automatic and flexible procedure.
One possible direction for improvement of the algorithm is increasing the segmentation accuracy in speech-music and music-speech transitions. In an offline application this could be achieved, without harming the overall identification rate, by postprocessing the boundary regions using smaller segments.
References
Burred JJ, Lerch A: Hierarchical automatic audio signal classification. Journal of the Audio Engineering Society 2004,52(7-8):724-739.
Bugatti A, Flammini A, Migliorati P: Audio classification in speech and music: a comparison between a statistical and a neural approach. EURASIP Journal on Applied Signal Processing 2002,2002(4):372-378. 10.1155/S1110865702000720
Muñoz-Expósito JE, Galán SG, Reyes NR, Candeas PV, Peña FR: A fuzzy rules-based speech/music discrimination approach for intelligent audio coding over the Internet. Proceedings of the 120th Audio Engineering Society Convention (AES '06), May 2006, Paris, France paper number 6676
Saunders J: Real-time discrimination of broadcast speech/music. Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '96), May 1996, Atlanta, Ga, USA 2: 993-996.
Liu Z, Huang J, Wang Y, Chen IT: Audio feature extraction and analysis for scene classification. Proceedings of the 1st IEEE Workshop on Multimedia Signal Processing (MMSP '97), June 1997, Princeton, NJ, USA 343-348.
Scheirer E, Slaney M: Construction and evaluation of a robust multifeature speech/music discriminator. Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '97), April 1997, Munich, Germany 2: 1331-1334.
Ajmera J, McCowan IA, Bourlard H: Robust HMM-based speech/music segmentation. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP '03), May 2002, Orlando, Fla, USA 1: 297-300.
Carey MJ, Parris ES, Lloyd-Thomas H: A comparison of features for speech, music discrimination. Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '99), March 1999, Phoenix, Ariz, USA 1: 149-152.
Lu L, Zhang H-J, Jiang H: Content analysis for audio classification and segmentation. IEEE Transactions on Speech and Audio Processing 2002,10(7):504-516. 10.1109/TSA.2002.804546
Foote JT: A similarity measure for automatic audio classification. Proceedings of the AAAI Spring Symposium on Intelligent Integration and Use of Text, Image, Video, and Audio Corpora, March 1997, Stanford, Calif, USA
Zhang T, Kuo C-CJ: Hierarchical classification of audio data for archiving and retrieving. Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '99), March 1999, Phoenix, Ariz, USA 6: 3001-3004.
Williams G, Ellis DPW: Speech/music discrimination based on posterior probability features. Proceedings of the 6th European Conference on Speech Communication and Technology (EUROSPEECH '99), September 1999, Budapest, Hungary 687-690.
El-Maleh K, Klein M, Petrucci G, Kabal P: Speech/music discrimination for multimedia applications. Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '00), June 2000, Istanbul, Turkey 6: 2445-2448.
Ajmera J, McCowan I, Bourlard H: Speech/music segmentation using entropy and dynamism features in a HMM classification framework. Speech Communication 2003,40(3):351-363. 10.1016/S0167-6393(02)00087-0
Barbedo JGA, Lopes A: A robust and computationally efficient speech/music discriminator. Journal of the Audio Engineering Society 2006,54(7-8):571-588.
Alexandre E, Rosa M, Caudra L, Gil-Pita R: Application of Fisher linear discriminant analysis to speech/music classification. Proceedings of the 120th Audio Engineering Society Convention (AES '06), May 2006, Paris, France paper number 6678
Davis SB, Mermelstein P: Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Transactions on Acoustics, Speech, and Signal Processing 1980,28(4):357-366. 10.1109/TASSP.1980.1163420
Quatieri TF: Discrete-Time Speech Signal Processing. Prentice-Hall, Englewood Cliffs, NJ, USA; 2001.
Stevens SS, Volkman J: The relation of pitch to frequency: a revised scale. American Journal of Psychology 1940,53(3):329-353. 10.2307/1417526
Theodoridis S, Koutroumbas K: Pattern Recognition. 4th edition. Academic Press, New York, NY, USA; 2003.
Pudil P, Novovicova J, Kittler J: Floating search methods in feature selection. Pattern Recognition Letters 1994,15(11):1119-1125. 10.1016/0167-8655(94)90127-9
Cristianini N, Shawe-Taylor J: An Introduction to Support Vector Machines and other Kernel-Based Learning Methods. Cambridge University Press, Cambridge, UK; 2000.
Burges CJC: Simplified support vector decision rules. Proceedings of the 13th International Conference on Machine Learning (ICML '96), July 1996, Bari, Italy 71-77.
Staelin C: Parameter selection for support vector machines. HP Laboratories Israel, Haifa, Israel; 2003.
Hsu CW, Chang CC, Lin CJ: A practical guide to support vector classification. National Taiwan University, Taipei, Taiwan; 2003.
Acknowledgments
The authors would like to thank I. Neoran, Director of R&D of Waves Audio, for his valuable discussions and ideas, and Y. Yakir for technical assistance. They also thank D. Ellis for providing them the database they used in part of the experiments. Finally, they would like to thank the reviewers for many good remarks which helped them improve the paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Lavner, Y., Ruinskiy, D. A Decision-Tree-Based Algorithm for Speech/Music Classification and Segmentation. J AUDIO SPEECH MUSIC PROC. 2009, 239892 (2009). https://doi.org/10.1155/2009/239892
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1155/2009/239892