- Research Article
- Open access
- Published:
A Novel MPEG Audio Degrouping Algorithm and Its Architecture Design
EURASIP Journal on Audio, Speech, and Music Processing volume 2010, Article number: 737450 (2010)
Abstract
Degrouping is the key component in MPEG Layer II audio decoding. It mainly contains the arithmetic operations of division and modulo. So far no dedicated degrouping algorithm and architecture is well realized. In the paper we propose a novel degrouping algorithm and its architecture design with low complexity design consideration. Our approach relies on only using the addition and subtraction instead of the division and modulo arithmetic operations. By use of this technique, it achieves the equivalent result without any loss of accuracy. The proposed design is without any multiplier, divider and ROM table and thus it can reduce the design complexity and chip area. In addition, it does not need any programming effort on numerical analysis. The result shows that it takes the advantages of simple and low cost design. Furthermore, it achieves high efficiency on fixed throughput with only one clock cycle per sample. The VLSI implementation result indicates the gate counts are only 527.
1. Introduction
MPEG audio coding standard is the international standard for the compression of digital audio signals [1]. It can be applied both for audiovisual and audio-only applications to significantly reduce the requirements of transmission bandwidth and data storage with low distortion. The second phase of MPEG, labeled as MPEG-II, aims to support all the normative features listed in MPEG-I audio and provides extension capabilities of multichannel and multilingual audio and on an extension of standard to lower sampling frequencies and lower bit rates [2, 3]. Besides, one of the audio coding, Advanced Audio Coding (AAC), is an international standard which is first created in MPEG-II AAC and the base of MPEG-IV general audio coding [4].
MPEG audio compression standard also defines three layers of compression, named Layer I, II, and III. Each successive layer offers better compression performance, but at a higher complexity and computation cost. Basically Layer I and II are similar and based on subband coding. The difference between them mainly relies on the formation of side information and a finer quantization is provided in Layer II. Layer III is a well-known audio application and popularly named as MP3. It adopts more complex schemes such as hybrid filterbank, Huffman coding, and nonlinear quantization. From the viewpoint of hardware complexity and achieved quality, Layer II might be a reasonable compromise for general usage. In the official ISO/MPEG subject tests, Layer II codec shows an excellent performance of CD quality at a 128 Kbps per monophonic channel [5]. It has also been adopted in Digital Audio Broadcasting (DAB) standard.
Within the Layer II decoding, degrouping is the key component which can recover the samples from a more compressed codeword. The degrouping module is quite special compared with other popular compression techniques, such as subband or Huffman decoding. Although the computation-intensive characteristic in subband decoding induces large computation complexity, it can be efficiently improved no matter in algorithm or architecture level [6, 7]. However, as will be described in more detail below, the arithmetic operations for degrouping mainly contain division and modulo. Unfortunately, degrouping operation only happen in Layer II decoding. Even in a higher layer, Layer III (MP3), the degrouping is reorganized and recombined in Huffman decoding to eliminate the division and modulo computation. For the recent trend, a universal MPEG audio decoding which can support multiple standards is widely developed and applied in many multimedia and communication devices [8, 9]. They solved the common and regular module, synthesis subband with relative improvements. However, they still left some unsolved issue on the other nonregular modules. In fact, degrouping is a must module no matter the target design is on Layer II only, or on a multistandard decoder.
As in the conventional methods, the general purpose CPU, DSP, or ASP (audio signal processor) usually provides some division or modulo instructions to execute the arithmetic operations of degrouping [10–12]. Basically these designs implied either a divider directly, or a multiplier by finding the inverse of the divisor and multiplying the inverse by the dividend. In fact, the numerical analysis methods suffer some low-end general purpose processors that especially the low-end general purpose processors that are initially chosen to play a simple role as a parser or controller. Even for some high-end processors, to support the additional instruction set of division or modulo is also an overhead. Consequently, these approaches will increase the hardware complexity and the chip area. Several techniques used a ROM-based table lookup to replace the multiplier [13, 14]. However, ROM circuit grows exponentially with the dimension of the finite field. Although many fast algorithms for computing the division and modulo arithmetic operations have been presented throughout the years [15–17], these techniques cannot be completely adopted in the MPEG degrouping algorithm. One of the concern is that these previous methods mainly focused on generating the modulo calculation only. Quotient results are useless for their need. Nevertheless, in degrouping the quotient cannot be skipped because it represents the codeword for the next iteration. So far no dedicated degrouping algorithm and its architecture is investigated.
In the paper, we propose a novel MPEG degrouping algorithm and its architecture design. It is built by using quite different design concept than all the reference works. Our approach relies on just only using the addition and subtraction instead of the traditional division and modulo arithmetic operations, and without any loss of accuracy. It eliminates the need of iterative division computation in original algorithm. Based on the proposed algorithm, no multiplier, divider and ROM table is needed. The design takes the advantages of simple and low cost, and high efficiency result with fixed throughput. It only occupies 527 gate counts with 8.35 ns propagation delay. With this easy-for-use and compact-size design, it is suitably integrated as an Intellectual Property (IP) in System-on-Chip (SOC) design trend.
2. MPEG Degrouping Process
The overall MPEG decoding flow chart is described in Figure 1. It includes some major functional blocks: decoding of side information, requantization, and synthesis subband filter bank. Figure 1 also shows a further decomposition of requantization of samples in Layer II application, where degrouping represents an essential component. We describe the grouping and degrouping process in more detail below.

