- Research Article
- Open access
- Published:
Development of the Database for Environmental Sound Research and Application (DESRA): Design, Functionality, and Retrieval Considerations
EURASIP Journal on Audio, Speech, and Music Processing volume 2010, Article number: 654914 (2010)
Abstract
Theoretical and applied environmental sounds research is gaining prominence but progress has been hampered by the lack of a comprehensive, high quality, accessible database of environmental sounds. An ongoing project to develop such a resource is described, which is based upon experimental evidence as to the way we listen to sounds in the world. The database will include a large number of sounds produced by different sound sources, with a thorough background for each sound file, including experimentally obtained perceptual data. In this way DESRA can contain a wide variety of acoustic, contextual, semantic, and behavioral information related to an individual sound. It will be accessible on the Internet and will be useful to researchers, engineers, sound designers, and musicians.
1. Introduction
Environmental sounds are gaining prominence in theoretical and applied research that crosses boundaries of different fields. As a class of sounds, environmental sounds are worth studying because of their ability to convey semantic information based on complex acoustic structure. Yet, unlike other large meaningful sound classes, that is, speech and music, the information conveyed by environmental sounds is not linguistic, as in speech, and typically is not designed for its aesthetic value alone, as in music (e.g., [1, 2]). There are numerous practical and specific applications for environmental sounds, which include auditory rehabilitation for hearing aid users and cochlear implants recipients; nonlinguistic diagnostic tools for assessing auditory and cognitive deficits in prelinguistic children; noise control and design of acoustic environments; auditory icons in computer displays; sonification, the process of representing information with nonspeech sounds (see [3] for a recent review). However, the knowledge base still lags far behind that of the other major classes of naturally occurring everyday sounds, speech, and music. One of the major hurdles is the lack of a standardized database of readily available, free, tested, high quality, identifiable environmental sounds for users to work with. There are various resources for accessing environmental sounds, some of which were detailed in [4]; however, that paper noted several caveats for users who are looking for sounds on their own. Among them were redundancy in time and effort needed to find the necessary information (which may have been found by others before), and the possibility of idiosyncrasies or occasional unwanted "surprises" (e.g., clipping or artifacts) in otherwise suitable stimuli. To correct those may require the user to have sufficient expertise in several technical areas such as digital signal processing and recording techniques, which may not, in and of themselves, have any relevance to the goals of the intended project.
To remedy this, this paper relates some findings of an ongoing project on the part of the authors assisted by James Beller, programmer, the Database for Environmental Sound Research and Application (DESRA—website: http://www.desra.org/) which aims to collect, label, edit when necessary, norm, evaluate, and make available a large collection of environmental sounds comprising multiple tokens (exemplars) of a wide variety of common sound sources. The collection of sounds and development of the Web front end are ongoing. This paper will describe the structure and function of the database, which reflects and responds to the complex ways in which we think about and use environmental sounds.
2. Defining Environmental Sounds
In order to optimally design a useful multipurpose database for environmental sounds, it is necessary to have a fuller understanding of the nature of environmental sounds, what they represent for humans, factors in environmental sound perception, and how their perception may be similar or different for different listeners. This information will guide sound selection by database users: researchers, designers, and musicians. The ability to use experimentally obtained perceptual criteria in sound selection, in addition to a thorough description of technical characteristics of the sounds, constitutes a unique feature of the present database. Although what Gaver termed "everyday listening" [5] is a frequent activity, the nature of the experience has been remarkably underscrutinized, both in common discourse and in the scientific literature, and alternative definitions exist [6, 7]. This is changing, as the numerous articles in this volume will attest, but still even our basic understanding of environmental sounds has large lacunae.
Thus, unlike speech and music, there is no generally agreed upon formal structure or taxonomy for environmental sounds. Instead, there are several prominent approaches to environmental sound classification that have been advanced over the last several decades [5–7]. A major initial contribution to environmental sound research is contained within the framework of Acoustic Ecology advanced by Schafer [6] who advanced the notion of the soundscape as the totality of all sounds in the listener's dynamic environment. Further extended by Truax [7] in his Acoustic Communication model, speech, music, and soundscape (that includes all other sounds in the environment) are treated as part of the same acoustic communication continuum wherein sounds' acoustic variety increases from speech to soundscape, while sounds' rule-governed perceptual structure, temporal density of information, and specificity of meaning all increase from soundscapes to speech. Importantly, the Acoustic Communication approach also treats listening as an active process of interacting with one's environment and distinguishes among several different levels of listening such as listening-in-search (when specific acoustic cues are being actively sought in the sensory input), listening-in-readiness (when the listener is ready to respond to specific acoustic cues if they appear but is not actively focusing his/her attention on finding them), and background listening (when listeners are not expecting significant information or otherwise actively processing background sounds). The theoretical constructs of the Acoustic Communication model are intuitive and appealing and have been practically useful in the design of functional and aesthetically stimulating acoustic environments [8]. However, directed mostly toward more general aspects of acoustic dynamics of listener/environment interactions, as regards cultural, historical, industrial, and political factors and changes at the societal level, it is still the case that more specific perceptual models are needed to investigate the perception of environmental sounds in one's environment.
