- Research Article
- Open access
- Published:
The Effect of a Voice Activity Detector on the Speech Enhancement Performance of the Binaural Multichannel Wiener Filter
EURASIP Journal on Audio, Speech, and Music Processing volume 2010, Article number: 840294 (2010)
Abstract
A multimicrophone speech enhancement algorithm for binaural hearing aids that preserves interaural time delays was proposed recently. The algorithm is based on multichannel Wiener filtering and relies on a voice activity detector (VAD) for estimation of second-order statistics. Here, the effect of a VAD on the speech enhancement of this algorithm was evaluated using an envelope-based VAD, and the performance was compared to that achieved using an ideal error-free VAD. The performance was considered for stationary directional noise and nonstationary diffuse noise interferers at input SNRs from −10 to +5 dB. Intelligibility-weighted SNR improvements of about 20 dB and 6 dB were found for the directional and diffuse noise, respectively. No large degradations (<1 dB) due to the use of envelope-based VAD were found down to an input SNR of 0 dB for the directional noise and −5 dB for the diffuse noise. At lower input SNRs, the improvement decreased gradually to 15 dB for the directional noise and 3 dB for the diffuse noise.
1. Introduction
An increasing number of people suffer from hearing loss, a deficit that can limit them in their interaction with the surrounding world and often severely reduces their quality of life. The most common type of hearing loss is the sensorineural, caused by damage to the inner ear (cochlea). People with sensorineural hearing loss often find it difficult to understand speech in the presence of background noise, even when wearing their hearing aids. Consequences of sensorineural hearing loss vary from one individual to another, but factors that often contribute are reduced audibility, loudness recruitment, reduced frequency selectivity, and reduced temporal resolution. Reduced audibility can be compensated for by a hearing aid through amplification, and loudness recruitment can to some extent be alleviated by compression. However, other contributing factors, such as reduced frequency selectivity or deficits in temporal processing, cannot fully be compensated for by a hearing aid. Even if the hearing loss is located in the cochlea and the higher levels of the auditory system function well, the impaired ear may not be able to pass on the multitude of cues otherwise available in the incoming sound. The internal representation of the signals can then be incomplete and difficult to analyze. It is well known that the intelligibility of speech is tightly connected to the signal-to-noise ratio (SNR) [1]. Thus, the problem of speech intelligibility (SI) in noise can be approached by reducing the noise level. While normal-hearing (NH) people can have a speech reception threshold (SRT; the point where 50% of speech is intelligible) at SNRs in the range of −5 to −10 dB depending on the type of noise [2], this threshold is typically 5-6 dB higher for hearing-impaired (HI) people [3]. At SNRs comparable to the SRT, a small increase in SNR can improve the intelligibility scores drastically as a 1 dB increase can lead to an improvement of up to 15% [4]. This also implies that even a few dB of elevated SRT in HI listeners can cause substantial problems understanding speech compared to NH listeners. Thus, many HI listeners could benefit from a noise reduction of about 5 dB [3], depending on the acoustical environment.
The noise reduction techniques used in hearing aids employ either a single-microphone or multiple microphones. Single-microphone techniques have been shown not to improve SI in noise but may improve listening comfort [5]. On the other hand, multimicrophone techniques can exploit the spatial diversity of acoustic sources, ensuring that both temporal and spatial processing can be performed. Several microphone array processing techniques have been shown to improve SI in noise [5]. Particularly, adaptive arrays can in certain conditions reduce impressive amounts of noise. However, while the array benefit in hearing aid applications can be very large in the case of a single noise source in mild reverberation, it reduces considerably when several interfering sources are present or when the environment is reverberant [6]. This is due to the use of small arrays with a limited number of microphones used in hearing aids, which limits the array performance. Nevertheless, as small improvements of a few dB might improve intelligibility significantly, a large SNR improvement is not always necessary.
One potential problem with microphone array processing is that it may affect the hearing aid user's sense of the auditory space. Some studies have shown that the users can localize sounds better when the directionality in their hearing aid is switched off [7, 8]. Preserving the interaural localization cues can have a positive effect on speech intelligibility in complex acoustic environments, as the binaural processor in the auditory system can exploit additional information provided by the two ears. Many HI people are able to take advantage of the low frequency interaural time delays (ITDs) almost as effectively as NH people [9]. Thus, a system that combines noise reduction with preservation of ITDs would be desirable. Such an algorithm has recently been proposed in [10], as a binaural extension of a multichannel Wiener filter-based speech enhancement algorithm proposed in [11]. In [12] it was shown theoretically that the binaural version preserves the interaural time delays (ITDs) and interaural level differences (ILDs) of the speech component. It was also shown that the ITDs and ILDs of the noise component are distorted in such a way that they become equal to those of the speech component. Therefore, in [13], the Binaural Multichannel Wiener Filter (BMWF) algorithm was extended to preserve the ITDs of the noise component. A parameter that can pass a specified amount of noise unprocessed, which is supposed to restore the binaural cues of the noise, was included into the calculation of the Wiener filters. Further, it was shown, using an objective cross-correlation measure, that the ITD cues of the noise component were preserved. The BMWF algorithm has also been evaluated perceptually in terms of lateralization performance [14] and SRT improvements [15]. The conclusion in [14] was that correct localization was possible with BMWF processing as long as a small amount of noise was left unprocessed. Regarding the SRT improvements in [15], it was concluded that the performance was as good as or better than that achieved with an adaptive directional microphone (ADM), a standard directional processing often implemented in hearing aids. The algorithm was developed for arbitrary array geometry with no need for any assumptions about the sound source location or microphone positions, and as such it is robust against microphone gain and phase mismatch, as well as deviations in microphone positions and variation of speaker position [11]. It only relies on the second-order statistics of the speech and noise sources, which allows for an estimation of the desired clean speech component. The algorithm relies on a voice activity detection (VAD) mechanism for estimation of the second-order statistics, that is, the algorithm requires another algorithm that detects time instants in the noisy speech signal where the speech is absent. The studies evaluating the BMWF have used an ideal error-free (perfect) VAD which is not available in practice. Generally, VAD algorithms only work well at moderate-to-high SNRs [16]. It is therefore anticipated that the speech enhancement ability of BMWF in those conditions would not be degraded by using a practical VAD instead of a perfect VAD. However, for hearing aid applications, speech enhancement at low SNRs must be considered for two reasons: (1) the SNRs often found in the environment span the range of −10 to 5 dB and should therefore be included in the evaluation of algorithms for hearing aids [17] and (2) the SRT point, at which there is highest potential for improving intelligibility, is often found at negative SNRs.
In this study, it is investigated to what extent the noise reduction performance of the BMWF algorithm is affected by a realistic VAD compared to a perfect VAD. The BMWF is connected to an envelope-based VAD and the combined system's noise reduction performance is assessed for different types of noise and different spatial configurations of noise sources. The evaluation is based on objective measures such as the intelligibility-weighted SNR improvement. The paper is organized as follows. Section 2 provides an overview of the Binaural Multichannel Wiener Filter algorithm and the envelope-based VAD. Sections 3 and 4 describe the evaluation methods and present results with stationary directional noise and nonstationary diffuse noise. The nonstationary noise is derived from recordings in a restaurant to approach a real world situation. Section 5 provides a discussion of the potential use of this type of noise reduction processing in hearing aids based on the results obtained in this study.
2. System Model and Algorithms
2.1. System Model
A binaural hearing aid system is considered throughout the present study. There are two microphones on each hearing aid and it is assumed that the aids are linked, such that all four microphone signals are available to a noise reduction algorithm. The processor provides a noise reduced output at each ear.
It is assumed that the signals at each microphone  , at time
, at time  , consist of a speech (target) signal,
, consist of a speech (target) signal,  , convolved with the impulse response,
, convolved with the impulse response,  , from speech source to microphone, and some additive noise. The additive noise contains both the interfering sound source
, from speech source to microphone, and some additive noise. The additive noise contains both the interfering sound source  , convolved with the room impulse response from the source to microphone,
, convolved with the room impulse response from the source to microphone,  , and the internal sensor noise
, and the internal sensor noise  , as indicated in (1) for the left and right hearing aid, respectively,
, as indicated in (1) for the left and right hearing aid, respectively,