MPEG decoding flow chart.
2.1. Grouping
In MPEG audio encoder, given the number of steps from bit allocation, the samples will be quantized. The further compression feature in Layer II allows two new quantizations, namely, 5-level and 9-level. For these new quantizations plus the former 3-level quantization, sample grouped coding is used. If grouping is required, three consecutive samples are coded as one codeword. Only one value  is transmitted for this triplet. For 3-, 5-, and 9-level quantization, a triplet is coded using a 5-, 7-, or 10-bit codeword, respectively. The relationships between the coded value
is transmitted for this triplet. For 3-, 5-, and 9-level quantization, a triplet is coded using a 5-, 7-, or 10-bit codeword, respectively. The relationships between the coded value  (
( ) and the three consecutive subband samples
) and the three consecutive subband samples  ,
,  ,
,  are listed in Table 1.
are listed in Table 1.
In order to make a clear realization on the benefits of grouping processing, Figure 2 illustrates the examples of the three modes. For mode 1, a 5-bit codeword is grouped and it represents three 2-bit samples in actual. Consequently, one bit is saved without any data and precision loss. The same situation on mode 2 results in a saving with two bits, cause a 7-bit codeword can represent three 3-bit samples. In mode 3, two bits are also saved.

Benefits for grouping processing.
2.2. Degrouping
While grouping is used in encoder, it is necessary to separate the combined sample codeword to several individual samples by degrouping in decoder. According to the grouping equation in Table 1, degrouping has to perform the division and modulo operations to separate the three individual samples. This process is defined by MPEG standard algorithm and depicted in Algorithm 1. Within the degrouping algorithm, the  can be 3, 5, and 9.
can be 3, 5, and 9.
Algorithm 1: Standard degrouping algorithm.
Algorithm DEGROUPING
for ( ;
;  ;
;  )
)
{
 ;
;
 ;
;
}
where  the reconstructed sample
the reconstructed sample
 the codeword
the codeword
 the number of quantization steps
the number of quantization steps
2.3. Design Considerations
Table 3 summarizes the total arithmetic operations used in MPEG Layer II audio decoding. In the whole decoding, a characteristic analysis on the arithmetic operations shows that multiplication and addition are the most common operations where they are mainly applied in synthesis subband filter [18, 19]. Specifically, degrouping only occupies about 1% computation power in the whole MPEG-II decoding process [20]. In SOC design trend, the computation amount is not the only concern. Instead, an easy-for-use issue without additional design effort on overall system should be applicable. Particular, the degrouping arithmetic operations are fully different from any other decoding functions and thus it cannot be shared with other resources. When facing the design of either Layer-II decoding only or a universal MPEG audio decoder, such a little but unavoidable computation engine leads to special design consideration and effort. Consequently, to reduce the circuit overhead and complexity, a low cost and high performance degrouping algorithm and its architecture are necessary.
3. Proposed Algorithm
A degrouping function in MPEG standard includes the division and modulo arithmetic operation. Unlike a straightforward implementation for these required arithmetic operations, our approach accomplishes it with only a simple addition and shifter operation. We make a mathematical deduction which implies it as a generic formula. In Section 3.1, a general form is derived. Concerning the specification of degrouping, Section 3.2 conducts the proposed degrouping algorithm.
To start it, let  and
and  be any two positive integers and
be any two positive integers and  ,
,  . We can express the general form as
. We can express the general form as  , where
, where  is the quotient and
is the quotient and  is the remainder. Besides,
is the remainder. Besides,  can be represented as an
can be represented as an  -digit tuple:
-digit tuple:

where  ,
,  . The operation
. The operation  is the simplified expression for a digit-based tuple. From (1), it follows that if
is the simplified expression for a digit-based tuple. From (1), it follows that if  , then
, then  can be represented as given below
can be represented as given below

