- Research Article
- Open access
- Published:
Wide-Band Audio Coding Based on Frequency-Domain Linear Prediction
EURASIP Journal on Audio, Speech, and Music Processing volume 2010, Article number: 856280 (2010)
Abstract
We revisit an original concept of speech coding in which the signal is separated into the carrier modulated by the signal envelope. A recently developed technique, called frequency-domain linear prediction (FDLP), is applied for the efficient estimation of the envelope. The processing in the temporal domain allows for a straightforward emulation of the forward temporal masking. This, combined with an efficient nonuniform sub-band decomposition and application of noise shaping in spectral domain instead of temporal domain (a technique to suppress artifacts in tonal audio signals), yields a codec that does not rely on the linear speech production model but rather uses well-accepted concept of frequency-selective auditory perception. As such, the codec is not only specific for coding speech but also well suited for coding other important acoustic signals such as music and mixed content. The quality of the proposed codec at 66 kbps is evaluated using objective and subjective quality assessments. The evaluation indicates competitive performance with the MPEG codecs operating at similar bit rates.
1. Introduction
Modern speech coding algorithms are based on source-filter model, wherein the model parameters are extracted using linear prediction principles applied in temporal domain [1]. Most popular audio coding algorithms are based on exploiting psychoacoustic models in the spectral domain [2, 3]. In this work, we explore signal processing methods to code speech and audio signals in a unified approach.
In traditional applications of speech coding (i.e., for conversational services), the algorithmic delay of the codec is one of the most critical variables. However, there are many services, such as downloading the audio files, voice messaging, or push-to-talk communications, where the issue of the codec delay is much less critical. This allows for a whole set of different coding techniques that could be more effective than the conventional short-term frame-based coding techniques.
Due to the development of new audio services, there has been a need for new audio compression techniques which would provide sufficient generality, that is, the ability to encode any kind of the input signal (speech, music, signals with mixed audio sources, and transient signals). Traditional approaches to speech coding based on source-filter model have become very successful in commercial applications for toll quality conversational services. However, they do not perform well for mixed signals in many multimedia services. On the other hand, perceptual codecs have become useful in media coding applications, but are not as efficient for speech content. These contradictions have recently turned into new initiatives of standardization organizations (3GPP, ITU-T, and MPEG), which are interested in developing a codec for compressing mixed signals, for example, speech and audio content.
This paper describes a coding technique that revisits (similar to [4]) the original concept of the first speech coder [5], where the speech is seen as a carrier signal modulated by its temporal envelope. Our approach (first introduced in [6]) differs from [4] in use of frequency domain linear prediction (FDLP) [7–10], that allows for the approximation of temporal (Hilbert) envelopes of sub-band energies by an autoregressive (AR) model. Unlike temporal noise shaping (TNS) [7], which also uses FDLP and forms a part of the MPEG-2/4 AAC codec, where FDLP is applied to solve problems with transient attacks (impulses), the proposed codec employs FDLP to approximate relatively long (hundreds of milliseconds) segments of Hilbert envelopes in individual frequency sub-bands. Another approach, described in [11], exploits FDLP for sinusoidal audio coding using short-term segments.
The goal is to develop a novel wide-band (WB)-FDLP audio coding system that would explore new potentials in encoding mixed input including speech and audio by taking into account relatively long acoustic context directly in the initial step of encoding the input signal. Due to this acoustic context, the proposed coding technique is intended to be exploited in noninteractive audio services. Unlike interactive audio services such as VoIP or interactive games, the real-time constraints for the proposed codec are not stringent.
The paper is organized as follows. Section 2 discusses fundamental aspects of the FDLP technique. Section 3 mentions initial attempts to exploit FDLP for narrow-band speech coding. Section 4 describes the WB-FDLP audio codec in general and Section 5 gives the detailed description of the major blocks in the codec. Objective quality evaluations of the individual blocks are given in Section 6. Section 7 provides subjective quality assessment of the proposed codec compared with state-of-the-art MPEG audio codecs. Section 8 contains discussions and summarizes important aspects.
2. Frequency-Domain Linear Prediction (FDLP)
Inertia of the human vocal tract organs makes the modulations in the speech signal vary gradually. While short-term predictability within time spans of 10–20 ms and AR modeling of the signal have been used effectively [12, 13], there exists a longer-term predictability due to inertia of human vocal organs and their neural control mechanisms. Therefore, the temporal evolutions of vocal tract shapes (and subsequently also of the short-term spectral envelopes of the signal) are predictable. In terms of compression efficiency, it is desirable to capitalize on this predictability by processing longer temporal context for coding rather than processing every short-term segments independently. While such an approach obviously introduces longer algorithmic delay, the efficiency gained may justify its deployment in many evolving communications applications. Initial encouraging experimental results were achieved on very low bit-rate speech coding [6] and feature extraction for automatic speech recognition [14].
In the proposed audio codec, we utilize the concept of linear prediction in spectral domain on sub-band signals. After decomposing the signal into the individual critical bandwidth sub-bands, the sub-band signals are characterized by their envelope (amplitude) and carrier (phase) modulations. FDLP is then able to exploit the predictability of slowly varying amplitude modulations. Spectral representation of amplitude modulation in sub-bands, also called "Modulation Spectra'', has been used in many engineering applications. Early work done in [15] for predicting speech intelligibility and characterizing room acoustics is now widely used in the industry [16]. Recently, there have been many applications of such concepts for robust speech recognition [17, 18], audio coding [4], noise suppression [19], and so forth. In order to use information in modulation spectrum (at important frequencies starting from low range), a signal over relatively long-time scales has to be processed. This is also the case of FDLP.
Defining the analytic signal in the sub-band as  , where
, where  is the Hilbert transform of
is the Hilbert transform of  , the Hilbert envelope of
, the Hilbert envelope of  is defined as
is defined as  (squared magnitude of the analytic signal) and the phase is represented by instantaneous frequency, denoted by the first derivative of
(squared magnitude of the analytic signal) and the phase is represented by instantaneous frequency, denoted by the first derivative of  (scaled by
(scaled by  ). Often, the term Hilbert carrier denoted as
). Often, the term Hilbert carrier denoted as  is used for representing the phase. Here,
is used for representing the phase. Here,  denotes time samples.
denotes time samples.
As it will be shown in Section 2.1, FDLP parameterizes the Hilbert envelope of the input signal  . FDLP can be seen as a method analogous to temporal domain linear prediction (TDLP) [20]. In the case of TDLP, the AR model approximates the power spectrum of the input signal. The FDLP fits an AR model to the Hilbert envelope of the input signal. Using FDLP we can adaptively capture fine temporal details with high temporal resolution. At the same time, FDLP summarizes the temporal evolution of the signal over hundreds of milliseconds. Figure 1 shows an example of speech signal, its Hilbert envelope (obtained using the technique based on discrete Fourier transform [9]), and AR model estimated by FDLP.
. FDLP can be seen as a method analogous to temporal domain linear prediction (TDLP) [20]. In the case of TDLP, the AR model approximates the power spectrum of the input signal. The FDLP fits an AR model to the Hilbert envelope of the input signal. Using FDLP we can adaptively capture fine temporal details with high temporal resolution. At the same time, FDLP summarizes the temporal evolution of the signal over hundreds of milliseconds. Figure 1 shows an example of speech signal, its Hilbert envelope (obtained using the technique based on discrete Fourier transform [9]), and AR model estimated by FDLP.