with  representing the microphone number index in the two hearing aids. It is assumed that the noise is uncorrelated with speech and is a short-term stationary zero-mean process.
representing the microphone number index in the two hearing aids. It is assumed that the noise is uncorrelated with speech and is a short-term stationary zero-mean process.
2.2. Binaural Multichannel Wiener Filter
The BMWF algorithm proposed in [13] provides a Minimum Mean Square Error (MMSE) estimate of the speech component in the two front microphones. As depicted in Figure 1, two Wiener filters are computed to estimate the noise components  and
and  in the front left and right microphones, which are then subtracted from the original noisy speech signals
in the front left and right microphones, which are then subtracted from the original noisy speech signals  and
and  to obtain estimates
to obtain estimates  and
and  of the clean speech components.
of the clean speech components.

Structure of the BMWF algorithm. Clean speech components are obtained by computing two Wiener filters that estimate the noise component in the left and right front channels, which are subtracted from the received noisy signals.
Computation of the left and right Wiener filters requires spatiotemporal information about the speech and noise sources in the form of their second-order statistics. Using the received microphone signals, an approximation of the second-order statistics can be obtained from a block of input data of length  . For a filter of length
. For a filter of length  per channel, the input data vector
per channel, the input data vector  for the left front channel is given in (2). Accordingly, input data vectors are defined for the remaining channels. An input data vector
for the left front channel is given in (2). Accordingly, input data vectors are defined for the remaining channels. An input data vector  for all microphone signals is constructed as expressed in (3), which is used for computing the correlation matrices of speech and noise
for all microphone signals is constructed as expressed in (3), which is used for computing the correlation matrices of speech and noise


The speech plus noise correlation matrix  , given in (4), can be calculated directly from the input data vector in (3)
, given in (4), can be calculated directly from the input data vector in (3)

The noise components are not directly available, as they cannot be separated from the mixture of speech and noise in the received microphone signals in (2) and (3). Therefore, they need to be estimated in periods that only contain noise, in order to compute the second-order statistics of the noise. Such an operation requires a voice activity detection (VAD) mechanism to identify the time instants in the received mixture signal that do not contain speech. At these time instants, denoted  , the noise correlation matrix
, the noise correlation matrix  is calculated as expressed in the following:
is calculated as expressed in the following:

As the noise correlation matrix is constructed from  data samples collected at time instants
data samples collected at time instants  , the correlation matrices are scaled such that
, the correlation matrices are scaled such that  and
and  . The left and right Wiener filters
. The left and right Wiener filters  are then calculated as shown in the following:
are then calculated as shown in the following:

Since the speech signal is estimated in the left and right microphone channel, the BMWF processing inherently preserves the ITD cues of the speech component. However, ITD cues of the noise component are distorted [12, 13]. In order to improve localization, some noise is left unprocessed at the output, by incorporating a parameter  into the filter calculation in (6), as shown in (7):
into the filter calculation in (6), as shown in (7):