In comparison with (1) and (2),  and
and  can be expressed as follows:
can be expressed as follows:

3.1. General Form as 

As in (1), let  , then
, then  , and 3 are mapping to the three modes of degrouping algorithm, respectively. From the previous discussions, it is expressed as follows:
, and 3 are mapping to the three modes of degrouping algorithm, respectively. From the previous discussions, it is expressed as follows:

 is the
is the  -stage quotient, where it can be recursively expressed with the next-stage quotient and remainder
-stage quotient, where it can be recursively expressed with the next-stage quotient and remainder  and
and  . Because
. Because  ,
, , thus
, thus  . From the iterative decomposition of (4), we proceed is as follows:
. From the iterative decomposition of (4), we proceed is as follows:

Comparing between (2) and (5), let

 and
and  are easily calculated. They can be viewed as the approximated results, which are not exactly equivalent to the correct quotient and remainder,
are easily calculated. They can be viewed as the approximated results, which are not exactly equivalent to the correct quotient and remainder,  and
and  . From (6), because
. From (6), because  , for
, for  , the range of
, the range of  and
and  can be clarified as follows.
can be clarified as follows.
Case 1.
 , then
, then

Substituting (7) into (5), we obtain the range of  as follows:
as follows:

Case 2.
 , then the range of
, then the range of  is
is

In this case, the range of  is
is

Now let us take consideration on three modes of  , and 3.
, and 3.
3.2. Arithmetic Operations for Mode 1, 2, 3
The proposed algorithm for the calculation of  and
and  with their deviation ranges are illustrated in Table 2. It accomplishes the division and modulo by only processing the codeword
with their deviation ranges are illustrated in Table 2. It accomplishes the division and modulo by only processing the codeword  , which can be viewed as a 2-tuple representation of
, which can be viewed as a 2-tuple representation of  ,
,  . Each intermediate operand, denoted as
. Each intermediate operand, denoted as  for convenience, is obtained by shifting right
for convenience, is obtained by shifting right  bits and dropping rightmost bits of
bits and dropping rightmost bits of  after each shift.
after each shift.
 and
and  .
.Figure 3 describes a graphical representation of the proposed algorithm for the calculating of  and
and  in three modes. It shows that four operands are generated by shifting in mode 2 and 3. Then these operands take the interlacing computations by two subtractions and one addition. In mode 1, five operands are generated and the computation is achieved by two subtractions and two additions. The addition for the last operand of
in three modes. It shows that four operands are generated by shifting in mode 2 and 3. Then these operands take the interlacing computations by two subtractions and one addition. In mode 1, five operands are generated and the computation is achieved by two subtractions and two additions. The addition for the last operand of  , a one digit number, can be viewed as an additional carry for the adder. This approach takes the benefit on reducing one addition in mode 1. More specifically, the processes for all three modes are then equivalent.
, a one digit number, can be viewed as an additional carry for the adder. This approach takes the benefit on reducing one addition in mode 1. More specifically, the processes for all three modes are then equivalent.

Graphical representation of proposed algorithm for the fast calculation of
 and
and
 .
.
In addition to the fast calculation on  and
and  , the exactly correct results of
, the exactly correct results of  and
and  must need future process from
must need future process from  and
and  . The correct result of
. The correct result of  is obtained by getting the
is obtained by getting the  plus or minus with a value of a divisor in each associated mode. The correct result of
plus or minus with a value of a divisor in each associated mode. The correct result of  is obtained by getting the
is obtained by getting the  plus or minus with a value of one in all three modes. This implies that just a simple and regular correction is performed to get the exactly correct value of
plus or minus with a value of one in all three modes. This implies that just a simple and regular correction is performed to get the exactly correct value of  and
and  from
from  and
and  , respectively. The detailed flow chart for the proposed algorithm is depicted in Figure 4.
, respectively. The detailed flow chart for the proposed algorithm is depicted in Figure 4.