Illustration of the AR modeling property of FDLP: (a) a portion of speech signal, (b) its Hilbert envelope, and (c) all-pole model obtained using FDLP.
2.1. Envelope Estimation
In this section, we describe, in detail, the approximation of temporal envelopes by AR model obtained using FDLP. To simplify the notation, we present the full-band version of the technique. The sub-band version is identical except that the technique is applied to the sub-band signal obtained by a filter bank decomposition.
In the previous section, we defined the input discrete time-domain sequence as  for time samples
for time samples  , where
, where  denotes the segment length. Its Fourier power spectrum
denotes the segment length. Its Fourier power spectrum  (sampled at discrete frequencies
(sampled at discrete frequencies  ;
;  ) is given as
) is given as

where  .
.  stands for the
stands for the  -transform. Let the notation
-transform. Let the notation  denote discrete Fourier transform (DFT) which is equivalent to
denote discrete Fourier transform (DFT) which is equivalent to  -transform with
-transform with  .
.
It has been shown, for example, in [20], that the conventional TDLP fits the discrete power spectrum of an all-pole model  to
to  of the input signal. Unlike TDLP, where the time-domain sequence
of the input signal. Unlike TDLP, where the time-domain sequence  is modeled by linear prediction, FDLP applies linear prediction on the frequency-domain representation of the sequence. In our case,
is modeled by linear prediction, FDLP applies linear prediction on the frequency-domain representation of the sequence. In our case,  is first transformed by discrete cosine transform (DCT). It can be shown that the DCT type I odd (DCT-Io) needs to be used [21]. DCT-Io can also be viewed as the symmetrical extension of
is first transformed by discrete cosine transform (DCT). It can be shown that the DCT type I odd (DCT-Io) needs to be used [21]. DCT-Io can also be viewed as the symmetrical extension of  so that a new time-domain sequence
so that a new time-domain sequence  is obtained (
is obtained ( , and
, and  ) and then DFT projected (i.e., relationship between the DFT and the DCT-Io). We obtain the real-valued sequence
) and then DFT projected (i.e., relationship between the DFT and the DCT-Io). We obtain the real-valued sequence  , where
, where  . Process of symmetrical extension allows to avoid problems with continuity at boundaries of the time signal (often called Gibbs-type ringing).
. Process of symmetrical extension allows to avoid problems with continuity at boundaries of the time signal (often called Gibbs-type ringing).
We then estimate the frequency-domain prediction error  as a linear combination of
as a linear combination of  consisting of
consisting of  real prediction coefficients
real prediction coefficients  :
:

 are found so that the squared prediction error is minimized [20]. In the case of TDLP, minimizing the total error is equivalent to the minimization of the integrated ratio of the signal spectrum
are found so that the squared prediction error is minimized [20]. In the case of TDLP, minimizing the total error is equivalent to the minimization of the integrated ratio of the signal spectrum  to its model approximation
to its model approximation 

In the case of FDLP, we can interpret  as a discrete, real, causal, and stable sequence (consisting of frequency samples). Its discrete power spectrum will be estimated through the concept of discrete Hilbert transform relationships [22].
as a discrete, real, causal, and stable sequence (consisting of frequency samples). Its discrete power spectrum will be estimated through the concept of discrete Hilbert transform relationships [22].  can be expressed as the sum of
can be expressed as the sum of  and
and  , denoting an even sequence and an odd sequence, respectively; thus
, denoting an even sequence and an odd sequence, respectively; thus  . Its Fourier transform
. Its Fourier transform

where  and
and  stand for real and imaginary parts of
stand for real and imaginary parts of  , respectively. It has been shown (e.g., [22]) that
, respectively. It has been shown (e.g., [22]) that  and
and  . By taking the Fourier transform of
. By taking the Fourier transform of  , the original sequence
, the original sequence  is obtained
is obtained

 stands for a constant. The relations between
stands for a constant. The relations between  and
and  , called the Kramers-Kronig relations, are given by the discrete Hilbert transform (partial derivatives of real and imaginary parts of an analytic function [23]), thus
, called the Kramers-Kronig relations, are given by the discrete Hilbert transform (partial derivatives of real and imaginary parts of an analytic function [23]), thus

where  stands for Hilbert transformation.
stands for Hilbert transformation.  is called the Hilbert envelope (squared magnitude of the analytic signal
is called the Hilbert envelope (squared magnitude of the analytic signal  ). Prediction error is proportional to the integrated ratio of
). Prediction error is proportional to the integrated ratio of  and its FDLP approximation
and its FDLP approximation 

 stands for squared magnitude frequency response of the all-pole model. Equation (7) can be interpreted in such a way that the FDLP all-pole model fits Hilbert envelope of the symmetrically extended time-domain sequence
stands for squared magnitude frequency response of the all-pole model. Equation (7) can be interpreted in such a way that the FDLP all-pole model fits Hilbert envelope of the symmetrically extended time-domain sequence  . FDLP models the time-domain envelope in the same way as TDLP models the spectral envelope. Therefore, the same properties appear, such as accurate modeling of peaks rather than dips.
. FDLP models the time-domain envelope in the same way as TDLP models the spectral envelope. Therefore, the same properties appear, such as accurate modeling of peaks rather than dips.
Further, the Hilbert envelope  is available and can be modified (before applying linear prediction). Thus, for example, compressing
is available and can be modified (before applying linear prediction). Thus, for example, compressing  by a root function
by a root function  turns (7) into
turns (7) into

As a consequence, the new model will fit dips more accurately than the original model. This technique has been proposed for TDLP (called spectral transform linear prediction (STLP) [24]), and we apply this scheme for FDLP.
3. FDLP for Narrow-Band Speech Coding
Initial experiments aiming at narrow-band (NB) speech coding ( kHz), reported in [6], suggest that FDLP applied on long temporal segments and excited with white noise signal provides a highly intelligible speech, but with whisper-like quality without any voicing at bit-rates below
kHz), reported in [6], suggest that FDLP applied on long temporal segments and excited with white noise signal provides a highly intelligible speech, but with whisper-like quality without any voicing at bit-rates below  kbps. In these experiments, the input speech was split into nonoverlapping segments (hundreds of milliseconds long). Then, each segment was processed by DCT and partitioned into unequal frequency subsegments to obtain critical band-sized subbands. FDLP approximation was applied on each sub-band by carrying out autocorrelation linear prediction (LP) analysis on the subsegments of DCT transformed signals, yielding line spectral pair (LSP) descriptors of FDLP models. Resulting AR models approximate the Hilbert envelopes in critical band-sized sub-bands.
kbps. In these experiments, the input speech was split into nonoverlapping segments (hundreds of milliseconds long). Then, each segment was processed by DCT and partitioned into unequal frequency subsegments to obtain critical band-sized subbands. FDLP approximation was applied on each sub-band by carrying out autocorrelation linear prediction (LP) analysis on the subsegments of DCT transformed signals, yielding line spectral pair (LSP) descriptors of FDLP models. Resulting AR models approximate the Hilbert envelopes in critical band-sized sub-bands.
In case of very low bit-rate speech coding ( 1 kbps), a frequency decomposition into
1 kbps), a frequency decomposition into  sub-bands was performed for every
sub-bands was performed for every  ms long input segment. In each sub-band, the FDLP model of order of
ms long input segment. In each sub-band, the FDLP model of order of  was estimated. FDLP sub-band residuals (these signals represent sub-band Hilbert carriers for the sub-band FDLP encoded Hilbert envelopes) were substituted by white noise with uniform distribution. Such an algorithm provided subjectively much more natural signal than LPC10 standard (utilizing TDLP with order model equal to
was estimated. FDLP sub-band residuals (these signals represent sub-band Hilbert carriers for the sub-band FDLP encoded Hilbert envelopes) were substituted by white noise with uniform distribution. Such an algorithm provided subjectively much more natural signal than LPC10 standard (utilizing TDLP with order model equal to  estimated every
estimated every  ms) operating at twice higher bit-rates [6].
ms) operating at twice higher bit-rates [6].
For NB speech applications operating at  kHz input signal, the sub-band residuals were split into equal length partially (5%—to avoid transient noise) overlapping segments. Each segment was heterodyned to DC range and Fourier transformed to yield spectral components of low-passed sub-band residuals. Commensurate number of spectral components in each sub-band was selected (using psychoacoustic model) and their parameters were vector quantized. In the decoder, the sub-band residuals were reconstructed and modulated with corresponding FDLP envelope. Individual DCT contributions from each critical sub-band were summed and inverse DCT was applied to reconstruct output signal [25].
kHz input signal, the sub-band residuals were split into equal length partially (5%—to avoid transient noise) overlapping segments. Each segment was heterodyned to DC range and Fourier transformed to yield spectral components of low-passed sub-band residuals. Commensurate number of spectral components in each sub-band was selected (using psychoacoustic model) and their parameters were vector quantized. In the decoder, the sub-band residuals were reconstructed and modulated with corresponding FDLP envelope. Individual DCT contributions from each critical sub-band were summed and inverse DCT was applied to reconstruct output signal [25].
4. From NB to WB-FDLP Audio Codec
The first experiment towards wide-band (WB)-FDLP audio coding ( kHz input signal) was motivated by the structure of the NB-FDLP speech codec operating at
kHz input signal) was motivated by the structure of the NB-FDLP speech codec operating at  kHz. The initial frequency sub-band decomposition based on weighting of DCT transformed signal was extended (by adding more critical sub-bands) to encode wide-band input [26].
kHz. The initial frequency sub-band decomposition based on weighting of DCT transformed signal was extended (by adding more critical sub-bands) to encode wide-band input [26].
In [27], a more efficient FDLP-based version for WB audio coding was introduced. Initial critical bandwidth sub-band decomposition was replaced by quadrature mirror filter (QMF) bank. Then, FDLP was applied directly on QMF sub-band signals. Similar to the previous schemes, the sub-band FDLP residuals (the carrier signals for the FDLP-encoded Hilbert envelope) were further processed (more detailed description is given in Section 4.1). This WB-FDLP audio coding approach exploiting QMF-bank decomposition serves as a simplified version (base-line system) of the current WB-FDLP audio codec.
The WB-FDLP approach is further improved by several additional blocks, described later, to operate at  kbps for audio signals sampled at
kbps for audio signals sampled at  kHz. The encoder and decoder sides are described in the following sections.
kHz. The encoder and decoder sides are described in the following sections.
4.1. Encoder
The block diagram of the WB-FDLP encoder is shown in Figure 2. On the encoder side, the full-band input signal is decomposed into QMF sub-bands. In each sub-band, FDLP technique is applied to approximate relatively long temporal sub-band envelopes ( ms). Resulting line spectral frequencies (LSFs) [28] approximating the sub-band temporal envelopes are quantized using split vector quantization (VQ) and selected codebook indices are transmitted to the decoder. Order of AR models is equal to
ms). Resulting line spectral frequencies (LSFs) [28] approximating the sub-band temporal envelopes are quantized using split vector quantization (VQ) and selected codebook indices are transmitted to the decoder. Order of AR models is equal to  . This number is a result obtained from optimization experiments, not reported here. The codebook used to quantize LSFs is trained across all QMF sub-bands using a set of audio samples different from those used for objective and subjective quality evaluations.
. This number is a result obtained from optimization experiments, not reported here. The codebook used to quantize LSFs is trained across all QMF sub-bands using a set of audio samples different from those used for objective and subjective quality evaluations.