The noise controlling parameter  can take on values between 0 and 1, where
can take on values between 0 and 1, where  puts all effort on noise reduction with no attempt on preservation of localization cues, and
puts all effort on noise reduction with no attempt on preservation of localization cues, and  puts all effort on preserving localization cues and no noise reduction is performed, that is, there is a trade-off between noise reduction and preservation of localization cues.
puts all effort on preserving localization cues and no noise reduction is performed, that is, there is a trade-off between noise reduction and preservation of localization cues.
The BMWF algorithm uses no information for computation of the filter matrix other than the second-order statistics determined by the VAD. It can be expected that the performance of the BMWF will degrade at some point due to VAD detection errors, leading to incorrect noise estimation. If speech is detected as noise, vectors containing speech samples will be added to the noise data matrix in (5), which leads to cancellation of parts of the speech signal. On the other hand, if too many actual noise samples are detected as speech, less noise vectors are added to the noise data matrix in (5) and a poorer noise estimate is obtained which leads to incorrect noise reduction. Generally, a multichannel Wiener filter can be decomposed into a minimum variance distortionless response MVDR beamformer followed by a (spectral) Wiener postfilter [18]. Therefore, it can also be expected that the speech enhancement strongly depends on the spatial configuration of the noise sources. The adaptive beamformer is mostly effective at suppressing interference comprising fewer sources than the number of microphones, with the noise reduction decreasing fast as the number of noise sources increases. While the beamformer should not modify the target signal, the postfilter can attenuate the target signal, according to the amount of noise present at the output of the beamformer. Hence, as the Wiener postfilter trades off target distortion with noise reduction, the amount of target cancellation is expected to be small in the case of few noise sources, and high for many sources.
2.3. Voice Activity Detector
Speech has strong amplitude modulations in the frequency region of 2–10 Hz, such that its envelope fluctuates over a wide dynamic range. Many types of noise (e.g., traffic or babble noise where signals of many speakers are superimposed) exhibit smaller and more rapid envelope fluctuations compared to speech. These properties can be exploited for detection of time periods in a signal where speech is absent. Therefore, an envelope-based VAD developed for hearing aid applications is used, as proposed in [19]. The algorithm adaptively tracks the dynamics of a signal's power envelope and provides speech pause detection based on the envelope minima in a noisy speech signal. This VAD has been shown to have a low rate of speech periods falsely detected as noise even at low-input SNR of −10 dB [19], which is desirable in order to avoid deteriorations of the speech signals in the noise reduction process. Also, in [19], the VAD was compared to the standardized ITU G.729 VAD by means of receiver operating characteristic (ROC) curves, and was found to outperform it for a representative set of noise types and SNRs. The VAD provides speech/noise classification by analyzing time frames of 8 ms, using the following processing steps for each frame:
-
(1)
A 50% overlap is used such that the processing delay is 4 ms. Each frame is Hanning windowed and a 256-point FFT is performed.
-
(2)
Short-term magnitude-squared spectra were calculated. Temporal power envelopes are obtained by summing up the squared spectral components. Moreover, a low- and high-band power envelope are calculated, by summing up the squared spectral components below a cutoff frequency
 and above
and above  . The envelopes of band-limited signals are considered since some noise types have stronger low- (or high-) frequency components. In that case, one of the band-limited envelopes may be less disturbed by the noise and provide more reliable information for speech pause decision. The envelopes are smoothed slightly using a first-order recursive low-pass filter with a release time constant
. The envelopes of band-limited signals are considered since some noise types have stronger low- (or high-) frequency components. In that case, one of the band-limited envelopes may be less disturbed by the noise and provide more reliable information for speech pause decision. The envelopes are smoothed slightly using a first-order recursive low-pass filter with a release time constant  .
. -
(3)
The maxima and minima of the signal envelope are obtained by tracking the peaks and valleys of the envelope waveform. This is done with two first-order recursive low-pass filters with attack and release time constants
 and
and  . The differences between the maxima and minima are calculated to obtain the current dynamic range of the signal.
. The differences between the maxima and minima are calculated to obtain the current dynamic range of the signal. -
(4)
The decision for a speech pause is based on several requirements regarding the dynamic range of the signal and the current envelope values for the three bands. As the complete decision process is described in [19], it will not be outlined here, that is, only the general concepts are provided. The criterion for the envelope being close enough to its minimum is determined by the free parameters
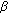 and
and 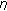 and the current dynamic range of the signal. The threshold parameter
and the current dynamic range of the signal. The threshold parameter 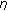 represents the threshold for determining whether the current dynamic range of the signal is low, medium or high. The parameter
represents the threshold for determining whether the current dynamic range of the signal is low, medium or high. The parameter 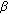 can take on values between 0 and 1 and is used in comparisons of whether a fraction (
can take on values between 0 and 1 and is used in comparisons of whether a fraction (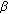 ) of the current dynamic range is higher than the difference between the current envelope and its minimum. The settings of
) of the current dynamic range is higher than the difference between the current envelope and its minimum. The settings of 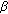 and
and 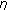 determine how strict the requirements for detecting a speech pause are, and they can be adjusted to make the VAD more or less sensitive to detecting speech pauses. By increasing one or both of the parameters, the algorithm will detect more speech pauses, but at the same time, it will also detect more speech periods as noise.
determine how strict the requirements for detecting a speech pause are, and they can be adjusted to make the VAD more or less sensitive to detecting speech pauses. By increasing one or both of the parameters, the algorithm will detect more speech pauses, but at the same time, it will also detect more speech periods as noise.
 and above
and above  . The envelopes of band-limited signals are considered since some noise types have stronger low- (or high-) frequency components. In that case, one of the band-limited envelopes may be less disturbed by the noise and provide more reliable information for speech pause decision. The envelopes are smoothed slightly using a first-order recursive low-pass filter with a release time constant
. The envelopes of band-limited signals are considered since some noise types have stronger low- (or high-) frequency components. In that case, one of the band-limited envelopes may be less disturbed by the noise and provide more reliable information for speech pause decision. The envelopes are smoothed slightly using a first-order recursive low-pass filter with a release time constant  .
. and
and  . The differences between the maxima and minima are calculated to obtain the current dynamic range of the signal.
. The differences between the maxima and minima are calculated to obtain the current dynamic range of the signal.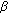 and
and 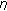 and the current dynamic range of the signal. The threshold parameter
and the current dynamic range of the signal. The threshold parameter 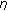 represents the threshold for determining whether the current dynamic range of the signal is low, medium or high. The parameter
represents the threshold for determining whether the current dynamic range of the signal is low, medium or high. The parameter 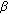 can take on values between 0 and 1 and is used in comparisons of whether a fraction (
can take on values between 0 and 1 and is used in comparisons of whether a fraction (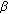 ) of the current dynamic range is higher than the difference between the current envelope and its minimum. The settings of
) of the current dynamic range is higher than the difference between the current envelope and its minimum. The settings of 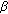 and
and 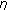 determine how strict the requirements for detecting a speech pause are, and they can be adjusted to make the VAD more or less sensitive to detecting speech pauses. By increasing one or both of the parameters, the algorithm will detect more speech pauses, but at the same time, it will also detect more speech periods as noise.
determine how strict the requirements for detecting a speech pause are, and they can be adjusted to make the VAD more or less sensitive to detecting speech pauses. By increasing one or both of the parameters, the algorithm will detect more speech pauses, but at the same time, it will also detect more speech periods as noise.3. Evaluation Setup
The speech enhancement performance of the system was evaluated for SNRs in the range from −10 to +5 dB, as this range is most important for hearing aid applications (see Section 1). Since the performance of microphone arrays strongly depends on the spatial characteristics of the interfering noise, the system was evaluated both in conditions of directional and diffuse noise. Further, two noise types were considered: a stationary noise with low modulation index and a nonstationary noise with strong envelope fluctuations.
3.1. Performance Measures
The noise reduction performance was evaluated using the intelligibility-weighted SNR improvement,  , defined in [20]. This is a measure of noise reduction that incorporates basic factors related to speech intelligibility in noise. The signals were split into
, defined in [20]. This is a measure of noise reduction that incorporates basic factors related to speech intelligibility in noise. The signals were split into  third octave bands where the SNR (in dB) was calculated for each band
third octave bands where the SNR (in dB) was calculated for each band  , as shown in (8) for the input and output of the noise reduction algorithm, respectively. Here,
, as shown in (8) for the input and output of the noise reduction algorithm, respectively. Here,  represents power spectral density, with the subscripts
represents power spectral density, with the subscripts  and
and  denoting the speech and noise components, respectively. As different frequency bands do not contribute equally to the intelligibility of speech, each band with center frequency
denoting the speech and noise components, respectively. As different frequency bands do not contribute equally to the intelligibility of speech, each band with center frequency  was weighted with a weight
was weighted with a weight  according to its importance for speech intelligibility. The center frequencies and weights are defined in ANSI 1997 [21]. The weighting function has roughly a bandpass characteristic, with a passband of 1–3 kHz. Since the improvement in SNR after processing is of interest,
according to its importance for speech intelligibility. The center frequencies and weights are defined in ANSI 1997 [21]. The weighting function has roughly a bandpass characteristic, with a passband of 1–3 kHz. Since the improvement in SNR after processing is of interest,  was calculated as expressed in (9), where the input SNR was subtracted from the output SNR the following:
was calculated as expressed in (9), where the input SNR was subtracted from the output SNR the following:


Several studies on microphone arrays for hearing aids have found good agreement between the weighted SNR improvement and changes in SRTs for normal-hearing individuals [22, 23]. In [24], a close agreement between the AI weighted directivity index (AI-DI) (in the case of diffuse noise and frontal incidence of target, the  approaches the AI-DI) and SRTs for hearing-impaired listeners was reported. Although it can be expected that an improvement in SNR in the frequency regions important for speech intelligibility should improve speech recognition, this measure is not considered as a substitute for speech intelligibility tests with hearing-impaired listeners.
approaches the AI-DI) and SRTs for hearing-impaired listeners was reported. Although it can be expected that an improvement in SNR in the frequency regions important for speech intelligibility should improve speech recognition, this measure is not considered as a substitute for speech intelligibility tests with hearing-impaired listeners.
Cancellation of speech can occur when the VAD erroneously detects speech periods as noise periods, due to speech samples being added to the noise data correlation matrix in (5). Speech cancellation can also occur due to the BMWF algorithm processing. This effect may not always be reflected in the SNR improvement, since the noise can be reduced accordingly. The speech cancellation (SCINT) was therefore calculated as the ratio of the speech signal output power to speech signal input power, frequency weighted and averaged in dB, similar to the intelligibility-weighted SNR calculation described above

3.2. Reference System
In order to quantify the degradation of the BMWF system performance due to the integration of a realistic VAD mechanism in the noise estimation method, it was necessary to have a reference VAD that performs "perfectly." Ideally, a VAD should detect all the noise samples without cutting parts of speech. The reference VAD sequence was derived by running the implemented envelope-based VAD algorithm on the speech material used for target speech, mixed with a very low-level noise signal (speech-weighted noise at −35 dB SNR) to ensure correct speech/noise classification, as shown in Figure 2. This VAD sequence was used as the reference VAD here and is from now on referred to as "perfect" VAD, while the VAD running on the actual signals is referred to as envelope-based VAD. The noise reduction obtained with BMWF using the perfect VAD can be regarded as the optimum for the considered acoustic scenarios.