The overall flow chart for proposed algorithm.
3.3. Data Reordering Scheme
Based on the previous discussions, the proposed algorithm can be implemented by two subtractions and one addition with four operands:  , and
, and  in all three modes. In order to reduce the hardware cost, we use the concept of data reordering to change the data computation flow. We compute the operands of
in all three modes. In order to reduce the hardware cost, we use the concept of data reordering to change the data computation flow. We compute the operands of  and
and  and the associated arithmetic operation first, then compute the operands of
and the associated arithmetic operation first, then compute the operands of  and
and  and the associated arithmetic operation. In fact, the result for
and the associated arithmetic operation. In fact, the result for  plus
plus  is equal to the result for
is equal to the result for  plus
plus  by only shifting right
by only shifting right  bits. This means that the arithmetic operation for
bits. This means that the arithmetic operation for  plus
plus  is trivial and can be removed. The data reordering scheme reduces the arithmetic operations in saving of one subtractor hardware cost, as illustrated in Figure 5.
is trivial and can be removed. The data reordering scheme reduces the arithmetic operations in saving of one subtractor hardware cost, as illustrated in Figure 5.

Data reordering scheme.
4. Architecture Design
In architecture design, the proposed algorithm with data reordering scheme is adopted. Figure 6 shows that the key components of this design include one special adder (SpADD), two subtractors (SUB); and two adders (ADD). Based on the maximum number range of codeword  in mode 3, 10 bit-width bus is assigned for
in mode 3, 10 bit-width bus is assigned for  . The shifter takes the right shift of
. The shifter takes the right shift of  bits to obtain another operand from
bits to obtain another operand from  . The SpADD generates a 10-bit sum of
. The SpADD generates a 10-bit sum of  , and two one-bit carries of
, and two one-bit carries of  ,
,  .
.  is the carry of addition for 4-bit LSB and
is the carry of addition for 4-bit LSB and  is the carry for all-bit addition.
is the carry for all-bit addition.

The block diagram of degrouping architecture.
As indicated in Figure 6, the signals of  ,
,  , and
, and  can be demultiplexed into the partial quotients of
can be demultiplexed into the partial quotients of  and
and  , and the partial remainders of
, and the partial remainders of  and
and  .
.  ,
,  ,
,  and
and  represent the operand with the 2-tuple representation of
represent the operand with the 2-tuple representation of  and
and  in Figure 3. These partial results are fed into the two subtractors to generate the
in Figure 3. These partial results are fed into the two subtractors to generate the  and
and  . The following two adders take the roles of correcting the
. The following two adders take the roles of correcting the  and
and  into the real results of
into the real results of  and
and  . Finally, the operand of
. Finally, the operand of  is fed back and latched in the input register for the use of next degrouping cycle. This approach achieves the fixed throughput with one clock cycle per sample.
is fed back and latched in the input register for the use of next degrouping cycle. This approach achieves the fixed throughput with one clock cycle per sample.
The internal architecture of SpADD is illustrated in Figure 7. It basically consists of four full adders and six half adders with a ripple-carry architecture. The signal of  is the carry represented as the additional operand in mode 1. The implemented circuit is nonpipelined. However, it can be easily pipelined with the addition of register at every stages. Moreover, this architecture takes the advantages of simple and low cost design, but high efficiency requirement.
is the carry represented as the additional operand in mode 1. The implemented circuit is nonpipelined. However, it can be easily pipelined with the addition of register at every stages. Moreover, this architecture takes the advantages of simple and low cost design, but high efficiency requirement.

The internal architecture of SpADD.
5. Comparisons and Experimental Results
In this section, we describe the comparisons and experimental results with our proposed algorithm. The experiments attempt to cover the whole range of  for all three modes, as illustrated in Figures 8, 9, and 10. They show the deviations of
for all three modes, as illustrated in Figures 8, 9, and 10. They show the deviations of  with respect to
with respect to  , and
, and  with respect to
with respect to  . From the approximated result of
. From the approximated result of  and
and  , and the real result of
, and the real result of  and
and  , the derivation between them are varied periodically. Some value
, the derivation between them are varied periodically. Some value  and
and  are equal to
are equal to  and
and  , but some of them are not the same. For example, in mode 1 it shows that when the value of
, but some of them are not the same. For example, in mode 1 it shows that when the value of  is greater than 2, the value of
is greater than 2, the value of  is less than
is less than  . When the value
. When the value  is less than 0, the value of
is less than 0, the value of  is greater than
is greater than  . Every difference between
. Every difference between  and
and  is exactly equal to one.
is exactly equal to one.