Graphical scheme of the WB-FDLP encoder.
LSFs are restored back at the encoder side and resulting AR model computed from quantized parameters is used to derive FDLP sub-band residuals (analysis-by-synthesis). Due to this operation, the quantization noise present in the sub-band temporal envelopes does not influence the reconstructed signal quality.
The sub-band FDLP residuals are derived by filtering the sub-band signal by the inverse FDLP filter. In order to take into account nonstationarity of the Hilbert carrier, FDLP residuals are split into  ms long subsegments with
ms long subsegments with  ms overlap. This ensures smooth transitions when the subsegments of the residual signal are concatenated in the decoder. Each subsegment is transformed into DFT domain. Magnitude spectral parameters are quantized using VQ. Phase spectral components of sub-band residuals are scalar quantized (SQ). In general, the number of levels in quantization differs for different sub-bands. Lower-frequency sub-bands are quantized more accurately whereas the higher sub-bands exploit alternative techniques to reduce the overall bit rates. More specifically:
ms overlap. This ensures smooth transitions when the subsegments of the residual signal are concatenated in the decoder. Each subsegment is transformed into DFT domain. Magnitude spectral parameters are quantized using VQ. Phase spectral components of sub-band residuals are scalar quantized (SQ). In general, the number of levels in quantization differs for different sub-bands. Lower-frequency sub-bands are quantized more accurately whereas the higher sub-bands exploit alternative techniques to reduce the overall bit rates. More specifically:
-
(i)
Magnitudes: Since a full-search VQ in this high-dimensional space would be computationally demanding, split VQ approach is employed. Although the split VQ approach is suboptimal, it reduces computational complexity and memory requirements to manageable limits without severely affecting the VQ performance. We divide the input vector of spectral magnitudes into separate partitions of a lower dimension. Dimension of individual partitions varies with the frequency sub-band. In sub-bands 1–10, the input vector of spectral magnitudes is split into
 partitions (minimum codebook length is
partitions (minimum codebook length is 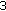 ). Spectral magnitudes in higher sub-bands are quantized less accurately, that is, the VQ codebook length increases. In overall, the VQ codebooks are trained (on a large audio database) for each partition using the LBG algorithm.
). Spectral magnitudes in higher sub-bands are quantized less accurately, that is, the VQ codebook length increases. In overall, the VQ codebooks are trained (on a large audio database) for each partition using the LBG algorithm. -
(ii)
Phases: The distribution of the phase spectral components was found to be approximately uniform (having a high entropy). Their correlation across time is not significant. Hence a uniform SQ is employed for encoding the phase spectral components. The SQ resolution varies from
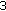 to
to 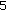 bits, depending on the energy levels given by the corresponding spectral magnitudes, and is performed by a technique called dynamic phase quantization (DPQ). DPQ is described in detail in Section 5.2.
bits, depending on the energy levels given by the corresponding spectral magnitudes, and is performed by a technique called dynamic phase quantization (DPQ). DPQ is described in detail in Section 5.2.
 partitions (minimum codebook length is
partitions (minimum codebook length is 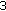 ). Spectral magnitudes in higher sub-bands are quantized less accurately, that is, the VQ codebook length increases. In overall, the VQ codebooks are trained (on a large audio database) for each partition using the LBG algorithm.
). Spectral magnitudes in higher sub-bands are quantized less accurately, that is, the VQ codebook length increases. In overall, the VQ codebooks are trained (on a large audio database) for each partition using the LBG algorithm.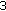 to
to 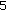 bits, depending on the energy levels given by the corresponding spectral magnitudes, and is performed by a technique called dynamic phase quantization (DPQ). DPQ is described in detail in Section 5.2.
bits, depending on the energy levels given by the corresponding spectral magnitudes, and is performed by a technique called dynamic phase quantization (DPQ). DPQ is described in detail in Section 5.2.To reduce bit rates, we apply an additional block, namely temporal masking (TM) which, together with DPQ, can efficiently control process of quantization. This block is described in Section 5.5. Furthermore, a technique called spectral noise shaping (SNS, Section 5.4) is applied for improving the quality of tonal signals by applying a TDLP filter prior to the FDLP processing. Detection of tonality followed by SNS is performed in each frequency sub-band independently.
4.2. Decoder
The block diagram of the WB-FDLP decoder is shown in Figure 3. On the decoder side, sub-band residuals are reconstructed by inverse quantization and are then modulated by temporal envelope given by FDLP model. FDLP model parameters are obtained from quantized LSFs.

Graphical scheme of the WB-FDLP decoder.
More specifically, the transmitted VQ codebook indices are used to select appropriate codebook vectors for the magnitude spectral components.  ms segments of the sub-band residuals are restored in the time domain from its spectral magnitude and phase information. Overlap-add (OLA) technique is applied to obtain
ms segments of the sub-band residuals are restored in the time domain from its spectral magnitude and phase information. Overlap-add (OLA) technique is applied to obtain  ms sub-band residuals, which are then modulated by the FDLP envelope to obtain the reconstructed sub-band signal.
ms sub-band residuals, which are then modulated by the FDLP envelope to obtain the reconstructed sub-band signal.
An additional step of bit-rate reduction is performed on the decoder side (see Section 5.3). FDLP residuals in frequency sub-bands above  kHz are not transmitted, but they are substituted by white noise at the decoder. Subsequently, these residuals are modulated by corresponding sub-band FDLP envelopes.
kHz are not transmitted, but they are substituted by white noise at the decoder. Subsequently, these residuals are modulated by corresponding sub-band FDLP envelopes.
Finally, a block of QMF synthesis is applied on the reconstructed sub-band signals to produce the output full-band signal.
5. Individual Blocks in WB-FDLP Audio Codec
This section describes, in detail, the major blocks employed in WB-FDLP audio codec mentioned in Section 4.
5.1. Nonuniform Sub-Band Decomposition
The original sub-band decomposition in NB-FDLP speech codec was based on weighting of DCT sequence estimated from long-term full-band input signal by set of Gaussian windows [6]. In order to obtain nonuniform frequency sub-bands, Gaussian windows were distributed in a nonuniform way following the Bark warping function