In his seminal piece, What Do We Hear in the World [5], Gaver attempted to construct a descriptive framework based on what we listen for in everyday sounds. He examined previous efforts, such as libraries of sound effects on CD, which were largely grouped by the context in which the sound would appear, for example, "Household sounds" or "Industry sounds." While this would be useful for people who are making movies or other entertainment, he found it not very useful for a general framework. "For instance, the categories are not mutually exclusive; it is easy to imagine hearing the same event (e.g., a telephone ringing) in an office and a kitchen. Nor do the category names constrain the kinds of sounds very much."
Instead, he looked at experimental results by himself and others [9–12] which suggested in everyday listening that we tend to focus on the sources of sounds, rather than acoustic properties or context. He reasoned that in a hierarchical framework, "Superordinate categories based on types of events(as opposed to contexts) provide useful clues about the sorts of sounds that might be subordinate, while features and dimensions are a useful way of describing the differences among members of a particular category." Inspired by the ecological approach of Gibson [13], he drew a sharp distinction between "musical listening", which is focusing on the attributes of the "sound itself", and "everyday listening" in which " the perceptual dimensions and attributes of concern correspond to those of the sound-producing event and its environment, not to those of the sound itself."
the perceptual dimensions and attributes of concern correspond to those of the sound-producing event and its environment, not to those of the sound itself."
Based on the physics of sound-producing events, and listeners' description of sounds, Gaver proposed a hierarchical description of basic "sonic events," such as impacts, aerodynamic events and liquid sounds, which is partially diagrammed in Figure 1. From these basic level events, more complex sound sources are formed, such as patterned sources (repetition of a basic event), complex sources (more than one sort of basic level event), and hybrid sources (involving more than one basic sort of material).

Hierarchy of sound producing events adapted from Gaver [ 5 ].
Gaver's taxonomy is well thought out, plausible, and fairly comprehensive, in that it includes a wide range of naturally occurring sounds. Naturally there are some that are excluded—the author himself mentions electrical sounds, fire and speech. In addition, since the verbal descriptions were culled from a limited sample of listener responses, one must be tentative in generalizing them to a wider range of sounds. Nevertheless, as a first pass it is a notable effort at providing an overall structure to the myriad of different environmental sounds.
Gaver provided very limited experimental evidence for this hierarchy. However, a number of experiments both previous and subsequent have supported or been consistent with this structuring [12, 14–18] although some modifications have been proposed, such as including vocalizations as a basic category (which Gaver himself considered). It was suggested in [16] that although determining the source of a sound is important, the goal of the auditory system is to enable an appropriate response to the source, which would also necessarily include extracting details of the source such as the size and proximity and contextual factors that would mitigate such a response. Free categorization results of environmental sounds from [16] showed that the most common basis for grouping sounds was on source properties, followed by common context, followed by simple acoustic features, such as Pitched or Rumbling and emotional responses (e.g., Startling/Annoying and Alerting). Evidence was provided in [19] that auditory cognition is better described by the actions involved from a sound emitting source, such as "dripping" or "bouncing", than by properties of their causal objects, such as "wood" or "hollow". A large, freely accessible database of newly recorded environmental sounds has been designed around these principles, containing numerous variations on basic auditory events (such as impacts or rolling), which is available at http://www.auditorylab.org/.
As a result, the atomic, basic level entry for the present database will be the source of the sound. In keeping with the definition provided earlier, the source will be considered to be the objects involved in a sound-producing event with enough description of the event to disambiguate the sound. For instance, if the source is described as a cat, it is necessary to include "mewing", "purring", or "hissing" to provide a more exact description. There are several potential ways to describe the source, from physical objects to perceptual and semantic categories. Although the present definition does not allow for complete specificity, it does strike a balance between that and brevity and allows for sufficient generalization that imprecise searches can still recover the essential entries.
Of course sounds are almost never presented in isolation but in an auditory scene in which temporally linear mixtures of sounds enter the ear canal and are parsed by the listener. Many researchers have studied the regularities of sound sources that can be exploited by listeners to separate out sounds, such as common onsets, coherent frequency transitions, and several other aspects (see, e.g., [20]). The inverse process, integration of several disparate sources into a coherent "scene", has been much less studied, as has the effect of auditory scenes on perception of individual sounds [21–23]. As a result, the database will also contain auditory scenes, which consist of numerous sound sources bound together by a common temporal and spatial context (i.e., recorded simultaneously). Some examples are a street scene in a large city, a market, a restaurant or a forest. For scenes, the context is the atomic unit for the description.
Above these basic levels, multiple hierarchies can be constructed, based on the needs and desires of the users, which are detailed in the next section.
3. Projected Users of the Database
The structure and functionality of the database are driven by the users and their needs. The expected users of this database are described below.