Experiment results of mode 1 for the deviation value of (a)
 with respect to
with respect to
 and (b)
and (b)
 with respect to
with respect to
 .
.

Experiment results of mode 2 for the deviation value of (a)
 with respect to
with respect to
 and (b)
and (b)
 with respect to
with respect to
 .
.

Experiment results of mode 3 for the deviation value of (a)
 with respect to
with respect to
 and (b)
and (b)
 with respect to
with respect to
 .
.
The comparisons between the standard and proposed algorithm with two schemes are illustrated in Table 4. All the computation functions must have the minimum wordlength of 10 bits to satisfy the whole range of  . In addition, the architectural comparisons between the proposed design and some conventional techniques are shown in Table 5.
. In addition, the architectural comparisons between the proposed design and some conventional techniques are shown in Table 5.
The proposed degrouping architecture is implemented as an IP with VLSI technical details and summarized in Table 6. As the characteristics of regularity and modularity, our novel design only needs 527 gates based on the applied technology. It can run at about 120 MHz which is many times speedup compared with the low operating frequency of 44.1 KHz audio sample rate. It also has the advantages of fix throughput with one clock cycle per sample.
In order to reflect our advantages in more detail, two reference designs with real implemented results are constructed and listed in Tables 7 and 8. We design the degrouping by the straightforward solution, lookup ROM table, with the same VLSI technology. Referring to the codeword size listed in Table 1, three tables are generated optimally and the table word size is 32, 128, and 1024 for three degrouping modes respectively. From the implementation result in Table 7, totally the gate count is more than 3400 including the storage element and decoding circuit. From Table 6, it almost takes seven times of gate count than ours. Another implementation result is listed in Table 8. It is implemented on one of the popular general purpose processor with its two version, ARM7 and ARM9 [21]. The results show that, each processor performs the degrouping iteration with 223 and 142 clock cycles, respectively. For our hardwired degrouping design, only 3 cycles are consumed to acquire the 3 output samples in each iteration. Note that the programmable processor certainly needs the space to store the programming code. In their results almost 2 KB memory are needed. Based on the comparison results, our design can achieve the low complexity and high efficiency considerations, while still keeps the least usage on area.
6. Conclusions
Although only occupying little computation power in the whole decoding process, degrouping process is an essential component in MPEG Layer II audio decoding, especially when meeting the universal MPEG audio decoding requirement. A straightforward design without thorough consideration on algorithm makes an inefficient result. So far no dedicated degrouping algorithm and architecture is developed. We have proposed a novel degrouping algorithm which relies on only using the addition and subtraction instead of the division and modulo arithmetic operations supplied by standard algorithm. It maintains high efficiency without loss of any accuracy. The proposed design is without any multiplier, divider, and ROM table. In addition, to reduce the arithmetic operations in saving of one subtractor, a modified scheme of data reordering is constructed. Based on our algorithm, we propose a degrouping architecture with the advantages of simple and low-cost design, and high efficient requirement on fixed throughput. Compared with the general approaches such as direct table lookup or direct programminglevel solution, our method outperforms them either in physical gate count or throughput. It is easily applicable without any programming cost. The VLSI implementation result shows that only 527 gate counts are realized. It is proper to be integrated as a hard IP in the SOC design trend.
References
MPEG : ISO CD 11172-3: coding of moving pictures and associated audio for digital storage media at up to about 1.5 Mb/s. 1991.
MPEG : ISO CD 13818-3: coding of moving pictures and associated audio for digital storage media at up to about 1.5 Mb/s. 1994.