Target speech waveform accompanied by the binary sequence representing the perfect VAD. The selected speech pauses are indicated by zeros in the binary sequence.
3.3. Experimental Setup
The measurements of speech and noise were carried out in an acoustically highly damped room. The speech and noise sources were recorded separately on behind the ear (BTE) hearing aids with omnidirectional microphones, mounted on a dummy head which was placed in the center of the room. The speech waveform is shown in Figure 2. The 8 seconds long speech segment is a male speaker on BBC news, where an additional speech pause was added to the waveform in the intervals from 3.5 to 4 seconds and 7.5 to 8 seconds. This was done since there are very few natural speech pauses in the newsreader speech, and because the BMWF relies on presence of speech pauses for noise estimation. It is assumed that, in a more natural conversation, several speech pauses would be present in the waveform. The speech was played through a loudspeaker located at 0° azimuth relative to the dummy head. The stationary noise used was speech-shaped noise, which is a steady noise with the same long-term average spectrum as (typical) speech. The noise was recorded at the House Ear Institute in Los Angeles. In order to generate directional noise, this recording was played through a loudspeaker positioned at an azimuth of 90° relative to the dummy head. The nonstationary noise used was diffuse multitalker babble noise. Further recording were made in a restaurant at 8 different locations. These recordings were played from 8 different loudspeakers located in the corners of the room. This artificial diffuse sound field is assumed to mimic a "cocktail party" situation, and was chosen to assess the performance of BMWF combined with envelope-based VAD in a realistic and challenging acoustical environment.
The sampling frequency was 24.414 Hz and the BMWF filter length per channel was 64. The filters in (7) were calculated using the whole signal. The output speech and noise signals were generated by filtering the clean speech and noise signals separately with the obtained filter coefficients. The input SNRs were calculated using the VAD sequence shown in Figure 2 in order to exclude the noise-only samples indicated by zeros from the calculation.
In order to investigate the combined systems' noise reduction performance, including the effect of the noise controlling parameter  that trades off noise reduction with preservation of ITDs, two different settings of
that trades off noise reduction with preservation of ITDs, two different settings of  were used:
were used:  , corresponding to full effort on noise reduction, and
, corresponding to full effort on noise reduction, and  , corresponding to adding a small amount of unprocessed noise to the output. These values were chosen since it was found in [14] that by passing a small amount of unprocessed noise (
, corresponding to adding a small amount of unprocessed noise to the output. These values were chosen since it was found in [14] that by passing a small amount of unprocessed noise ( ), the localization can be preserved also for the noise component, while
), the localization can be preserved also for the noise component, while  distorts the localization of the noise component but provides more noise reduction. The
distorts the localization of the noise component but provides more noise reduction. The  parameter was kept fixed in all situations, that is, it was assumed that the hearing aid user does not adjust this according to the acoustical situation. The algorithmic parameters for the VAD used in the current implementation were determined empirically in [19] based on tests employing several noise types, speech signals, and input SNRs. However, since these parameters were adjusted to yield a low false alarm rate (which consequently results in a low hit rate), two additional values of
parameter was kept fixed in all situations, that is, it was assumed that the hearing aid user does not adjust this according to the acoustical situation. The algorithmic parameters for the VAD used in the current implementation were determined empirically in [19] based on tests employing several noise types, speech signals, and input SNRs. However, since these parameters were adjusted to yield a low false alarm rate (which consequently results in a low hit rate), two additional values of  were considered here, as an increase in
were considered here, as an increase in  yields a larger speech pause hit rate. This also allowed the investigation of different combinations of speech and noise classification errors. The complete list of VAD parameters is shown in Table 1.
yields a larger speech pause hit rate. This also allowed the investigation of different combinations of speech and noise classification errors. The complete list of VAD parameters is shown in Table 1.
4. Results
4.1. Speech and Noise Classification
In this section, the speech and noise classification performance of the envelope-based VAD for the three settings of  is presented. The percentages of correctly detected samples were calculated for the scenarios described in the experimental setup in Section 3. Hence, the noise reduction and speech cancelation obtained for each scenario in Sections 4.2 and 4.3 can directly be related to this particular classification performance. The correct scores were calculated with respect to the perfect VAD sequence from Figure 2 (Section 3). Note that the length of the entire signal was 8 seconds of which about 2 seconds were noise and so the amount of speech and noise is not equal.
is presented. The percentages of correctly detected samples were calculated for the scenarios described in the experimental setup in Section 3. Hence, the noise reduction and speech cancelation obtained for each scenario in Sections 4.2 and 4.3 can directly be related to this particular classification performance. The correct scores were calculated with respect to the perfect VAD sequence from Figure 2 (Section 3). Note that the length of the entire signal was 8 seconds of which about 2 seconds were noise and so the amount of speech and noise is not equal.
In Figure 3 the percentages of correct scores are shown for the diffuse multitalker babble noise for  (solid curve),
(solid curve),  (dashed curve) and
(dashed curve) and  (dotted curve). The left and right panels show the correct scores for the speech and noise periods, respectively. For
(dotted curve). The left and right panels show the correct scores for the speech and noise periods, respectively. For  , the amount of correctly detected speech samples is at least 95% at all input SNRs. However, only about 15–20% of the actual noise samples are detected as noise. This is partly due to the way the VAD tracks the minima in the envelope, and due to the threshold settings used to obtain a speech pause decision. The multitalker babble noise fluctuates strongly, such that its envelope is rarely as close to its minimum as is required in the algorithm for a speech pause decision. Increasing
, the amount of correctly detected speech samples is at least 95% at all input SNRs. However, only about 15–20% of the actual noise samples are detected as noise. This is partly due to the way the VAD tracks the minima in the envelope, and due to the threshold settings used to obtain a speech pause decision. The multitalker babble noise fluctuates strongly, such that its envelope is rarely as close to its minimum as is required in the algorithm for a speech pause decision. Increasing  improves the classification of noise, which is mostly pronounced at higher SNR, but this comes at the expense of more speech being classified as noise. It should be noted, that some of these errors occur at time instants when the speech signal is weak, and hence may not always be detrimental.
improves the classification of noise, which is mostly pronounced at higher SNR, but this comes at the expense of more speech being classified as noise. It should be noted, that some of these errors occur at time instants when the speech signal is weak, and hence may not always be detrimental.

Percentage of correctly detected samples for diffuse multitalker babble noise as interferer, at different SNR and for β = 0.1, 0.2 and 0.3. (a) Speech period, (b) noise period.
In Figure 4 the percentages of correct scores are shown for the directional speech-shaped noise for  (solid curve),
(solid curve),  (dashed curve) and
(dashed curve) and  (dotted curve). The left and right panels show the correct scores for speech and noise period, respectively. For
(dotted curve). The left and right panels show the correct scores for speech and noise period, respectively. For  , the amount of correctly detected speech samples is at least 85% at all SNRs. Compared to the multitalker babble noise, the speech-shaped noise exhibits smaller fluctuations of the envelope. Thus the VAD demonstrates significantly better detection of the actual noise frames, but also a higher amount of incorrectly classified speech. Increasing
, the amount of correctly detected speech samples is at least 85% at all SNRs. Compared to the multitalker babble noise, the speech-shaped noise exhibits smaller fluctuations of the envelope. Thus the VAD demonstrates significantly better detection of the actual noise frames, but also a higher amount of incorrectly classified speech. Increasing  from 0.1 to 0.2 improves the overall noise classification, with correct scores on the order of 98% down to an input SNR of 0 dB. Below this point, the amount decreases gradually to 64%. Further increase of
from 0.1 to 0.2 improves the overall noise classification, with correct scores on the order of 98% down to an input SNR of 0 dB. Below this point, the amount decreases gradually to 64%. Further increase of  to 0.3 only slightly improves the noise classification, but each increase in
to 0.3 only slightly improves the noise classification, but each increase in  results in an increased error in speech classification.
results in an increased error in speech classification.

Percentage of correctly detected samples for directional speech-shaped noise as interferer, at different SNR and for β = 0.1, 0.2 and 0.3. (a) Speech period, (b) noise period.
4.2. Stationary Directional Noise
Figure 5 shows the intelligibility-weighted SNR improvement  for stationary directional noise when the perfect VAD is used for the noise estimation (solid curve), and when the envelope-based VAD is used with
for stationary directional noise when the perfect VAD is used for the noise estimation (solid curve), and when the envelope-based VAD is used with  (dashed curve),
(dashed curve),  (dotted curve), and
(dotted curve), and  (solid curve with cross markers). The left panel and right panel show the results for
(solid curve with cross markers). The left panel and right panel show the results for  and
and  , respectively. For
, respectively. For  and
and  , the noise reduction performance does not degrade due to VAD down to an input SNR of 0 dB, where an improvement of about 20 dB SNR is obtained. This can be related to the speech and noise classification shown in Figure 4, as a high amount of noise is correctly detected for the two
, the noise reduction performance does not degrade due to VAD down to an input SNR of 0 dB, where an improvement of about 20 dB SNR is obtained. This can be related to the speech and noise classification shown in Figure 4, as a high amount of noise is correctly detected for the two  settings down to an input SNR of 0 dB. In this condition, the setting
settings down to an input SNR of 0 dB. In this condition, the setting  yields less improvement, which is also consistent with the 15–30% lower detection rate for noise observed in Figure 4. In this context, the increased misclassification of speech due to increasing
yields less improvement, which is also consistent with the 15–30% lower detection rate for noise observed in Figure 4. In this context, the increased misclassification of speech due to increasing  does not have a negative impact on noise reduction performance. Below an input SNR of 0 dB, the noise suppression gradually decreases for all
does not have a negative impact on noise reduction performance. Below an input SNR of 0 dB, the noise suppression gradually decreases for all  settings, and eventually amounts to roughly 15 dB at an input SNR of −10 dB.
settings, and eventually amounts to roughly 15 dB at an input SNR of −10 dB.