where  and
and  are frequency axes in Hertz and in bark, respectively.
are frequency axes in Hertz and in bark, respectively.
A higher efficiency is achieved by replacing the original sub-band decomposition by nonuniform QMF bank [29]. QMF provides the sub-band sequences which form a critically sampled and maximally decimated signal representation (i.e., the number of sub-band samples is equal to the number of input samples). In nonuniform QMF, the input audio (sampled at  kHz) is split into
kHz) is split into  ms long frames. Each frame is decomposed into
ms long frames. Each frame is decomposed into  nonuniform sub-bands. An initial decomposition with a 6 stage tree-structured uniform QMF analysis gives
nonuniform sub-bands. An initial decomposition with a 6 stage tree-structured uniform QMF analysis gives  uniformly spaced sub-bands. A nonuniform QMF decomposition into 32 frequency sub-bands is obtained by merging these
uniformly spaced sub-bands. A nonuniform QMF decomposition into 32 frequency sub-bands is obtained by merging these  uniform QMF sub-bands [30]. This tying operation is motivated by critical band decomposition in the human auditory system. This means that more sub-bands at higher frequencies are merged together while maintaining perfect reconstruction. Magnitude frequency responses of the first four QMF filters are given in Figure 4.
uniform QMF sub-bands [30]. This tying operation is motivated by critical band decomposition in the human auditory system. This means that more sub-bands at higher frequencies are merged together while maintaining perfect reconstruction. Magnitude frequency responses of the first four QMF filters are given in Figure 4.

Magnitude frequency response of first four QMF bank filters (filter length N = 99).
Unlike NB-FDLP coder, DCT is applied on the  ms long sub-band signal to obtain AR model in a given QMF sub-band. STLP technique (introduced in (8)) is used to control the fit of AR model.
ms long sub-band signal to obtain AR model in a given QMF sub-band. STLP technique (introduced in (8)) is used to control the fit of AR model.
Such nonuniform QMF decomposition provides good compromise between fine spectral resolution for low-frequency sub-bands and smaller number of FDLP parameters for higher bands. Furthermore, nonuniform QMF decomposition fits well into the perceptual audio coding scheme, where psychoacoustic models traditionally work in nonuniform (critical) sub-bands.
5.2. Dynamic Phase Quantization (DPQ)
To reduce bit rate for representing phase spectral components of the sub-band FDLP residuals, we perform DPQ. DPQ can be seen as a special case of magnitude-phase polar quantization applied to audio coding [31].
In DPQ, graphically shown in Figure 5, phase spectral components corresponding to relatively low-magnitude spectral components are transmitted with lower resolution, that is, the codebook vector selected from the magnitude codebook is processed by "adaptive thresholding'' in the encoder as well as in the decoder [25]. The threshold determines the resolution of quantization levels in uniform SQ. The threshold is dynamically adapted to meet a required number of phase spectral components for a given resolution. For frequency sub-bands below  kHz, phase spectral components corresponding to the highest magnitudes are quantized with 5 bits, those corresponding to the lowest are quantized with 3 bits. For frequency sub-bands above
kHz, phase spectral components corresponding to the highest magnitudes are quantized with 5 bits, those corresponding to the lowest are quantized with 3 bits. For frequency sub-bands above  kHz, the highest resolution is
kHz, the highest resolution is  bits.
bits.

Time-frequency characteristics obtained from a randomly selected audio example: (a) 1000 ms segment of the Hilbert envelope (estimated from the squared magnitude of an analytic signal) computed for the 3rd QMF sub-band, and its FDLP approximation (b) magnitude Fourier spectral components of the 200 ms subsegment of the sub-band FDLP residual signal and its reconstructed version, adaptive thresholds for DPQ (5, 4 bits) are also shown (c) phase Fourier spectral components of the 200 ms subsegment of the sub-band FDLP residual signal and its reconstructed version and (d) original 200 ms subsegment of the sub-band FDLP residual signal and its reconstructed version.
As DPQ follows an analysis-by-synthesis (AbS) scheme, no side information needs to be transmitted. This means that frequency positions of the phase components being dynamically quantized using different resolution do not have to be transmitted. Such information is available at the decoder side due to the perfect (lossless) reconstruction of magnitude components processed by AbS scheme.
5.3. White Noise Substitution
The detailed analysis of sub-band FDLP residuals shows that FDLP residuals from low-frequency sub-bands resemble FM modulated signals. However, in high-frequency sub-bands, the FDLP residuals have properties of white noise. According to these findings, we substitute FDLP residuals in frequency sub-bands above  kHz (last
kHz (last  bands) for white noise generated at the decoder side. These white noise residuals are then modulated by corresponding sub-band FDLP envelopes. White noise substitution of high-sub-band residuals has a minimum impact on the quality of reconstructed audio (even for tonal signals) while providing a significant bit-rate reduction.
bands) for white noise generated at the decoder side. These white noise residuals are then modulated by corresponding sub-band FDLP envelopes. White noise substitution of high-sub-band residuals has a minimum impact on the quality of reconstructed audio (even for tonal signals) while providing a significant bit-rate reduction.
5.4. Spectral Noise Shaping (SNS)
The FDLP codec is most suitable to encode signals, such as glockenspiel, having impulsive temporal content, that is, signals whose sub-band instantaneous energies can be characterized by an AR model. Therefore, FDLP is robust to "pre-echo'' [7, 26] (i.e., quantization noise is spread before the onset of the signal and may even exceed the original signal components in level during certain time intervals). However, for signals having impulsive spectral content, such as tonal signals, FDLP modeling approach is not appropriate. Here, most of the important signal information is present in the FDLP residual. For such signals, the quantization error in the FDLP codec spreads across all the frequencies around the tone. This results in significant degradation in the reconstructed signal quality.
This can be seen as the dual problem to encoding transients in the time domain, as done in many conventional codecs such as [3]. This is efficiently solved by temporal noise shaping (TNS) [7]. Specifically, coding artifacts arise mainly in handling transient signals (like the castanets) and pitched signals. Using spectral signal decomposition for quantization and encoding implies that a quantization error introduced in this domain will spread out in time after reconstruction by the synthesis filter bank. This phenomenon is called time/frequency uncertainty principle [32] and can cause "pre-echo'' artifacts (i.e., a short noise-like event preceding a signal onset) which can be easily perceived. TNS represents a solution to overcome this problem by shaping the quantization noise in the time domain according to the input transient.
The proposed WB-FDLP audio codec exploits SNS technique to overcome problems in encoding tonal signals [33]. It is based on the fact that tonal signals are highly predictable in the time domain. If a sub-band signal is found to be tonal, it is analyzed using TDLP [20] and the residual of this operation is processed with the FDLP codec. At the decoder, the output of the FDLP codec is filtered by the inverse TDLP filter.
Since the inverse TDLP (AR) filter follows the spectral impulses for tonal signals, it shapes the quantization noise according to the input signal. General scheme of SNS module employed in WB-FDLP codec is given in Figure 6. SNS module consists of two blocks.

WB-FDLP codec with SNS.
-
(i)
Tonality detector (TD): TD identifies the QMF sub-band signals which have strong tonal components. Since FDLP performs well on nontonal and partially tonal signals, TD ensures that only pure tonal signals are identified. For this purpose, global tonality detector (GTD) and local tonality detector (LTD) measures are computed and the tonality decision is taken based on both measures. GTD measure is based on the spectral flatness measure (SFM, defined as the ratio of the geometric mean to the arithmetic mean of the spectral magnitudes) of the full-band signal. If the SFM is below the threshold, that is, GTD has identified input frame as tonal, LTD is employed. LTD is defined based on the spectral autocorrelation of the sub-band signals (used for estimation of FDLP envelopes).
-
(ii)
SNS processing: If GTD and LTD have identified a sub-band signal to have a tonal character, such sub-band signal is filtered through the TDLP filter followed by FDLP model. Model orders of both models are equal to
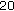 as compared to a FDLP model order of
as compared to a FDLP model order of 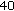 for the nontonal signals. At the decoder side, inverse TDLP filtering on the FDLP decoded signal gives the sub-band signal back.
for the nontonal signals. At the decoder side, inverse TDLP filtering on the FDLP decoded signal gives the sub-band signal back.
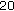 as compared to a FDLP model order of
as compared to a FDLP model order of 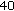 for the nontonal signals. At the decoder side, inverse TDLP filtering on the FDLP decoded signal gives the sub-band signal back.
for the nontonal signals. At the decoder side, inverse TDLP filtering on the FDLP decoded signal gives the sub-band signal back.Improvements in reconstruction quality can be seen in Figure 7. For time-domain predicted signals, its TDLP filter has magnitude response characteristics similar to the power spectral density (PSD) of the input signal. As an example, Figure 8 shows the power spectrum of a tonal sub-band signal and the frequency response of the TDLP filter for this sub-band signal. Since the quantization noise passes through the inverse TDLP filter, it gets shaped in the frequency domain according to the PSD of the input signal.