3.1. Researchers
This is the largest expected group of users. Based on environmental sound research conducted in the past several decades, there are several common criteria in selecting sounds suitable for research. One of their main concerns has been how identifiable or familiar a sound is, since as noted above, identification of the source of a sound is the primary goal of the auditory system with respect to environmental sounds. Other researchers might also want to know acoustic attributes of sounds, such as the amount of high frequency information, the duration, and the temporal structure if they are undertaking studies in filtering environmental sounds (e.g., [2]) or looking at the role of temporal cues [1]. Many researchers have investigated semantic attributes of sounds, such as "harshness" or "complexity" (see Section 4 below for citations), or broader sound categories which can also be included, either from pre-existing data, if an associate (described below) has such data on that particular sound, or by aggregating ratings submitted on the website (see Section 8.4 below). Other researchers might be interested in emotional aspects of sounds, such as "pleasant", or "chilling" [24]. Some more psychoacoustically oriented researchers would like several tokens of the same sound source that vary in only specific aspects, such as a ball bouncing on wood, on metal, or on plastic, or a hammer striking a large plate versus a small plate [25–27]. Finally, a citation history, listing studies which have employed this particular sound, would be very useful for cross-study comparisons.
3.2. Sound Designers
Aside from the source of the sound, sound designers may also want some metadata such as details of the recording: the location, the time, the distance of the microphone from the source, and the recording level. If they are planning to use it in a film or video, it would be useful for them to know what settings a sound would be appropriate for, for example, if a dog barking would seem out of place in an office. Such searches will be helped by recording background data as well as perceptual ratings data on sound congruency for different auditory scenes [28].
3.3. Musicians and Game Designers
There is also a large number of people who are looking for sounds to use as musical samples for songs or games. There are sites already geared towards these users, such as freesound.org and soundsnap.com. These sites and some of their limitations are described below. In addition to the above information, they might also like to know how musical a sound is (which is related to harmonic structure) or how rhythmic a sound is, which can be based on acoustic analyses.
4. Sources of Information
-
(a)
As mentioned above, a central concern for many researchers will be how identifiable a sound is, while others may be interested in typical or atypical sound tokens. Thus, the database should designate which sounds are "easily identifiable", "very familiar", or "highly typical." These classifications will be based on empirical data where it exists [1, 2, 18]. Researchers who have gathered such data on these will be encouraged to submit it. In addition, the site will have results of online identification experiments which the users will be encouraged to participate in (see below), and those results will be made available to users. Users will also want to know whether the clip is of a sound in isolation or of a scene. A coding scheme will be used where 1
 single source in isolation, 2
single source in isolation, 2  scene with many sources. This judgment will be made at the time of submission and cross-checked for accuracy by the maintainers of the site.
scene with many sources. This judgment will be made at the time of submission and cross-checked for accuracy by the maintainers of the site. -
(b)
Waveform statistics: file format, file size, sampling rate, quantization depth, duration, number of channels, dc offset, number of clipped samples, rms (in dB), and peak (in dB). Most users would want to know such details of the recording as the location, the time, the distance of the microphone from the source, and the recording level. This information will need to be entered by the associate submitting the sound, and everyone submitting a sound will be encouraged to supply these data.
-
(c)
Contextual information, such as whether the sound is occurring outdoors or indoors, in a large space or a small space, or in an urban or rural setting. Again, a good deal of this information is recoverable from the acoustics (from reverberation or from higher order acoustic features [29]), but if the precise data are known, they should be included in the database.
-
(d)
Qualitative aspects: in addition to properties of the source, sounds elicit semantic associations for listeners. Some sounds can be chilling, some sounds are considered pleasant, and some sounds are judged to be tense. Several studies have investigated these qualities using the semantic differential method [30–33] introduced by Osgood [34] (described below) and then tried to correlate those qualities with various acoustic features of the sounds. Some consistent results have emerged. For instance, perceived size is reliably associated with loudness [24], low frequencies with heaviness [24], tenseness correlates with an energy peak around 2500 Hz [35], and pleasant sounds tend to lack harmonics [30]. In perhaps the most comprehensive study [31], ratings of 145 environmental sounds were obtained representing various categories of naturally occurring environmental sounds (e.g., impact sounds, water sounds, ambient sounds) on 20 7-point bipolar scales. A principal components analysis of the rating data showed that the judgments of the listeners could be associated with four dimensions, accounting for 89% of the variance. The four dimensions roughly corresponded (in descending order of
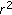 ) to "harshness", "complexity", "size", and "appeal". Since it is anticipated that some users will be interested in the semantic attributes of sounds, the four attributes mentioned in [31] as well as "tenseness" will be included as part of a sound's entry. If the values on those dimensions are known (i.e., have been established by previous research), they will be included. Otherwise users of the system will have an opportunity to rate these sounds, as described below.
