Table 1 Test set performance comparison of models selected on a validation set. The second column indicates the number of Gaussians per phoneme. For ensemble methods, 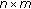 denotes
denotes  models, each having
models, each having 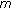 Gaussian components per state. GMM indicates a model consisting of a single Gaussian mixture for each phoneme. HMM indicates a model consisting of three Gaussian mixtures per phoneme. Thus, for HMMs, the total number of Gaussians is three times that of the GMMs with an equal number of components per state. Boost and Bag models indicate models trained using the standard boosting and bagging algorithm, respectively, on the phoneme classification task, while E-boost indicates the expectation boosting algorithm for word error rate minimisation. Finally embed indicates that embedded training was performed subsequently to initialisation of the model.
Gaussian components per state. GMM indicates a model consisting of a single Gaussian mixture for each phoneme. HMM indicates a model consisting of three Gaussian mixtures per phoneme. Thus, for HMMs, the total number of Gaussians is three times that of the GMMs with an equal number of components per state. Boost and Bag models indicate models trained using the standard boosting and bagging algorithm, respectively, on the phoneme classification task, while E-boost indicates the expectation boosting algorithm for word error rate minimisation. Finally embed indicates that embedded training was performed subsequently to initialisation of the model.
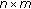 denotes
denotes  models, each having
models, each having 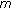 Gaussian components per state. GMM indicates a model consisting of a single Gaussian mixture for each phoneme. HMM indicates a model consisting of three Gaussian mixtures per phoneme. Thus, for HMMs, the total number of Gaussians is three times that of the GMMs with an equal number of components per state. Boost and Bag models indicate models trained using the standard boosting and bagging algorithm, respectively, on the phoneme classification task, while E-boost indicates the expectation boosting algorithm for word error rate minimisation. Finally embed indicates that embedded training was performed subsequently to initialisation of the model.
Gaussian components per state. GMM indicates a model consisting of a single Gaussian mixture for each phoneme. HMM indicates a model consisting of three Gaussian mixtures per phoneme. Thus, for HMMs, the total number of Gaussians is three times that of the GMMs with an equal number of components per state. Boost and Bag models indicate models trained using the standard boosting and bagging algorithm, respectively, on the phoneme classification task, while E-boost indicates the expectation boosting algorithm for word error rate minimisation. Finally embed indicates that embedded training was performed subsequently to initialisation of the model.From: Phoneme and Sentence-Level Ensembles for Speech Recognition
Model | Gaussians | Word error rate (%) |
|---|---|---|
GMM | 30 | 8.31 |
GMM embed | 40 | 8.12 |
Boost GMM |
| 7.41 |
HMM | 10 | 7.52 |
HMM embed | 10 | 7.04 |
Boost HMM |
| 6.81 |
E-Boost HMM | 7 × 10 ( | 6.75 |
Bag HMM | 16 × 20 | 5.97 |


 )
)