Intelligibility weighted SNR improvement for directional speech-shaped noise at different SNRs for perfect VAD and envelope-based VAD with β = 0.1, 0.2 and 0.3. (a) λ = 1 and (b) λ = 0.8 .
The right panel of Figure 5 shows that reducing  from 1 to 0.8 (to preserve ITD cues of the noise component) leads to SNR improvement of about 13 dB for all considered SNR conditions when utilizing perfect VAD. This is substantially less than the 20 dB obtained with the
from 1 to 0.8 (to preserve ITD cues of the noise component) leads to SNR improvement of about 13 dB for all considered SNR conditions when utilizing perfect VAD. This is substantially less than the 20 dB obtained with the  setting. However the degradation of noise reduction performance due to employing envelope-based VAD is smaller when the noise estimate is scaled, such that an average gain of 10 dB is found.
setting. However the degradation of noise reduction performance due to employing envelope-based VAD is smaller when the noise estimate is scaled, such that an average gain of 10 dB is found.
Figure 6 shows the intelligibility-weighted speech cancellation SCINT for the same conditions as for the  in Figure 5. (note that a smaller number indicates higher target cancelation) The SCINT ranges from 0.2 to 1 dB when the perfect VAD is employed. When envelope-based VAD is employed, the SCINT increases, with higher
in Figure 5. (note that a smaller number indicates higher target cancelation) The SCINT ranges from 0.2 to 1 dB when the perfect VAD is employed. When envelope-based VAD is employed, the SCINT increases, with higher  resulting in increased cancellation, as more speech is classified as noise. This increase is modest at higher input SNR but becomes progressively greater at lower SNR.
resulting in increased cancellation, as more speech is classified as noise. This increase is modest at higher input SNR but becomes progressively greater at lower SNR.

Intelligibility weighted speech cancelation for directional speech-shaped noise at different SNRs for perfect VAD and envelope-based VAD with β = 0.1, 0.2 and 0.3. (a) λ = 1 and (b) λ = 0.8 ..
Results in the right panel of Figure 6 show that setting  reduces the amount of target cancellation by up to 1.5 dB.
reduces the amount of target cancellation by up to 1.5 dB.
4.3. Diffuse and Fluctuating Noise
Figure 7 shows the intelligibility-weighted SNR improvement for a diffuse multitalker babble scenario with the same conditions as for stationary noise (Section 4.2). The noise suppression is around 6 dB with a slight decline below-input SNR of −5 dB when the perfect VAD is employed. Using the envelope-based VAD does not result in large degradations (<1 dB) down to an input SNR of −5 dB, at least for the  setting (this
setting (this  value yields the highest noise reduction). Below −5 dB, the noise reduction degrades gradually to about 3 dB at −10 dB.
value yields the highest noise reduction). Below −5 dB, the noise reduction degrades gradually to about 3 dB at −10 dB.

Intelligibility weighted SNR improvement for diffuse multitalker babble noise at different SNRs for perfect VAD and envelope-based VAD with β = 0.1, 0.2 and 0.3. (a) λ = 1 and (b) λ = 0.8 .
The detection rates for noise displayed in Figure 3 show that, as the input SNR decreases, the VAD classifies a higher amount of noise as speech. But this is not the only reason for reduced performance. Figure 3 shows that the VAD detection rates are quite similar at and below −5 dB input SNR, yet the SNR improvement decreases. The noise reduction performance does not only depend on the VAD error rates, but also on the quality of the noise estimate and this is especially pronounced at very low SNRs in nonstationary noise. The noncontinuous collection of noise data introduces inaccuracies in the noise correlation matrix since it is estimated only in limited periods of time in the entire signal waveform. Thus, the filter coefficients differ from those that could have been obtained if the speech and noise correlation matrices were estimated at the same time. While the improvement for directional speech-shaped noise in Figure 5 actually increases with decreasing SNR when employing a perfect VAD, this is not the case for diffuse babble noise (Figure 7), where a 1 dB decrease is seen. Therefore, frequent sampling of the fluctuating noise is even more important at lower SNRs.
The right panel of Figure 7 shows that a setting  in diffuse noise results only in a very small decrease in SNR improvement (on average 1 dB).
in diffuse noise results only in a very small decrease in SNR improvement (on average 1 dB).
The target cancelation for the multitalker babble interferer is shown in Figure 8. Most of the target cancellation occurs due to the BMWF processing, which ranges from 1.5 to 7 dB depending on the input SNR. Since the noise is diffuse, the data-dependent spatial filter is not as effective as in the case of a few noise sources, and consequently the spectrum-dependent postfilter attenuates the signal in the effort to reduce the considerable amount of residual noise at the output of the spatial filter. The additional target cancelation due to VAD errors is around 3 dB at most and in some cases the SCINT is actually lower than that obtained with the perfect VAD. Thus the amount of cancellation for diffuse babble noise due to VAD errors is limited. The right panel of Figure 8 shows that scaling the noise estimate by setting  reduces the target cancelation by up to 2.5 dB.
reduces the target cancelation by up to 2.5 dB.