) to "harshness", "complexity", "size", and "appeal". Since it is anticipated that some users will be interested in the semantic attributes of sounds, the four attributes mentioned in [31] as well as "tenseness" will be included as part of a sound's entry. If the values on those dimensions are known (i.e., have been established by previous research), they will be included. Otherwise users of the system will have an opportunity to rate these sounds, as described below.There are some qualitative features of sounds that can be calculated directly from the waveforms, such as roughness (as defined in [36]), sharpness [37], and loudness (ANSI loudness) if the recording level SPL is known. The appropriate algorithms for calculating these values will be applied to sounds as they are entered into the database and the resulting values attached to the sounds as part of a sound's entry.
-
(e)
Musical features: some users of the database may be musicians looking for sounds to use in musical compositions and would be concerned with how the sounds will fit in both harmonically and rhythmically. Therefore acoustic variables will be included for both aspects of the sounds.
 single source in isolation, 2
single source in isolation, 2  scene with many sources. This judgment will be made at the time of submission and cross-checked for accuracy by the maintainers of the site.
scene with many sources. This judgment will be made at the time of submission and cross-checked for accuracy by the maintainers of the site.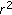 ) to "harshness", "complexity", "size", and "appeal". Since it is anticipated that some users will be interested in the semantic attributes of sounds, the four attributes mentioned in [
) to "harshness", "complexity", "size", and "appeal". Since it is anticipated that some users will be interested in the semantic attributes of sounds, the four attributes mentioned in [Harmonically Related Variables
-
(1)
Spectral centroid (closely related to the pitch, and will be expressed both in Hz and note scale value).
-
(2)
Spectral spread (the bandwidth in Hz).
-
(3)
Pitch salience (level of harmonicity of a sound—from [38]).
-
(4)
Estimated pitch. Environmental sounds are not homogeneous with regard to pitch. Some sounds, primarily vocalizations, have a harmonic structure and thus have a pitch that can be calculated using common pitch estimation methods (such as in [39]). However, some, such as impacts or scraping, have a spectrum that is more akin to a broadband noise, and thus most algorithms fail at extracting a reliable pitch. Since the pitch salience is a measure of the degree of harmonicity, for sounds with a pitch salience above 0.7 (on a scale of 0-1) the system will attempt to extract a pitch. For the remaining sounds, it will just report "N/A".
Rhythmically and Temporally Related Variables
-
(1)
Amplitude slope (reflects the initial attack and decay of a sound).
-
(2)
Autocorrelation peaks (indicating the degree and period of the rhythmicity of a sound).
These values can be automatically calculated for a sound upon entry [2].
5. Existing Sounds Online
5.1. Search Engines
There are a few existing search engines for environmental sounds on the Internet, an overview of which was provided in [4]. Most of these are geared towards sound effects for use in movies and music. Some of them are attached to libraries (including the excellent LABROSA site, http://labrosa.ee.columbia.edu/dpwe-bin/sfxlist.cgi); others just provide links to other web sites that contain the sounds (http://findsounds.com/, http://sound-effects-library.com/, and http://sonomic.com/). All of these engines allow searches by keywords, and some also allow specification of file format (.wav,.mp3), sampling rate, bit size, stereo/mono, and file size. Some of them provide schematics of the waveform and previews before downloading. The engines that simply search the Internet and provide links to other sites usually just give access to low-quality mp3s (in part to discourage users from recording them through their soundcards). Additional problems are the keywords are usually not standardized (so a search of "kitten" and "cat" would yield different sounds), and the copyright status of these clips is often not clear. In contrast, the search engines that are attached to dedicated libraries are usually not free and can be quite expensive if ordering a number of sounds (and the sounds are usually copyrighted and thus not freely distributable).
In the intervening years since the Shafiro and Gygi overview [4] some new sites have sprung up which more closely match the model being proposed here. Two examples are freesound.org and soundsnap.com. These are both collections of sounds donated by members, who are largely sound enthusiasts, both amateur and professional, which means the sounds are usually recognizable, and they are guaranteed to be freely sharable. Freesound.org requires sound submitters to abide by the Creative Commons license, which is described in the copyright notice above. The search engines allow searches on keywords (called tags in http://www.freesound.org/), descriptions, duration, bit rate, bit depth, and sampling rate or by the name of member who submitted the sound. The results of the search can be sorted by various criteria, such as relevance, and most recent, or the most popular. Related sounds can be organized into packs and downloaded as a group. People who are browsing the sounds can add tags and comments. Finally, and most interestingly, for a given sound, users can request to see "similar sounds", in which similarity is defined using the Wordnet taxonomy [40]. This is an instantiation of Query By Example (QBE) which is described in Section 10.
There are several advantages to these sites. They are open, the sounds are freely distributable, and users can create their own keywords. However, the lack of standardization of keywords can lead to difficulty in searches, and some of the sounds may be of dubious quality since the uploaded sounds are not moderated. The search engine itself is a bit clumsy when trying to handle and organize large numbers of sounds, and the only metadata on the sounds concern the audio type (mp3, wav, bit size, and sampling rate). Soundsnap suffers from similar problems, plus they seem to be moving towards a pay-to-download model. The database under construction will attempt to alleviate these problems.