Improvements in reconstruction signal quality with SNS: A portion of power spectrum of (a) a tonal input signal, (b) reconstructed signal using the WB-FDLP codec without SNS, and (c) reconstructed signal using the WB-FDLP codec with SNS.

TDLP filter used for SNS: (a) Power spectrum of tonal sub-band signal, and (b) magnitude response of the inverse TDLP filter in SNS.
5.5. Temporal Masking (TM)
A perceptual model, which performs temporal masking, is applied in WB-FDLP codec to reduce bit-rates. Temporal masking is a property of the human ear, where the sounds appearing within a temporal interval of about  ms after a signal component get masked. Such auditory masking property provides an efficient solution for quantization of a signal.
ms after a signal component get masked. Such auditory masking property provides an efficient solution for quantization of a signal.
By processing relatively long temporal segments in frequency sub-bands, the FDLP audio codec allows for a straightforward exploitation of the temporal masking, while its implementation in more conventional short-term spectra based codecs has been so far quite limited; one notable exemption is the recently proposed wavelet-based codec [34].
The amount of forward masking is determined by the interaction of a number of factors including masker level, the temporal separation of the masker and the signal, frequency of the masker and the signal, and duration of the masker and the signal. We exploit linear forward masking model proposed in [35] to the sub-band FDLP residual signals. More particularly, a simple first order mathematical model, which provides a sufficient approximation for the amount of temporal masking is used

where  is the temporal mask in dB sound pressure level (SPL),
is the temporal mask in dB sound pressure level (SPL),  is the signal in dB SPL,
is the signal in dB SPL,  is the sample index,
is the sample index,  is the time delay in ms,
is the time delay in ms,  ,
,  , and
, and  are the constants. At any sample point, multiple mask estimates arising from the several previous samples are present and the maximum of them is chosen as the mask in dB SPL at that point. The optimal values of these parameters, as defined in [34], are as follows:
are the constants. At any sample point, multiple mask estimates arising from the several previous samples are present and the maximum of them is chosen as the mask in dB SPL at that point. The optimal values of these parameters, as defined in [34], are as follows:

where  is the center frequency of the sub-band in kHz and
is the center frequency of the sub-band in kHz and  ,
,  , and
, and  are constants. The constant
are constants. The constant  is obtained from the duration of the temporal masking and may be chosen as
is obtained from the duration of the temporal masking and may be chosen as  . The parameter
. The parameter  is the absolute threshold of hearing (ATH) in quiet, defined as
is the absolute threshold of hearing (ATH) in quiet, defined as

To estimate the masking threshold at each sample index, we compute a short-term dB SPL so that the signal is divided into  ms overlapping frames with frame shifts of
ms overlapping frames with frame shifts of  sample.
sample.
The assumptions made in the applied linear model, such as sinusoidal nature of the masker and the signal, minimum duration of the masker ( ms), and minimum duration of the signal (
ms), and minimum duration of the signal ( ms) may differ from real audio signal encoding conditions. Therefore, the actual masking thresholds are much below the thresholds obtained from the linear masking model. To obtain the actual thresholds, informal listening experiments were conducted to determine the correction factors [36].
ms) may differ from real audio signal encoding conditions. Therefore, the actual masking thresholds are much below the thresholds obtained from the linear masking model. To obtain the actual thresholds, informal listening experiments were conducted to determine the correction factors [36].
These masking thresholds are then utilized in quantizing the sub-band FDLP residual signals. The number of bits required for representing the sub-band FDLP residuals is reduced in accordance with TM thresholds compared to the WB-FDLP codec without TM. Since the sub-band signal is the product of its FDLP envelope and residual (carrier), the masking thresholds for the residual signal are obtained by subtracting the dB SPL of the envelope from that of the sub-band signal. First, we estimate the quantization noise present in the WB-FDLP codec without TM. If the mean of the quantization noise (in  ms sub-band signal) is above the masking threshold, no bit-rate reduction is applied. If the temporal mask mean is above the noise mean, then the amount of bits needed to encode that sub-band FDLP residual signal is reduced in such a way that the noise level becomes similar to the masking threshold.
ms sub-band signal) is above the masking threshold, no bit-rate reduction is applied. If the temporal mask mean is above the noise mean, then the amount of bits needed to encode that sub-band FDLP residual signal is reduced in such a way that the noise level becomes similar to the masking threshold.
An example of application of TM is shown in Figure 9. We plot a region of the  ms sub-band signal and the quantization noise before and after applying TM. As can be seen, in some regions, the instantaneous quantization noise levels present in the FDLP codec after applying TM can be slightly higher than corresponding TM thresholds. However, the mean of the quantization noise is smaller than the mean of TM threshold over the whole
ms sub-band signal and the quantization noise before and after applying TM. As can be seen, in some regions, the instantaneous quantization noise levels present in the FDLP codec after applying TM can be slightly higher than corresponding TM thresholds. However, the mean of the quantization noise is smaller than the mean of TM threshold over the whole  ms long-time segment. Since the information regarding the number of quantization bits needs to be transmitted to the receiver, the bit-rate reduction is done in a discretized manner. Due to that, the quantization noise needs to be only roughly estimated (over the whole segment) and the mean value is compared to the mean TM threshold. Specifically, in the WB-FDLP codec, the bit-rate reduction is done in
ms long-time segment. Since the information regarding the number of quantization bits needs to be transmitted to the receiver, the bit-rate reduction is done in a discretized manner. Due to that, the quantization noise needs to be only roughly estimated (over the whole segment) and the mean value is compared to the mean TM threshold. Specifically, in the WB-FDLP codec, the bit-rate reduction is done in  different levels (in which the first level corresponds to no bit-rate reduction).
different levels (in which the first level corresponds to no bit-rate reduction).

Application of temporal masking (TM) to reduce the bits for 200 ms region of a high energy sub-band signal. The figure shows the temporal masking threshold for a high-energy region of sub-band signal, quantization noise for the WB-FDLP codec without TM and for the codec with TM.
6. Bit Rate versus Quality of the Individual Blocks
To evaluate individual blocks employed in WB-FDLP codec, we perform quality assessment and provide achieved results with obtained bit-rate reductions. For the quality assessment, perceptual evaluation of audio quality (PEAQ) distortion measure [37] is used. PEAQ measure, based on the ITU-R BS.1387 standard, estimates the perceptual degradation of the test signal with respect to the reference signal. The output combines a number of model output variables (MOVs) into a single measure, the objective difference grade (ODG) score, which is an impairment scale with meanings shown in Table 2.
PEAQ evaluations are performed on  challenging audio recordings sampled at
challenging audio recordings sampled at  kHz. These audio samples form part of the MPEG framework for exploration of speech and audio coding [38]. They are comprised of speech, music, and speech over music recordings, specifically mentioned in Table 1.
kHz. These audio samples form part of the MPEG framework for exploration of speech and audio coding [38]. They are comprised of speech, music, and speech over music recordings, specifically mentioned in Table 1.
 audio/speech recordings selected for objective quality assessment.
audio/speech recordings selected for objective quality assessment.  denotes
denotes  recordings used in MUSHRA subjective listening test.
recordings used in MUSHRA subjective listening test.  denotes
denotes  recordings used in BS.1116 subjective listening test.
recordings used in BS.1116 subjective listening test.Mean values and 95% confidence intervals of ODG scores obtained by PEAQ measure for 27 audio samples are shown in Figure 10 for the various WB-FDLP codec versions.