Intelligibility weighted speech cancellation for diffuse multitalker babble noise at different SNRs for perfect VAD and envelope-based VAD with β = 0.1, 0.2 and 0.3. (a) λ = 1 and (b) λ = 0.8 .
5. Discussion
The noise reduction results showed that for stationary directional noise an average SNR improvement of 20 dB (see left panel of Figure 5) can be achieved when using perfect VAD for noise estimation in the BMWF system. The effect of incorporating a realistic VAD for this scenario is minimal (<1 dB) as long as the input SNR is at or above 0 dB. Although noise reduction performance deteriorated with decreasing SNR, a robust gain of about 15 dB is still obtained at −10 dB input SNR. When trading off some noise reduction in order to preserve ITD cues of the noise component (i.e., setting  , shown in right panel of Figure 5), an adequate improvement in SNR of 10 dB on average can still be obtained. This means that in such a situation, the user could, in addition to the benefit from auditory release from masking (that also improves speech intelligibility), also benefit from the microphone array processing. While an adequate amount of noise reduction can be obtained for the case of stationary directional interferer, the noise recorded in a restaurant is a more realistic condition that often would be encountered by hearing aid users. In this scenario, a limited amount of noise reduction of about 6 dB was obtained by the BMWF system in the optimal case (i.e., with perfect VAD), as can be seen in Figure 7. Furthermore, the setting
, shown in right panel of Figure 5), an adequate improvement in SNR of 10 dB on average can still be obtained. This means that in such a situation, the user could, in addition to the benefit from auditory release from masking (that also improves speech intelligibility), also benefit from the microphone array processing. While an adequate amount of noise reduction can be obtained for the case of stationary directional interferer, the noise recorded in a restaurant is a more realistic condition that often would be encountered by hearing aid users. In this scenario, a limited amount of noise reduction of about 6 dB was obtained by the BMWF system in the optimal case (i.e., with perfect VAD), as can be seen in Figure 7. Furthermore, the setting  reduced the SNR improvement by 1 dB. It could be argued that this reduction is not necessary since in a diffuse noise environment no directional localization cues for the noise are available. In the present study, it was assumed that the hearing aid user does not adjust the
reduced the SNR improvement by 1 dB. It could be argued that this reduction is not necessary since in a diffuse noise environment no directional localization cues for the noise are available. In the present study, it was assumed that the hearing aid user does not adjust the  setting according to the acoustical environment, but in principle it should be possible that this adjustment is made in the hearing aid according to the acoustical environment with the sound classifiers installed in modern hearing aids.
setting according to the acoustical environment, but in principle it should be possible that this adjustment is made in the hearing aid according to the acoustical environment with the sound classifiers installed in modern hearing aids.
When using the envelope-based VAD, the performance is not degraded by more than 1 dB down to an input SNR of about −5 dB compared to the optimal case. At this point (for  ), the correct classification of speech was about 78% and the correct classification of noise was about 50% (see Figure 3). Thus, it is not necessary for the BMWF system that the VAD shows satisfactory performance (i.e., a low error rate), but rather that the error rate is not excessive (e.g., higher than 50%), and therefore only small effects of VAD are observed in relatively adverse conditions. It should be noted, that even a small weighted SNR improvement of 3–6 dB found for diffuse babble noise can lead to a crucial speech recognition increase, if the improvement is found at SNRs comparable to the SRT. In [25], for example, sentence intelligibility in different types of noise for hearing-impaired listeners was investigated. The average SRTs for speech-shaped noise and fluctuating noise were −3.3 dB and −2.1 dB, respectively, with improvements in speech recognition of 16 and 11 percent for each 1 dB increase in SNR. This means that for a typical hearing-impaired individual the SNR range of understanding almost nothing to understanding almost everything is −7 to 3 dB for sentences in fluctuating noise. In much of this SNR range (down to −5 dB), the BMWF performance does not degrade much due to VAD errors and an SNR improvement of 5-6 dB is found. Hence, the BMWF with envelope-based VAD might provide a significant improvement in speech recognition of more than 50%.
), the correct classification of speech was about 78% and the correct classification of noise was about 50% (see Figure 3). Thus, it is not necessary for the BMWF system that the VAD shows satisfactory performance (i.e., a low error rate), but rather that the error rate is not excessive (e.g., higher than 50%), and therefore only small effects of VAD are observed in relatively adverse conditions. It should be noted, that even a small weighted SNR improvement of 3–6 dB found for diffuse babble noise can lead to a crucial speech recognition increase, if the improvement is found at SNRs comparable to the SRT. In [25], for example, sentence intelligibility in different types of noise for hearing-impaired listeners was investigated. The average SRTs for speech-shaped noise and fluctuating noise were −3.3 dB and −2.1 dB, respectively, with improvements in speech recognition of 16 and 11 percent for each 1 dB increase in SNR. This means that for a typical hearing-impaired individual the SNR range of understanding almost nothing to understanding almost everything is −7 to 3 dB for sentences in fluctuating noise. In much of this SNR range (down to −5 dB), the BMWF performance does not degrade much due to VAD errors and an SNR improvement of 5-6 dB is found. Hence, the BMWF with envelope-based VAD might provide a significant improvement in speech recognition of more than 50%.
In very adverse conditions, for example, at −10 dB SNR, which may also be encountered in the environment, the SNR improvement reduced to about 3 dB when using envelope-based VAD for noise estimation, which is comparable to that of a directional microphone. A first-order directional microphone, consisting of two closely spaced microphones has an AI weighted directivity index as measured on KEMAR (which is equivalent to our measure of weighted SNR improvement in diffuse noise) of around 3 dB, for example, [5, 26]. It should be kept in mind that the results regarding reduction in SNR improvement relative to that obtained when employing perfect VAD are limited to the specific VAD used here. The effect of other types of VAD algorithms may be different. In addition to the degraded performance in very adverse conditions, an obvious problem for this system arises if the interference is a single speaker or only a few speakers. In such situations, the temporal fluctuations of the noise interferer are very similar to the target fluctuations and thus, the VAD cannot discriminate between both. In consequence, no significant suppression of the interferers can be achieved.