6. Structure of the Proposed Database
The structure for the basic entries is shown below. It is similar to a structure that was suggested in [4], with some additional information added. For a single source, an entry is illustrated using one token of a baby crying sound see Table 1.
For an auditory scene example, an entry for a train station sound is used (see Table 2).
7. Sounds Accepted for Uploading
Sounds will be uploaded using the screen shown in Figure 4. The sounds accepted for uploading will all be high quality—at least 16-bit 22 kHz sampling rate for wav files, at least 196 kbps per channel bit rate for mp3s, with little or no clipped samples. The sounds must be recordings of physical sources—no synthesized sounds will be accepted. The sounds can either represent single sources or scenes. This will be designated by the originator upon uploading and verified by the admin. If the sounds represent single sources, a determination will be made as to the isolation of the source, that is, whether only the source is present or whether there are background sounds present.
8. Front End to the Database
There are four main front end functions that are essential to the functioning of the database. They are user enrollment and access; uploading sounds to the database; the search engine; and, perceptual testing.
8.1. User Levels
There will be three different user levels.
Admin would have all rights to the database and be limited to people working on the project.
-
(1)
Associates would be verified sound workers, whether researchers, designers, or recordists. They would be able to upload sounds without vetting, add research-related metadata (e.g., identifiability, acoustic analyses, and citations), and create new keywords.
-
(2)
Participants can download sounds, submit sounds for uploading, attach existing keywords to sounds, and suggest additional keywords.
8.2. The Search Engine
The portal to accessing sounds is the Sound Omnigrid shown in Figure 2. When users first enter the database, they are presented with the Omnigrid plus options for searching on and managing the sounds.

Omnigrid browser for DESRA.
If the user selects "Search" a search screen will come up. Users will be able to search upon any of the sound data and/or keywords. For example, a search on the keyword "rooster" returned the screen shown in Figure 3.

Search screen for DESRA.

Upload interface for DESRA.
Furthermore users can specify multiple criteria on any of the fields (e.g., search for sound types "horse" and "train" in either mp3 or wav format), and the number of tokens returned for each criterion, allowing users to easily create sound lists for further use. Where multiple sound tokens fit a particular criterion, a random one will be returned (or several random ones, if multiple tokens are requested) and this will be noted in the sound's search history so that usage statistics can be calculated and to prevent the same sound tokens from always being used. The users will be able to save the search criteria and the sound lists returned as part of their user profile. The users will also be able to organize sounds into selection sets to use in the experiment module of the database program (not discussed here) or for downloading and managing the sounds.
8.3. Adding/Editing Sound Data
As mentioned, admin and associates will be able to freely upload sounds, edit all sound data, and create keywords. Users will submit sounds for uploading and suggestions for new keywords, which will be vetted by the admin. Anyone who uploads or submits a sound for uploading will become the originator of that sound. Only admin will be able to delete sounds, with the exception that any originator will have the option to remove one of their sounds from the database.
8.4. Database
Participants can add or edit audio data on sounds they originate and can make ratings on other sounds for such metadata as "loud/soft", "harsh/smooth", familiarity, and typicality and make comments on the sounds.
8.5. Collecting User Supplied Data
Much of the desired data for a sound cannot be calculated and will have to be supplied. These data include behavioral data, such as identification and typicality, semantic attributes such as harshness and complexity, and subjective assessment such as the overall recording quality. There are a few avenues for obtaining these data. The preferred method would be to have access to experimentally obtained data from either the submitter of the sound or from researchers who have used the sound in studies. If that is not available, users can take part in online experiments available on the site which will require them to identify and rate a number of sounds on the various desired attributes under relatively controlled conditions. In addition, the main access page for each sound will provide an opportunity for users to provide ratings for this sound on several dimensions (e.g., via drop boxes to rate a sound for size or appeal). This is an extension to what is already present on the Freesound site, where users can judge the overall quality of a sound from the main screen for that sound. Sound ratings obtained on line for a representative subset of database sounds will also be validated in laboratory experiments under more tightly controlled listening conditions.
8.6. Other Front End Options
Users will be able to see the most recently uploaded sounds, the most frequently downloaded, and the highest or lowest on various criteria, for example, most identifiable, sounds rated loudest or softest, or sounds with specific acoustic attributes, such as pitch strength or rhythmicity.
9. Search Examples
-
(a)
A researcher wants to test some common environmental sounds in hearing impaired people. He wants 20 easily identifiable sounds with limited high frequency content that are not rated as being too "harsh" (and thus, unpleasant for hearing aid users), under 3 s in duration and three tokens of each sound.
-
(b)
A sound designer wants an unspecified number of sounds to include in a horror film, to take place in daytime and nighttime settings in a rural location. She wants the sounds to have a range of rms values, that is, some high intensity, some medium, and some low intensity, and she wants the sounds to be rated as chilling or intense, while being somewhat difficult to identify.