PEAQ (ODG) scores: mean values and 95% confidence intervals estimated over 27 audio recordings to evaluate individual blocks of WB-FDLP codec (see Section 6). We add results for MPEG-4 HE-AAC and LAME-MP3 codecs. PEAQ (ODG) score meanings are given in Table 2.
-
(a)
Base-Line System (170 kbps) This version of the codec employs uniform QMF decomposition and DFT magnitudes of sub-band residuals are quantized using split VQ. Quantization of the spectral magnitudes using the split VQ allocates about
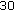 kbps for all the frequency sub-bands. DFT phases are uniformly quantized using
kbps for all the frequency sub-bands. DFT phases are uniformly quantized using  bits. Such codec operates at
bits. Such codec operates at 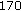 kbps [27].
kbps [27]. -
(b)
Nonuniform QMF Decomposition (104 kbps) Employment of nonuniform QMF bank decomposition (Section 5.1) significantly reduces the bit rates from
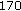 kbps to
kbps to 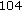 kbps (about
kbps (about 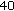 %), while the overall objective quality is degraded by about
%), while the overall objective quality is degraded by about  .
. -
(c)
Dynamic Phase Quantization (DPQ) (84 kbps) Employment of DPQ (Section 5.2) provides bit-rate reduction about
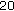 kbps (from
kbps (from 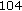 to
to  kbps), while the overall objective quality is degraded by about
kbps), while the overall objective quality is degraded by about 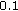 .
. -
(d)
Noise Substitution (73 kbps) Subsequent white noise substitution of high-frequency sub-band FDLP residuals (Section 5.3) reduces the bit rate to
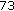 kbps (by about
kbps (by about 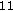 kbps), while the overall objective quality is degraded by about
kbps), while the overall objective quality is degraded by about 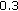 .
. -
(e)
Spectral Noise Shaping (SNS) (73 kbps) SNS block employed to improve encoding of highly tonal signals (Section 5.4) increases bit rates by
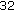 bps (to transmit the binary decision about employment of SNS in each sub-band). SNS does not affect the encoding of nontonal signals. Overall quality was slightly improved by about
bps (to transmit the binary decision about employment of SNS in each sub-band). SNS does not affect the encoding of nontonal signals. Overall quality was slightly improved by about  [33].
[33].For the purpose of detailed evaluation,
 additional test signals with strong tonality structure, downloaded from [39], were used in the experiments. Due to the application of SNS, the objective quality of each of these recordings is improved, as shown in Figure 11. The average objective quality score (average PEAQ score) for these samples is improved by about
additional test signals with strong tonality structure, downloaded from [39], were used in the experiments. Due to the application of SNS, the objective quality of each of these recordings is improved, as shown in Figure 11. The average objective quality score (average PEAQ score) for these samples is improved by about 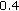 .
.Figure 11 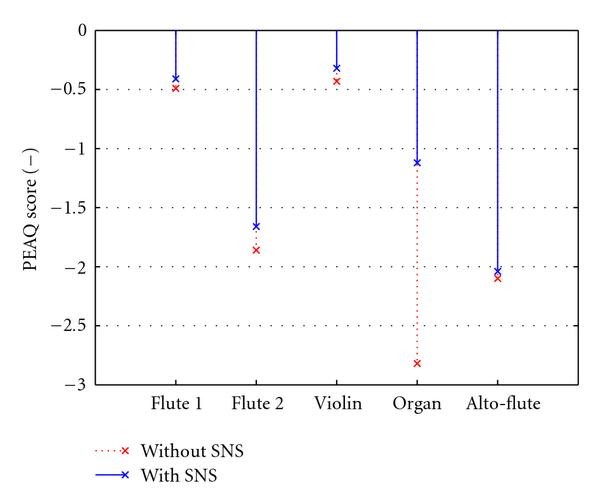
PEAQ (ODG) scores for 5 selected tonal files encoded by WB-FDLP codec (at 66 kbps) with and without SNS. PEAQ (ODG) score meanings are given in Table 2.
-
(f)
Temporal Masking (TM) (66 kbps) Final block simulates temporal masking to modify quantization levels of spectral components of sub-band residuals according to perceptual significance (Section 5.5). The bit-rate reduction is about
 kbps for an average PEAQ degradation by about
kbps for an average PEAQ degradation by about 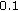 [36].
[36].
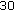 kbps for all the frequency sub-bands. DFT phases are uniformly quantized using
kbps for all the frequency sub-bands. DFT phases are uniformly quantized using  bits. Such codec operates at
bits. Such codec operates at 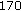 kbps [
kbps [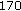 kbps to
kbps to 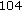 kbps (about
kbps (about 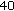 %), while the overall objective quality is degraded by about
%), while the overall objective quality is degraded by about  .
.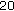 kbps (from
kbps (from 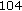 to
to  kbps), while the overall objective quality is degraded by about
kbps), while the overall objective quality is degraded by about 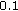 .
.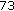 kbps (by about
kbps (by about 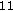 kbps), while the overall objective quality is degraded by about
kbps), while the overall objective quality is degraded by about 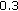 .
.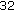 bps (to transmit the binary decision about employment of SNS in each sub-band). SNS does not affect the encoding of nontonal signals. Overall quality was slightly improved by about
bps (to transmit the binary decision about employment of SNS in each sub-band). SNS does not affect the encoding of nontonal signals. Overall quality was slightly improved by about  [
[ additional test signals with strong tonality structure, downloaded from [
additional test signals with strong tonality structure, downloaded from [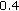 .
.
 kbps for an average PEAQ degradation by about
kbps for an average PEAQ degradation by about 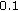 [
[7. Comparison with State-of-the-Art Audio Codecs
The final version of the WB-FDLP codec operating at  kbps, which employs all the blocks described and evaluated in Sections 5 and 6, respectively, is compared with the state-of-the-art MPEG audio codecs. In our evaluations, the following two codecs are considered.
kbps, which employs all the blocks described and evaluated in Sections 5 and 6, respectively, is compared with the state-of-the-art MPEG audio codecs. In our evaluations, the following two codecs are considered.
(1)LAME-MP3 (3.97 32 bits) (MPEG 1, layer 3) at  kbps [40]. Lame codec based on MPEG-1 architecture [2] is currently considered the best MP3 encoder at mid-high bit rates and at variable bit rates.
kbps [40]. Lame codec based on MPEG-1 architecture [2] is currently considered the best MP3 encoder at mid-high bit rates and at variable bit rates.
(2)MPEG-4 HE-AAC (V8.0.3), v1 at  kbps [3]. The HE-AAC coder is the combination of spectral band replication (SBR) [41] and advanced audio coding (AAC) [42] and was standardized as high-efficiency AAC (HE-AAC) in Extension 1 of MPEG-4 Audio [43].
kbps [3]. The HE-AAC coder is the combination of spectral band replication (SBR) [41] and advanced audio coding (AAC) [42] and was standardized as high-efficiency AAC (HE-AAC) in Extension 1 of MPEG-4 Audio [43].
Objective quality evaluation results for the  speech/audio files from [38] encoded by LAME-MP3 and MPEG-4 HE-AAC codecs are also presented in Figure 10.
speech/audio files from [38] encoded by LAME-MP3 and MPEG-4 HE-AAC codecs are also presented in Figure 10.
Subjective evaluation of the proposed WB-FDLP codec with respect to two state-of-the-art codecs (LAME-MP3 and MPEG4 HE-AAC) is carried out by MUSHRA (multiple stimuli with hidden reference and anchor) methodology. It is defined by ITU-R recommendation BS.1534 [44]. We perform the MUSHRA tests on  audio samples from the database of [38] with
audio samples from the database of [38] with  listeners. The recordings (originals as well as encoded versions) selected for MUSHRA evaluations, specifically mentioned in Table 1, can be downloaded from [45]. The results of the MUSHRA tests are shown in Figure 12. In Figure 13, we also show MUSHRA test results for
listeners. The recordings (originals as well as encoded versions) selected for MUSHRA evaluations, specifically mentioned in Table 1, can be downloaded from [45]. The results of the MUSHRA tests are shown in Figure 12. In Figure 13, we also show MUSHRA test results for  expert listeners for the same data. These listeners are included in the previous list of
expert listeners for the same data. These listeners are included in the previous list of  subjects.
subjects.

MUSHRA results for 8 audio files with 22 listeners encoded using three codecs: WB-FDLP (66 kbps), MPEG-4 HE-AAC (64 kbps), and LAME-MP3 (64 kbps). We add results for hidden reference (original) and two anchors (7 kHz low-pass filtered and 3.5 kHz low-pass filtered). We show mean values and 95% confidence intervals.

