- Research
- Open access
- Published:
Improved monaural speech segregation based on computational auditory scene analysis
EURASIP Journal on Audio, Speech, and Music Processing volume 2013, Article number: 2 (2013)
Abstract
A lot of effort has been made in Computational Auditory Scene Analysis (CASA) to segregate target speech from monaural mixtures. Based on the principle of CASA, this article proposes an improved algorithm for monaural speech segregation. To extract the energy feature more accurately, the proposed algorithm improves the threshold selection for response energy in initial segmentation stage. Since the resulting mask map often contains broken auditory element groups after grouping stage, a smoothing stage is proposed based on morphological image processing. Through the combination of erosion and dilation operations, we suppress the intrusions by removing the unwanted particles and enhance the segregated speech by complementing the broken auditory elements. Systematic evaluation shows that the proposed segregation algorithm improves the output signal-to-noise ratio by an average of 8.55 dB and cuts the percentage of noise residue by an average of 25.36% compared with the mixture, yielding a significant improvement for speech segregation.
1 Introduction
While monaural speech segregation remains a challenge to computers, the humans can distinguish and track speech signal of interest under various noisy environments. In 1990, Bregman published his book, Auditory Scene Analysis[1], which was the first to explain the principles underlying the perception of complex acoustic mixtures systematically, inspiring the establishment of its computational model, computational auditory scene analysis (CASA)[2].
The CASA simulates the human auditory system, and its processing of mixture speech is similar to human auditory perception. The system is made of two main stages: segmentation and grouping. It decomposes input signal into sensory segments in segmentation stage and then those segments which likely come from the same source are grouped into “target stream” together. Since the CASA system can solve the monaural speech separation problem, it has been improved continuously and tremendously in recent years.
The CASA system proposed by Brown and Cooke employs maps of different auditory features that generated from the output of a cochlear model for speech segregation. This system does not require a priori knowledge of the input signal but has a few limitations. It cannot handle sequential grouping problem effectively and often leaves missing parts in the segregated speech[3].
Wang and Brown[2, 4] proposed a CASA model to segregate voiced speech based on oscillatory correlation, which uses harmonicity and temporal continuity as major grouping cues. This model is able to recover most of the target speech, but it cannot handle the speech signal in the high-frequency range (above 1 kHz) well.
For voiced speech segregation, Hu and Wang[5, 6] proposed a typical monaural CASA system which groups the resolved and unresolved harmonics differently, using amplitude modulation (AM) effects to improve segregation. And in[7], an improved tandem algorithm is proposed for pitch estimation, which is robust to interference and produces good estimates of both target pitch and voiced target.
For unvoiced speech segregation, Hu–Wang system employed a multi-scale onset and offset analysis for unvoiced speech segmentation, which makes both voiced and unvoiced speeches correctly segmented in[8]. After voiced speech removal, acoustic-phonetic features are then used in a classification stage to distinguish unvoiced segments from interference[9, 10]. Hu and Wang[11] proposed a new CASA approach for unvoiced segregation based on spectral substraction. To further group the target signal across time, Shao proposed a CASA system comprised of both simultaneous and sequential organizations systematically in[12].
This article proposes an improved CASA system for speech separation. After signal decomposition, response energy feature plays an important role in initial segmentation. In the previous CASA system, a constant value is used as the threshold of the time-frequency (T-F) unit’s respond energy. However, because the intrusion is unknown, its distribution may vary in each channel. Some intrusions are likely to be distributed in all channels while some may only in some certain ranges. Hence, we label each T-F unit with proper threshold based on the respective channel energy to extract response energy feature, which will increase the robustness of the system and the accuracy of the initial pitch detection results. After further grouping and labeling the units with other auditory features, a binary mask map is constructed. There are usually some scattered or broken auditory fragments in the obtained mask map, which will cause unnecessary utterance fluctuation and degrade the quality of the resynthesized speech. However, few studies have been concentrated on this problem so far. In[5], though Hu-Wang system employs a smoothing stage for obtained mask such as remove the segments that shorter than 30 ms and so on, this simple post-processing method is not able to remove the isolated segments and make up the missing elements systematically and effectively. Mathematical morphological operation is of a great flexibility and well known as an efficient method in binary image smoothing processing. It is widely used in various tasks such as noise suppression, image enhancement, and image restoration. To smooth and retrieve the mask map, this article proposes a new smoothing method based on the erosion/dilation operation of binary mathematical morphology. This method is able to remove the residual noise and restore the mask map while maintaining the mask information. The experiments in Section 3 show that with a proper smoothing extent, it generates better results than conventional smoothing method.
The rest of the article is organized as follows. Section 2 gives an overview of the proposed system model and a detailed presentation of each component in this model. In Section 3, the proposed system is evaluated and compared with Hu–Wang tandem system[7]. Finally, conclusion is presented in Section 4.
2 System description
Figure1 illustrates the proposed speech separation model, which is a multi-stage system, where initial segmentation module is improved and the smoothing module for auditory element mask based on the morphological image processing is added to CASA speech segregation system.