-
(c)
A musician wants some sound samples to drop in a song to match the lyrics. The samples should be short (under 500 ms), identifiable, and have a certain pitch to match the key of the song. He also wants some longer samples (around 1 s) with a strong rhythm to take the place of scratches or drum breaks.
10. Future Additions: Query by Example
A current feature of many music search engines is "Query by Example" (QBE) in which a user can search for a song that "sounds like" something, either a selection from another song or by some descriptive terms, such as "light and romantic." One example is the Shazam application for the iPhone which can recognize a song based upon a sample submitted to it [41]. It would be useful to apply this paradigm to environmental sounds, so that users could search for a sound that "sounds like" a sample submitted to it (e.g., if a user had a car crash sound they liked and wanted more that sound like it, they could retrieve those) or to identify a hard to identify sound sample based upon returned matches.
However, extending the technology that is currently used in most Music QBE searches is problematic for environmental sounds. Most musical QBE searches do an encoding of the song signal using some compression algorithm, such as Mel Frequency Cepstral Coefficients (MFCCs) or projections onto basis functions, which is the MPEG-7 standard. The compressed version is compared to stored examples and the closest match returned via a distance metric, a common one being a Gaussian Mixture Model [42, 43], which is one of the options in the MPEG-7 standard [44, 45]. These programs are greatly aided by the fact that nearly all musical examples have a similar structure. They are harmonic, which makes encoding by MFCCs particularly effective, extended in time, continuous (not many silent intervals), and nearly all have a few basic source types (strings, percussion, wood winds, and brass).
Environmental sounds, on the other hand, since they are produced by a much wider variety of sources, basically encompassing every sound-producing object in the environment, are much more varied in terms of their spectral-temporal structure, some being continuous and harmonic (a cow mooing), some continuous and inharmonic (wind blowing), some impulsive and inharmonic (basketball bouncing), and some impulsive and harmonic (ice dropping in glass). Finding a common coding scheme that can encompass all of these has proven quite difficult, and most systems that classify and recognize music well do quite poorly with a wide range of environmental sounds [46, 47]. It should be noted that this refers to individual environmental sounds in isolation. When multiple sound sources are combined in a soundscape the envelope tends to be smoother, and the long term spectrum approaches a pink noise [48, 49]. In this case, algorithms used for musical classification also perform quite well [50].
In musical QBE systems it is often the case that a musical sample is first associated with a certain genre, such as "rock" or "classical" due to gross acoustic characteristics common to members of that genre. Some algorithms for environmental sounds will similarly initially classify a sound clip based on a semantic taxonomy and then use signal features to narrow the search. An example of this is Audioclas [40, 51, 52] which uses Wordnet semantic classifiers [53] and was incorporated into Freesound.org's similarity search procedure. However, in [40] it was reported that the probability of retrieving conceptually similar sounds using this method was only 30%. An alternate taxonomy put forth in this issue by [54] is based on the one formulated by Gaver described earlier. A comparison of the two can be found in the Roma et al. piece in this issue [54].
However, there is another way to restrict the search space and thus enable better automatic recognition of environmental sounds which uses only signal properties. In [16] strong correlations were found between the ranking of sounds in a multidimensional similarity space and acoustic features of these sounds. For example, sounds that were grouped together on one dimension tended to be either strongly harmonic or inharmonic. A second dimension reflected the continuity or discontinuity of the sound. Based on this finding, a decision tree can be proposed for automatic classification of sounds, as shown in Figure 5. While this does not cover all the sounds, it is a fairly simple structuring that does account for a large percentage of the sounds necessary for an effective classification system and would greatly enable the development of a true automatic classification scheme for environmental sounds.

Proposed decision tree for automatic environmental sound recognition.
11. Summary
The structure of a database of environmental sounds has been outlined, which will relate to the way people listen to sounds in the world. The database will be organized around the sources of sounds in the world and will include a wide variety of acoustic, contextual, semantic, and behavioral data about the sounds, such as identifiability, familiarity, and typicality as well as acoustic attributes such as the spectral centroid, the duration, the harmonicity, semantic attributes of sounds, such as "harshness" or "complexity", and details of the recording, for example the location, the time, the distance of the microphone from the source, and the recording level, along with a citation history. A flexible search engine will enable a wide variety of searches on all aspects of the database and allow users to select sounds to fit their needs as closely as possible. This database will be an important research tool and resource for sound workers in various fields.
References
Shafiro V: Identification of environmental sounds with varying spectral resolution. Ear and Hearing 2008, 29(3):401-420. 10.1097/AUD.0b013e31816a0cf1
Gygi B, Kidd GR, Watson CS: Spectral-temporal factors in the identification of environmental sounds. Journal of the Acoustical Society of America 2004, 115(3):1252-1265. 10.1121/1.1635840
Gygi B, Shafiro V: Environmental sound research as it stands today. Proceedings of the Meetings on Acoustics, 2008 1: 050002.