MUSHRA results for 8 audio files with 4 expert listeners encoded using three codecs: WB-FDLP (66 kbps), MPEG-4 HE-AAC (64 kbps) and LAME-MP3 (64 kbps). We add results for hidden reference (original) and two anchors (7 kHz low-pass filtered and 3.5 kHz low-pass filtered). We show mean values and 95% confidence intervals.
Furthermore, in order to better understand the performances of the proposed WB-FDLP codec, we perform the BS.1116 methodology of subjective evaluation [46]. BS.1116 is used to detect small impairments of the encoded audio compared to the original. As this subjective evaluation is time consuming, only two coded versions (proposed WB-FDLP and MPEG-4 HE-AAC) are compared. The subjective results with  listeners using
listeners using  speech/audio samples from the same database [38], mentioned in Table 1, are shown in Figure 14.
speech/audio samples from the same database [38], mentioned in Table 1, are shown in Figure 14.

BS. 1116 results for 5 audio files with 7 listeners encoded using two codecs: WB-FDLP (66 kbps), MPEG-4 HE-AAC ( kbps). We add results for hidden reference (H. ref.) for each codec separately. We show mean values and 95% confidence intervals.
kbps). We add results for hidden reference (H. ref.) for each codec separately. We show mean values and 95% confidence intervals.
8. Discussions and Conclusions
A novel wide-band audio compression system for medium bit rates is presented. The audio codec is based on processing relatively long temporal segments of the input audio signal. Frequency-domain linear prediction (FDLP) is applied to exploit predictability of temporal evolution of spectral energies in nonuniform sub-bands of the signal. This yields sub-band residuals, which are quantized using temporal masking. The use of FDLP ensures that fine temporal details of the signal envelopes are captured with high temporal resolution. Several additional techniques are used to reduce the final bit rate. The proposed compression system is relatively simple and suitable for coding both speech and music.
Performances of some of some individual processing steps are evaluated using objective perceptual evaluation of audio quality, standardized by ITU-R (BS.1387). Final performances of the codec at  kbps are evaluated using subjective quality evaluation (MUSHRA and BS.1116 standardized by ITU-R). The subjective evaluation results suggest that the proposed WB-FDLP codec provides better audio quality than LAME-MP3 codec at
kbps are evaluated using subjective quality evaluation (MUSHRA and BS.1116 standardized by ITU-R). The subjective evaluation results suggest that the proposed WB-FDLP codec provides better audio quality than LAME-MP3 codec at  kbps and produces slightly worse results compared to MPEG-4 HE-AAC standard at
kbps and produces slightly worse results compared to MPEG-4 HE-AAC standard at  kbps.
kbps.
We stress that the codec processes each frequency sub-band independently without taking into account sub-band correlations, which could further reduce the bit rate. This strategy has been pursued intentionally to ensure robustness to packet losses. The drop-out of bit-packets in the proposed codec corresponds to loss of sub-band signals at the decoder. In [47], it has been shown that the degraded sub-band signals can be efficiently recovered from the adjacent sub-bands in time-frequency plane which are unaffected by the channel.
From computational complexity point of view, the proposed codec does not perform highly demanding operations. Linear prediction coefficients of the FDLP model are estimated using fast LBG algorithm. Most of the computational cost is due to the search for appropriate codewords to vector quantize magnitude spectral components of the sub-band residuals. However, codebook search limitations, which also applied in traditional speech codecs such as CELP, have been already overcome by various techniques (e.g., two-stage algebraic-stochastic quantization scheme).
The fundamental technique—FDLP—used in the presented audio codec is a frequency-domain dual of the well-known time-domain linear prediction (TDLP). Similar to this duality, the other techniques exploited in the proposed codec can be associated to standard signal processing techniques.
-
(i)
QMF: it performs frequency-domain alias cancellation. This is a dual property to a technique called time-domain alias cancellation (TDAC). TDAC ensures perfect invertibility of the modified discrete cosine transform (MDCT) used in AAC codecs.
-
(ii)
SNS: Unlike temporal noise shaping (TNS) employed in AAC codecs to outperform problems with transient signals, SNS improves quality of highly tonal signals compressed by the WB-FDLP codec.
-
(iii)
TM: it is a psychoacoustic phenomenon implemented to significantly reduce bit-rates while maintaining the quality of the reconstructed audio. TM is often referred to as nonsimultaneous masking (part of auditory masking), where sudden stimulus sound makes inaudible other sounds which are present immediately preceding or following the stimulus. Since the effectiveness of TM lasts approximately
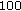 ms (in case of the offset attenuation), TM is a powerful and easily implementable technique in the FDLP codec. Frequency masking (FM) (or simultaneous masking) is a dual phenomenon to TM, where a sound is made inaudible by a "masker'', a noise of the same duration as the original sound. FM is exploited in most of psychoacoustic models used by traditional audio codecs.
ms (in case of the offset attenuation), TM is a powerful and easily implementable technique in the FDLP codec. Frequency masking (FM) (or simultaneous masking) is a dual phenomenon to TM, where a sound is made inaudible by a "masker'', a noise of the same duration as the original sound. FM is exploited in most of psychoacoustic models used by traditional audio codecs.
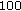 ms (in case of the offset attenuation), TM is a powerful and easily implementable technique in the FDLP codec. Frequency masking (FM) (or simultaneous masking) is a dual phenomenon to TM, where a sound is made inaudible by a "masker'', a noise of the same duration as the original sound. FM is exploited in most of psychoacoustic models used by traditional audio codecs.
ms (in case of the offset attenuation), TM is a powerful and easily implementable technique in the FDLP codec. Frequency masking (FM) (or simultaneous masking) is a dual phenomenon to TM, where a sound is made inaudible by a "masker'', a noise of the same duration as the original sound. FM is exploited in most of psychoacoustic models used by traditional audio codecs.Modern audio codecs combine some of the previously mentioned dual techniques (e.g., QMF and MDT implemented in adaptive transform acoustic coding (ATRAC) developed by Sony [48]) to improve perceptual qualities/bit rates. Due to this, we believe that there is still a potential to improve the efficiency of the FDLP codec that has not been pursued yet. For instance, the proposed version of the codec does not utilize standard entropy coding. Further, neither SNRs in the individual sub-bands are evaluated nor signal dependent nonuniform quantization in different frequency sub-bands (e.g., module of frequency masking discussed above) and at different time instants (e.g., bit reservoir) are employed. Inclusion of these techniques should further reduce the required bit rates and provide bit rate scalability, which form part of our future work.
References
Schroeder MR, Atal BS: Code-excited linear prediction (CELP): high-quality speech at very low bit rates. Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '85), April 1985, Tampa, Fla, USA 10: 937-940.
Brandenburg K, et al.: The ISO/MPEG-audio codec: a generic standard for coding of high quality digital audio. Proceedings of the 92nd Convention of Audio Engineering Society (AES '92), 1992, New York, NY, USA preprint 3336
Herre J, Dietz M: MPEG-4 high-efficiency AAC coding. IEEE Signal Processing Magazine 2008, 25(3):137-142. 10.1109/MSP.2008.918684
Vinton MS, Atlas LE: Scalable and progressive audio codec. Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '01), April 2001, Salt Lake City, Utah, USA 5: 3277-3280.
Dudley H: The carrier nature of speech. Bell System Technical Journal 1940, 19(4):495-515.
Motlicek P, Hermansky H, Garudadri H, Srinivasamurthy N: Speech coding based on spectral dynamics. In Proceedings of the 9th International Conference on Text, Speech and Dialogue (TSD '06), September 2006, Brno, Czech Republic, Lecture Notes in Computer Science. Volume 4188. Springer; 471-478.