Block diagram of the proposed speech separation system. The modules in the dashed box are the proposed system where it has been improved.
2.1 Auditory periphery processing
In the first stage, auditory periphery is modeled by a 128-channel gammatone filterbanks and a simulation of neuromechanical transduction by inner hair cells[5]. The input speech passes through the auditory periphery model and is decomposed into the T-F domain. Each unit in this domain is called a T-F unit ucm, corresponding to a certain filter channel c at a certain time frame m.
Gammatone filters are derived from psychophysical observations of the auditory periphery and this filterbank is a standard model of cochlear filtering[2]. Its center frequencies are quasi-logarithmically spaced from 80 to 5000 Hz. The impulse response of gammatone filter is
where l = 4 is the center frequency of the filter and b is the equivalent rectangular bandwidth which increases with f.
The response of each gammatone filter is further processed by Meddis et al.[13] model of inner hair cells. Its output represents the firing rate of an auditory nerve fiber.
In the high-frequency range, a filterbank channel contains multiple harmonics, leading to AM problem and changing the correlogram. However, it is proven that the envelope correlogram shows fluctuation at the fundamental frequency of dominant pitch though the response in high-frequency range is strongly amplitude modulated, so it is an appropriate feature in high-frequency range for CASA system. Therefore, we use a low-pass FIR filter to extract the response envelope feature of each channel[5]. The output h(c,n) is divided into 20-ms time frames with 10-ms time shift in each channel.
2.2 Feature extraction
In the second stage, we extract the auditory features from the filter response as follows.
-
(1)
Correlogram: A correlogram constructed by the autocorrelation of hair cell response h(c,n) in the T-F domain is given by:
(2)where c is the order of the channel and m is the time frame and N c is the number of samples in a frame of 20 ms. τ refers to time delay, τ ∈ [0,12.5 ms], where the maximum delay is corresponding to 80 Hz.The envelope correlogram is constructed by computing the autocorrelations of the response envelope.
-
(2)
Cross-channel correlation: Cross-channel correlation between adjacent filter channels indicates whether the filters respond to the same target. C H is calculated as follows.
(3)Here, L is the sampling number corresponding to the maximum time lag and denotes A H normalized to zero mean and unity variance.The envelope of cross-channel correlation indicates the similarity between the envelopes of AM patterns in the high-frequency range, which is computed by the envelope correlogram.
-
(3)
Response energy: When τ = 0, the correlogram A(c,m,0) represents the response energy of the input signal.
-
(4)
Onset/offset detection: Onsets and offsets correspond to sudden intensity changes, reflecting boundaries of auditory events [12]. This feature provides useful cues for unvoiced speech segmentation. Here, we employ an onset/offset-based segmentation method proposed by Hu and Wang [8]. It consists of three stages: smoothing, onset/offset front matching and multi-scale integration, as shown in Figure 2.

Block diagram of the onset/offset detection.
Onset/offset detection yields a set of segments, usually containing voiced, unvoiced speech, and interference.
2.3 Initial segmentation
Segmentation stage comprises two parts, namely voiced and unvoiced. Unvoiced segmentation is based on onset/offset analysis as mentioned in Section 2.2 while voiced segmentation is mainly based on the extracted features such as response energy and cross-channel correlation.
Since the response energy of the T-F units dominated by the target speech is stronger than those dominated by the background noise, the estimated target units are initially labeled based on the response energy feature A(c,m,0) and the cross-channel correlation feature C(c,m) as follows[5]:
Here, θ C is constant, chosen to be 0.985[4].
is the threshold for the effective target energy. In this article, the intrusions for the speech segregation experiment are of a great variety. The distribution of the intrusion’s energy is quite uncertain. It may be distributed around the whole channels or in a certain range, mostly in the high-frequency range. Conventional constant threshold is not able to extract the target energy while removing the intrusion efficiently. This would affect the initial dominant pitch detection results. To obtain more accurate energy extraction results, the energy is extracted based on its own characteristic distribution feature in the proposed algorithm. Different thresholds are calculated for different frequency channels. Here, is defined as the threshold of channel c and calculated based on the average energy of channel c as follows:
Here, M is the total number of the frames in a single channel. α is constant and decides the value of the threshold. if α is set too high, the threshold would be too low to remove the interference especially in the high-frequency range. If it is set too low, the threshold would be too high to preserve the target energy in all channels. Thus, it has to seek the balance between target energy preserving and intrusion energy removing. By experiments, it is found that α = 1.2 is an appropriate value. The experiment results are presented in Section 3 for details.
The proposed energy threshold selection method often produces better results than the conventional constant threshold as it can remove more interference units, especially the non-speech ones. Figure3 illustrates an example of the female speech and crowd noise with music mixture labeled by conventional threshold and proposed method, whose intrusion energy is distributed in all channels. Similar to Figure3, the response energy-labeling example of the speech and white noise mixture, whose intrusion energy is mainly distributed in high-frequency ranges, is shown in Figure4.