Shafiro V, Gygi B: How to select stimuli for environmental sound research and where to find them. Behavior Research Methods, Instruments, and Computers 2004, 36(4):590-598. 10.3758/BF03206539
Gaver WW: What in the world do we hear? An ecological approach to auditory event perception. Ecological Psychology 1993, 5(1):1-29. 10.1207/s15326969eco0501_1
Schafer RM: The Tuning of the World. Knopf, New York, NY, USA; 1977.
Truax B: Acoustic Communication. Ablex, Westport, Conn, USA; 2001.
Droumeva M: Understanding immersive audio: a historical and socio-cultural exploration of auditory displays. Proceedings of the 11th International Conference on Auditory Display (ICAD '05), 2005 162-168.
Ballas JA, Howard JH: Interpreting the language of environmental sounds. Environment and Behavior 1987, 19(1):91-114. 10.1177/0013916587191005
Gaver WW: Everyday listening and auditory icons. In Cognitive Science and Psychology. University of California, San Diego, Calif, USA; 1998:90.
Jenkins JJ: Acoustic information for objects, places, and events. In Persistence and Change: Proceedings of the 1st International Conference on Event Perception. Edited by: Warren WH, Shaw RE. Lawrence Erlbaum, Hillsdale, NJ, USA; 1985:115-138.
Vanderveer NJ: Ecological acoustics: human perception of environmental sounds. Dissertation Abstracts International 1980, 40(9):4543.
Gibson JJ: Survival in a world of probable objects. In The essential Brunswik: Beginnings, Explications, Applications. Edited by: Gibson JJ. Oxford University Press, Oxford, England; 2001:244-246.
Bonebright TL: Perceptual structure of everyday sounds: a multidimensional scaling approach. In Proceedings of the International Conference on Auditory Display, 2001, Espoo, Finland. Laboratory of Acoustics and Audio Signal Processing and the Telecommunications Software and Multimedia Laboratory, Helsinki University of Technology;
Giordano BL, McAdams S: Material identification of real impact sounds: effects of size variation in steel, glass, wood, and plexiglass plates. Journal of the Acoustical Society of America 2006, 119(2):1171-1181. 10.1121/1.2149839
Gygi B, Kidd GR, Watson CS: Similarity and categorization of environmental sounds. Perception and Psychophysics 2007, 69(6):839-855. 10.3758/BF03193921
Pastore RE, Flint JD, Gaston JR, Solomon MJ: Auditory event perception: the source-perception loop for posture in human gait. Perception and Psychophysics 2008, 70(1):13-29. 10.3758/PP.70.1.13
Marcell MM, Borella D, Greene M, Kerr E, Rogers S: Confrontation naming of environmental sounds. Journal of Clinical and Experimental Neuropsychology 2000, 22(6):830-864. 10.1076/jcen.22.6.830.949
Heller LM, Skerrit B: Action as an organizing principle of auditory cognition. Proceedings of the Auditory Perception, Action and Cognition Meeting, 2009, Boston, Mass, USA
Bregman AS: Auditory scene analysis: hearing in complex environments. In Thinking in Sound: The Cognitive Psychology of Human Audition. Edited by: McAdams S, Bigand E. Clarendon Press, Oxford, UK; 1991:10-36.
Ballas JA, Mullins T: Effects of context on the identification of everyday sounds. Human Performance 1991, 4(3):199-219. 10.1207/s15327043hup0403_3
Gygi B, Shafiro V: The incongruency advantage for environmental sounds presented in natural auditory scenes. Journal of Experiemental Psychology, In press
Leech R, Gygi B, Aydelott J, Dick F: Informational factors in identifying environmental sounds in natural auditory scenes. Journal of the Acoustical Society of America 2009, 126(6):3147-3155. 10.1121/1.3238160
Solomon LN: Search for physical correlates to psychological dimensions of sounds. The Journal of the Acoustical Society of America 1959, 31(4):492. 10.1121/1.1907741
Carello C, Anderson KL, Kunkler-Peck AJ: Perception of object length by sound. Psychological Science 1998, 9(3):211-214. 10.1111/1467-9280.00040
Feed DJ: Auditory correlates of perceived mallet hardness for a set of recorded percussive sound events. Journal of the Acoustical Society of America 1990, 87(1):311-322. 10.1121/1.399298
Kunkler-Peck AJ, Turvey MT: Hearing shape. Journal of Experimental Psychology 2000, 26(1):279-294.
Gygi B, Shafiro V: The incongruency advantage for sounds in natural scenes. Proceedings of the 125th Meeting of the Audio Engineering Society, 2008, San Francisco, Calif, USA
Gygi B: Parsing the blooming buzzing confusion: identifying natural auditory scenes. Speech Separation and Comprehension in Complex Acoustic Environments, 2004, Montreal, Quebec, Canada
Bjork EA: The perceived quality of natural sounds. Acustica 1985, 57: 185-188.