Herre J, Johnston JH: Enhancing the performance of perceptual audio coders by using temporal noise shaping (TNS). Proceedings of the 101st Convention of Audio Engineering Society (AES '96), November 1996 preprint 4384
Athineos M, Ellis DPW: Sound texture modelling with linear prediction in both time and frequency domains. Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '03), April 2003, Hong Kong 648-651.
Kumaresan R, Rao A: Model-based approach to envelope and positive instantaneous frequency estimation of signals with speech applications. Journal of the Acoustical Society of America 1999, 105(3):1912-1924. 10.1121/1.426727
Ganapathy S, Motlicek P, Hermansky H, Garudadri H: Autoregressive modeling of hilbert envelopes for wide-band audio coding. Proceedings of the 124th Convention of Audio Engineering Society (AES '08), May 2008, Amsterdam, The Netherlands
Christensen MG, Jensen SH: Computationally efficient amplitude modulated sinusoidal audio coding using frequency-domain linear prediction. Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '06), May 2006, Toulouse, France 189-192.
Itakura F, Saito S: Analysis synthesis telephony based on the maximum likelihood method. In Proceedings of the 6th International Congress on Acoustics, August 1968 Edited by: Kohasi Y. C17-C20. paper no. C-5-5
Atal BS, Schroeder MR: Adaptive predictive coding of speech signals. Bell System Technical Journal 1970, 49(8):1973-1986.
Ganapathy S, Thomas S, Hermansky H: Modulation frequency features for phoneme recognition in noisy speech. Journal of the Acoustical Society of America 2009, 125(1):EL8-EL12. 10.1121/1.3040022
Houtgast T, Steeneken HJM, Plomp R: Predicting speech intelligibility in rooms from the modulation transfer function, I. General room acoustics. Acustica 1980, 46(1):60-72.
IEC 60268-16 : Sound system equipment—part 16: objective rating of speech intelligibility by speech transmission index. http://www.iec.ch
Kingsbury BED, Morgan N, Greenberg S: Robust speech recognition using the modulation spectrogram. Speech Communication 1998, 25(1–3):117-132. 10.1016/S0167-6393(98)00032-6
Athineos M, Hermansky H, Ellis DPW: LP-TRAP: linear predictive temporal patterns. Proceedings of the 8th International Conference on Spoken Language Processing (ICSLP '04), October 2004, Jeju, South Korea 1154-1157.
Falk TH, Stadler S, Kleijn WB, Chan W: Noise suppression based on extending a speech-dominated modulation band. Proceedings of the European Conference on Speech Communication and Technology (Interspeech '07), August 2007, Antwerp, Belgium 970-973.
Makhoul J: Linear prediction: a tutorial review. Proceedings of the IEEE 1975, 63(4):561-580. 10.1109/PROC.1975.9792
Athineos M, Ellis DPW: Autoregressive modeling of temporal envelopes. IEEE Transactions on Signal Processing 2007, 55(11):5237-5245. 10.1109/TSP.2007.898783
Oppenheim AV, Schafer RW: Discrete-Time Signal Processing. 2nd edition. Prentice-Hall, Upper Saddle River, NJ, USA; 1998.
Churchill RV, Brown W: Introduction to Complex Variables Applications. 5th edition. McGraw-Hill, New York, NY, USA; 1982.
Hermansky H, Fujisaki H, Sato Y: Analysis and synthesis of speech based on spectral transform linear predictive method. Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '83), April 1983, Boston, Mass, USA 8: 777-780.
Motlicek P, Hermansky H, Ganapathy S, Garudadri H: Non-uniform speech/audio coding exploiting predictability of temporal evolution of spectral envelopes. In Proceedings of the 10th International Conference on Text, Speech and Dialogue (TSD '07), September 2007, Pilsen, Czech Republic, Lecture Notes in Computer Science. Volume 4629. Springer; 350-357.
Motlicek P, Ullal V, Hermansky H: Wide-band perceptual audio coding based on frequency-domain linear prediction. Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '07), April 2007, Honolulu, Hawaii, USA 265-268.
Motlicek P, Ganapathy S, Hermansky H, Garudadri H: Frequency domain linear prediction for QMF sub-bands and applications to audio coding. In Proceedings of the 4th International Workshop on Machine Learning for Multimodal Interaction (MLMI '07), June 2007, Brno, Czech Republic, Lecture Notes in Computer Science. Volume 4892. Springer; 248-258.
Itakura F: Line spectrum representation of linear predictive coefficients of speech signals. Journal of the Acoustical Society of America 1975, 57: S35. 10.1121/1.1995189
Charbonnier A, Rault J-B: Design of nearly perfect non-uniform QMF filter banks. Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '88), April 1988, New York, NY, USA 1786-1789.
Motlicek P, Ganapathy S, Hermansky H, Garudadri H, Athineos M: Perceptually motivated sub-band decomposition for FDLP audio coding. In Proceedings of the 11th International Conference on Text, Speech and Dialogue (TSD '08), September 2008, Brno, Czech Republic, Lecture Notes in Computer Science. Volume 5246. Springer; 435-442.
Vafin R, Kleijn WB: Entropy-constrained polar quantization and its application to audio coding. IEEE Transactions on Speech and Audio Processing 2005, 13(2):220-232. 10.1109/TSA.2004.840942
Pinsky MA: Introduction to Fourier Analysis and Wavelets. Brooks/Cole, Pacific Grove, Calif, USA; 2002.
Ganapathy S, Motlicek P, Hermansky H, Garudadri H: Spectral noise shaping: improvements in speech/audio codec based on linear prediction in spectral domain. Proceedings of the European Conference on Speech Communication and Technology (Interspeech '08), September 2008, Brisbane, Australia
Sinaga F, Gunawan TS, Ambikairajah E: Wavelet packet based audio coding using temporal masking. Proceedings of the IEEE Conference on Information, Communications and Signal Processing, December 2003, Singapore 1380-1383.
Jesteadt W, Bacon SP, Lehman JR: Forward masking as a function of frequency, masker level, and signal delay. Journal of the Acoustical Society of America 1982, 71(4):950-962. 10.1121/1.387576
Ganapathy S, Motlicek P, Hermansky H, Garudadri H: Temporal masking for bit-rate reduction in audio codec based on frequency domain linear prediction. Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '08), April 2008, Las Vegas, Nev, USA 4781-4784.
ITU-R Recommendation BS.1387 : Method for objective psychoacoustic model based on PEAQ to perceptual audio measurements of perceived audio quality. December 1998.
ISO/IEC JTC1/SC29/WG11 : Framework for exploration of speech and audio coding. MPEG2007/N9254, Lausanne, Switzerland, July 2007
Musical instrumental samples, http://theremin.music.uiowa.edu/MIS.html
LAME-MP3 codec, http://lame.sourceforge.net
Dietz M, Liljeryd L, Kjorling K, Kunz O: Spectral band replication, a novel approach in audio coding. Proceedings of the 112th Convention of Audio Engineering Society (AES '02), May 2002, Munich, Germany preprint 5553
Bosi M, Brandenburg K, Quackenbush S, et al.: ISO/IEC MPEG-2 advanced audio coding. Journal of the Audio Engineering Society 1997, 45(10):789-814.
ISO/IEC : Coding of audio-visual objects—part 3: audio, AMENDMENT 1: bandwidth extension. ISO/IEC Int. Std. 14496-3:2001/Amd.1:2003, 2003
ITU-R Recommendation BS.1534 : Method for the subjective assessment of intermediate audio quality. June 2001.
Homepage with encoded samples, http://www.idiap.ch/~pmotlic
ITU-R Recommendation BS.1116 : Methods for the subjective assessment of small impairments in audio systems including multichannel sound systems. October 1997.
Ganapathy S, Motlicek P, Hermansky H: Error resilient speech coding using sub-band hilbert envelopes. In Proceedings of the 12th International Conference on Text, Speech and Dialogue (TSD '09), September 2009, Pilsen, Czech Republic, Lecture Notes in Computer Science. Volume 5729. Springer; 355-362.
Tsutsui K, Suzuki H, Shimoyoshi O, Sonohara M, Akagiri K, Heddle RM: ATRAC: adaptive transform acoustic coding for MiniDisc. Proceedings of the 93rd Convention of Audio Engineering Society (AES '92), October 1992, San Francisco, Calif, USA preprint 3456
Acknowledgments
This work was partially supported by grants from ICSI Berkeley, USA and the Swiss National Center of Competence in Research (NCCR) on "Interactive Multi-modal Information Management (IM)2'' and managed by the IDIAP Research Institute on behalf of the Swiss Federal Authorities. The authors would like to thank Vijay Ullal and Marios Athineos for their active involvement in the development of the codec. They would also like to thank the reviewers for providing numerous helpful comments on the manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Motlicek, P., Ganapathy, S., Hermansky, H. et al. Wide-Band Audio Coding Based on Frequency-Domain Linear Prediction. J AUDIO SPEECH MUSIC PROC. 2010, 856280 (2010). https://doi.org/10.1155/2010/856280
Received:
Accepted:
Published:
DOI: https://doi.org/10.1155/2010/856280