Brandenburg K, Bosi M: Overview of MPEG audio: current and future standards for low-bit-rate audio coding. Journal of the Audio Engineering Society 1997, 45(1-2):4-21.
MPEG : ISO CD 13818-7: MPEG-2 Advanced Audio Coding , AAC. 1997.
Rao KR, Hwang JJ: Techniques and Standards for Digital Image/Video/Audio Coding. Prentice Hall, Upper Saddle River, NJ, USA; 1996.
Lee SW: Improved algorithm for efficient computation of the forward and backward MDCT in MPEG audio coder. IEEE Transactions on Circuits and Systems II 2001, 48(10):990-994. 10.1109/82.974789
Tsai TH, Yang YC: Low power and cost effective VLSI design for an MP3 audio decoder using an optimised synthesis-subband approach. IEE Proceedings: Computers and Digital Techniques 2004, 151(3):245-251. 10.1049/ip-cdt:20040486
Bang KH, Jeong NH, Kim JS, Park YC, Youn DH: Design and VLSI implementation of a digital audio-specific DSP core for MP3/AAC. IEEE Transactions on Consumer Electronics 2002, 48(3):790-795. 10.1109/TCE.2002.1037076
Tsai TH, Liu CN: A configurable common filterbank processor for multi-standard audio decoder. IEICE Transactions on Fundamentals of Electronics, Communications and Computer Sciences 2007, E90-A(9):1913-1923. 10.1093/ietfec/e90-a.9.1913
Maturi G: Single chip MPEG audio decoder. IEEE Transactions on Consumer Electronics 1992, 38(3):348-356. 10.1109/30.156706
Han SC, Yoo SK, Park SW, Jeong NH, Kim JS, Kim KIS, Han YT, Youn DH: An ASIC implementation of the MPEG-2 audio decoder. IEEE Transactions on Consumer Electronics 1996, 42(3):540-545. 10.1109/30.536154
Bergher L, Figari X, Frederiksen F, Froidevaux M, Gentit JM, Queinnec O: MPEG audio decoder for consumer applications. Proceedings of the 17th Annual Custom Integrated Circuits Conference, May 1995 413-416.
Soderstrand MA: A new hardware implementation of modulo adders for residue number systems. Proceedings of the 26th Midwest Symposium on Circuits and Systems, 1983 412-415.
Liu KY: Architecture for VLSI design of Reed-Solomon decoders. IEEE Transactions on Computers 1984, 33(2):178-189.
Wei S, Shimizu K:Modulo (
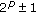 ) multipliers using a three-operand modular addition and booth recoding based on signed-digit number arithmetic. Proceedings of the IEEE International Symposium on Circuits and Systems, May 2003 221-224.
) multipliers using a three-operand modular addition and booth recoding based on signed-digit number arithmetic. Proceedings of the IEEE International Symposium on Circuits and Systems, May 2003 221-224.York TA, Srisuchinwong B, Tsalides P, Hicks PJ, Thanailakis A: Design and VLSI implementation of mod-127 multiplier using cellular automaton-based data compression techniques. IEE Proceedings E 1991, 138(5):351-356.
Piestrak SJ: Design of residue generators and multioperand adders modulo 3 built of multioutput threshold circuits. IEE Proceedings: Computers and Digital Techniques 1994, 141(2):129-134. 10.1049/ip-cdt:19949982
Jhung Y, Park S: Architecture of dual mode audio filter for AC-3 and MPEG. Proceedings of the International Conference on Consumer Electronics (ICCE '97), June 1997 206-207.
Krishnan T, Oraintara S: Fast and lossless implementation of the forward and inverse MDCT computation in MPEG audio coding. Proceedings of the IEEE International Symposium on Circuits and Systems, May 2002 2: 181-184.
Tsai TH, Chen LG, Liu YC: A novel MPEG-2 audio decoder with efficient data arrangement and memory configuration. IEEE Transactions on Consumer Electronics 1997, 43(3):598-604. 10.1109/30.628682
ARM website http://www.arm.com/
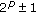 ) multipliers using a three-operand modular addition and booth recoding based on signed-digit number arithmetic. Proceedings of the IEEE International Symposium on Circuits and Systems, May 2003 221-224.
) multipliers using a three-operand modular addition and booth recoding based on signed-digit number arithmetic. Proceedings of the IEEE International Symposium on Circuits and Systems, May 2003 221-224.Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Tsai, TH. A Novel MPEG Audio Degrouping Algorithm and Its Architecture Design. J AUDIO SPEECH MUSIC PROC. 2010, 737450 (2010). https://doi.org/10.1155/2010/737450
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1155/2010/737450