Kidd GR, Watson CS: The perceptual dimensionality of environmental sounds. Noise Control Engineering Journal 2003, 51(4):216-231. 10.3397/1.2839717
von Bismarck G: Timbre of steady sounds: a factorial investigation of its verbal attributes. Acustica 1974, 30(3):146-159.
Solomon LN: Semantic approach to the perception of complex sounds. The Journal of the Acoustical Society of America 1958, 30: 421-425. 10.1121/1.1909632
Osgood CE: The nature and measurement of meaning. Psychological Bulletin 1952, 49(3):197-237. 10.1037/h0055737
Ballas JA: Common factors in the identification of an assortment of brief everyday sounds. Journal of Experimental Psychology 1993, 19(2):250-267.
Daniel P, Weber R: Psychoacoustical roughness: implementation of an optimized model. Acustica 1997, 83(1):113-123.
Zwicker E, Fastl H: Psychoacoustics: Facts and Models. Springer, Berlin, Germany; 1999.
Slaney M: Auditory Toolbox: a Matlab toolbox for auditory modeling work. 1995., (Apple Computer no. 45):
Terhardt E, Stoll G, Seewann M: Algorithm for extraction of pitch and pitch salience from complex tonal signals. Journal of the Acoustical Society of America 1982, 71(3):679-688. 10.1121/1.387544
Cano P, Koppenberger M, Le Groux S, Ricard J, Wack N, Herrera P: Nearest-neighbor automatic sound annotation with a WordNet taxonomy. Journal of Intelligent Information Systems 2005, 24(2-3):99-111. 10.1007/s10844-005-0318-4
Wang A: The Shazam music recognition service. Communications of the ACM 2006, 49(8):44-48. 10.1145/1145287.1145312
Ellis DPW: Audio signal recognition for speech, music, and environmental sounds. The Journal of the Acoustical Society of America 2003, 114(4):2424.
Aucouturier J-J, Defreville B, Pachet F: The bag-of-frames approach to audio pattern recognition: a sufficient model for urban soundscapes but not for polyphonic music. Journal of the Acoustical Society of America 2007, 122(2):881-891. 10.1121/1.2750160
Casey M: General sound classification and similarity in MPEG-7. Organised Sound 2001, 6(2):153-164. 10.1017/S1355771801002126
Casey M: MPEG-7 sound-recognition tools. IEEE Transactions on Circuits and Systems for Video Technology 2001, 11(6):737-747. 10.1109/76.927433
Hyoung-Gook K, et al.: Enhancement of noisy speech for noise robust front-end and speech reconstruction at back-end of DSR system. IEEE Transactions on Circuits and Systems for Video Technology 2003, 14(5):716-725.
Mitrovic D, Zeppelzauer M, Eidenberger H: Analysis of the data quality of audio descriptions of environmental sounds. Journal of Digital Information Management 2007, 5(2):48-54.
De Coensel B, Botteldooren D, De Muer T: 1/f noise in rural and urban soundspaces. Acta Acustica 2003, 89(2):287-295.
Boersma HF: Characterization of the natural ambient sound environment: measurements in open agricultural grassland. Journal of the Acoustical Society of America 1997, 101(4):2104-2110. 10.1121/1.418141
Aucouturier J-J, Defreville B: Sounds like a park: a computational technique to recognize soundscapes holistically, without source identification. Proceedings of the 19th International Congress on Acoustics, 2007, Madrid, Spain
Cano P, et al.: Knowledge and content-based audio retrieval using wordNet. Proceedings of the International Conference on E-business and Telecommunication Networks (ICETE), 2004
Gouyon F, et al.: Content processing of music audio signals. In Sound to Sense, Sense to Sound: A State of the Art in Sound and Music Computing. Edited by: Polotti P, Rocchesso D. Logos, Berlin; 2008:83-160.
Miller GA: WordNet: a lexical database for English. Communications of the ACM 1995, 38(11):39-41. 10.1145/219717.219748
Roma G, et al.: Ecological acoustics perspective for content-based retrieval of environmental sounds. EURASIP Journal on Audio, Speech, and Music Processing, submitted
Acknowledgments
The authors would like to thank Kim Ho for her work in collecting and annotating a large number of sounds from the Internet. This work was partially supported by a Merit Review Training Grant from the Department of Veterans Affairs Research Service, VA File no. 06-12-00446 to B. Gygi and by a grant from the National Institute of Health/National Institute of Deafness and Communication Disorders no. DC008676 to V. Shafiro.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Gygi, B., Shafiro, V. Development of the Database for Environmental Sound Research and Application (DESRA): Design, Functionality, and Retrieval Considerations. J AUDIO SPEECH MUSIC PROC. 2010, 654914 (2010). https://doi.org/10.1155/2010/654914
Received:
Accepted:
Published:
DOI: https://doi.org/10.1155/2010/654914