The purpose of this work was primarily to investigate the effect of a realistic VAD on BMWF, more specifically, to identify the range of SNRs where the VAD has minimal effect on noise reduction performance compared to the case when VAD errors are not taken into account, and to quantify the degradation in performance for the conditions where the VAD has significant influence. The following aspects can be subject to further research. The analysis presented has employed block processing where the statistics of speech and noise were calculated using the entire signal of 8 seconds of which about 2 seconds were noise. It is likely that head movement and movement of noise sources will degrade algorithm performance. In this context, the performance of the algorithm will not only be influenced by the type of adaptation used, but by the filters only being updated during speech pauses. Obviously, this impedes tracking of fast movement, as the filters can be frozen for seconds to the previous scenario. Also, VAD classification errors can lead to slower convergence of the filters. Due to the directional properties of the BMWF, this degradation is more likely to be significant in a simple (directional) noise source setup than if the noise scenario is complex that is, spatially diffuse.
Although it can be expected that an SNR improvement in frequency regions important for speech recognition would result in higher speech recognition, the gains obtained in intelligibility-weighted SNR can only be related to the potential of this system to improve intelligibility. This is particularly critical when individual hearing impairments (e.g., limitation in audibility, spectral resolution, or temporal fine structure processing) are considered. The effect of hearing impairment on speech intelligibility might be addressed by using modifications to the speech-weighted SNR measure such as those proposed in, for example, [27] for the Articulation Index. However, in order to demonstrate the true benefit of the BMWF system in complex scenarios, speech intelligibility tests with hearing aid users need to be conducted. Also, the quality of the processed speech could be addressed.
References
Moore BCJ: Speech processing for the hearing-impaired: successes, failures, and implications for speech mechanisms. Speech Communication 2003, 41(1):81-91. 10.1016/S0167-6393(02)00095-X
Festen JM, Plomp R: Effects of fluctuating noise and interfering speech on the speech-reception threshold for impaired and normal hearing. Journal of the Acoustical Society of America 1990, 88(4):1725-1736. 10.1121/1.400247
Plomp R: Auditory handicap of hearing impairment and the limited benefit of hearing aids. Journal of the Acoustical Society of America 1978, 63(2):533-549. 10.1121/1.381753
Nilsson M, Soli SD, Sullivan JA: Development of the hearing in noise test for the measurement of speech reception thresholds in quiet and in noise. Journal of the Acoustical Society of America 1994, 95(2):1085-1099. 10.1121/1.408469
Kates JM: Digital Hearing Aids. Plural Publishing, San Diego, Calif, USA; 2008.
Bitzer J, Simmer KU, Kammeyer K: Theoretical noise reduction limits of the generalized sidelobe canceller (GSC) for speech enhancement. Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '99), March 1999 2965-2968.
Van Den Bogaert T, Klasen TJ, Moonen M, Van Deun L, Wouters J: Horizontal localization with bilateral hearing aids: without is better than with. Journal of the Acoustical Society of America 2006, 119(1):515-526. 10.1121/1.2139653
Klasen TJ, Rohrseitz K, Keidsler G: The effect of multi-channel wide dynamic range compression, noise reduction, and the directional microphone on horizontal localization performance in hearing aid wearers. International Journal of Audiology 2006, 45: 563-579. 10.1080/14992020600920804
Bronkhorst AW, Plomp R: Binaural speech intelligibility in noise for hearing-impaired listeners. Journal of the Acoustical Society of America 1989, 86(4):1374-1383. 10.1121/1.398697
Klasen TJ, Moonen M, Van Den Bogaert T, Wouters J: Preservation of interaural time delay for binaural hearing aids through multi-channel Wiener filtering based noise reduction. Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP '05), 2005 3: 29-32.
Doclo S, Moonen M: GSVD-based optimal filtering for single and multimicrophone speech enhancement. IEEE Transactions on Signal Processing 2002, 50(9):2230-2244. 10.1109/TSP.2002.801937
Cornelis B, Doclo S, Van den Bogaert T, Wouters J, Moonen M: Theoretical analysis of binaural multi-microphone noise reduction techinques. IEEE Transactions on Audio, Speech and Language Processing 2010, 18(2):342-355.
Klasen TJ, Van den Bogaert T, Moonen M, Wouters J: Binaural noise reduction algorithms for hearing aids that preserve interaural time delay cues. IEEE Transactions on Signal Processing 2007, 55(4):1579-1585.
Van Den Bogaert T, Doclo S, Wouters J, Moonen M: The effect of multimicrophone noise reduction systems on sound source localization by users of binaural hearing aids. Journal of the Acoustical Society of America 2008, 124(1):484-497. 10.1121/1.2931962
Van Den Bogaert T, Doclo S, Wouters J, Moonen M: Speech enhancement with multichannel Wiener filter techniques in multimicrophone binaural hearing aids. Journal of the Acoustical Society of America 2009, 125(1):360-371. 10.1121/1.3023069
Vary P, Martin R: Digital Speech Transmission—Enhancement, Coding and Error Concealment: Chapter 11. John Wiley & Sons, New York, NY, USA; 2006.
Ricketts TA: Directional hearing aids: then and now. Journal of Rehabilitation Research and Development 2005, 42(4, supplement 2):133-144.
Brandstein M, Ward D: Microphone Arrays—Signal Processing Techniques and Applications: Chapter 3. Springer, New York, NY, USA; 2001.
Marzinzik M, Kollmeier B: Speech pause detection for noise spectrum estimation by tracking power envelope dynamics. IEEE Transactions on Speech and Audio Processing 2002, 10(2):109-118. 10.1109/89.985548
Greenberg JE, Peterson PM, Zurek PM: Intelligibility-weighted measures of speech-to-interference ratio and speech system performance. Journal of the Acoustical Society of America 1993, 94(5):3009-3010. 10.1121/1.407334
ANSI S3.5-1997 : American National Standard Methods for Calculation of the Speech Intelligibility Index. The Acoustical Society of America, 1997
Peterson PM, Wei S-M, Rabinowitz WM, Zurek PM: Robustness of an adaptive beamforming method for hearing aids. Acta Oto-Laryngologica 1990, (469, supplement):85-90.
Hoffman MW, Trine TD, Buckley KM, Van Tasell DJ: Robust adaptive microphone array processing for hearing aids: realistic speech enhancement. Journal of the Acoustical Society of America 1994, 96(2):759-770. 10.1121/1.410313
Laugesen S, Schmidtke T: Improving on the speech-in-noise problem with wireless array technology. News from Oticon 2004, 3-23.
Wagener KC, Brand T: Sentence Intelligibility in noise for listeners with normal hearing and hearing impairment: influence of measurement procedures and masking parameters. International Journal of Audiology 2005, 44(3):144-156. 10.1080/14992020500057517
Harnacher V, Chalupper J, Eggers J, Fischer E, Kornagel U, Puder H, Rass U: Signal processing in high-end hearing aids: state of the art, challenges, and future trends. Eurasip Journal on Applied Signal Processing 2005, 2005(18):2915-2929. 10.1155/ASP.2005.2915
Pavlovic CV, Studebaker GA, Sherbecoe RL: An articulation index based procedure for predicting the speech recognition performance of hearing-impaired individuals. Journal of the Acoustical Society of America 1986, 80(1):50-57. 10.1121/1.394082
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Catic, J., Dau, T., Buchholz, J. et al. The Effect of a Voice Activity Detector on the Speech Enhancement Performance of the Binaural Multichannel Wiener Filter. J AUDIO SPEECH MUSIC PROC. 2010, 840294 (2010). https://doi.org/10.1155/2010/840294
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1155/2010/840294