The energy-labeled mask for the speech and crowd noise with music mixture. (a) Cochleagram of a female utterance showing the energy of each T-F units. The brighter pixel indicates stronger energy. (b) Ideal binary mask, which is computed by target and intrusion before mixing. (c) Cochleagram of the mixture. (d) The mask labeled by the conventional threshold. (e) The mask labeled by the proposed threshold selection method.

The energy-labeled mask for the speech and white noise mixture. (a) Cochleagram of a female utterance showing the energy of each T-F units. (b) Ideal binary mask. (c) Cochleagram of the mixture. (d) The mask labeled by the conventional threshold. (e) The mask labeled by the proposed threshold selection method.
From Figures3 and4, it can be inferred that for many kinds of intrusions, the proposed method can remove more units dominated by the interference than the conventional threshold selection method, which will increase the accuracy of the initial pitch detection and the robustness of the system.
After initial labeling, those selected neighboring T-F units which likely come from the target speech are merged into segments[5].
2.4 Pitch tracking
Pitch detection and tracking in complex environment has proven to be very challenging in CASA system. In this article, we apply a tandem method for pitch tracking and reestimation proposed by Hu and Wang[7, 14].
The tandem algorithm can track several pitch contours and handle multi-talker problem. First, an initial pitch estimation needs to be complemented. After initial segmentation, the labeled units which have strong energy and high cross-channel correlation are likely from the target speech and considered to be active units. The initial estimated pitch should be supported and calculated by the active units. Let L0(c,m) be the labeled mask after initial segmentation and H0 be the hypothesis that ucm is target dominant, the estimated target pitch is calculated as follows:
where
and θ P is set to be 0.75[7, 9].
rcm(τ) is a six-dimensional feature vector for each T-F units, defined as follows:
Here, A(c,m,τ) denotes the autocorrelation and denotes the estimated average instantaneous frequency features calculated from the response of each T-F unit ucm. The function int(x) returns the nearest integer. The first three features are extracted from the filter responses and the last three from the response envelopes[7, 14].
P(H0|rcm(τ)) for each channel is computed by a pre-trained multi-layer perceptron. The corpus used for training consists of 100 utterances selected from TIMIT database and 100 intrusions of a great variety[7]. With the obtained pitch estimates, the mask for τS,1(m), denoted as L1(c,m), is reestimated as
The tandem algorithm is able to handle multiple pitch estimation and tracking problem. If the mixture contains other utterances, after extracting the first target pitch τS,1(m), the units which do not support τS,1(m) are used to extract the second pitch τS,2(m) as follows:
where L2(c,m) is the mask for τS,2(m), calculated as
Similarly, after extracting the second pitch τS,2(m), the mask L2(c,m) is reestimated as
After the pitch estimation, pitch contours are generated based on the temporal continuity. The differences between the pitch periods of the same speech at the consecutive frames m − 1,m, and m + 1 should be all less than 20% of themselves. Meanwhile, their associated masks should also have good temporal continuity. After this pitch tracking with the above constraints, the remaining isolated pitch estimates are considered unreliable and set to 0, indicating no pitch at these frames[7, 9, 14].
The pitch contours and their associated masks are both reestimated iteratively. The tandem algorithm estimates the pitch and segregates the voiced speech jointly[11].
2.5 Grouping and unit labeling
In this stage, the T-F units are grouped into streams and labeled as target or background based on the extracted feature. To obtain the final target stream, both voiced and unvoiced segregations are needed[12]. Hence, a binary mask map is constructed finally.
-
1.
If the interference is non-speech, voiced speech segregation is performed by tandem algorithm first [7]. Then an unvoiced speech segregation algorithm proposed by Hu and Wang [10, 15] is used in this article. The extracted segments by onset/offset analysis usually contain both voiced, unvoiced speech and interference. To extract the unvoiced segments, the segments that are overlapped with the voiced segments need to be removed first. Then, the unvoiced segments are distinguished from interference based on the classification of acoustic-phonetic features. The extracted unvoiced segments are subsequently merged with the target streams to generate final outputs.
-
2.
If intrusion is another speech, after simultaneous grouping based on the detected pitch contours, a sequential grouping for organizing the target utterance based on speaker characteristics is required [16]. According to Shao and Wang, to ensure the homogeneity of each segment, if dominant pitch values of neighboring frames change abruptly, it is considered that a speaker change occurs and the segment may be split into two shorter one. To group the segments, the speaker models are needed to be pre-trained. The data used for training and testing come from TIMIT database. The speaker set consists of 30 talkers (15 males and 15 females). The speakers are modeled as 64-mixture Gaussian mixture models and trained using the Gammatone frequency cepstral coefficients [12]. With the pre-trained speaker models, the segments are grouped into two speaker streams by searching for the optimal hypothesis based on the speaker characteristics. A binary mask for voiced segments is labeled regarding whether the current belongs to the same speaker as the previous segments based on the likelihood of pitch dynamic feature. Unvoiced segments grouped based on the already detected speakers with the organized streams [12, 16].
After the above steps in grouping and unit labeling, a binary mask map is obtained.
2.6 Smoothing
There are some discrete fragments or missing segments in the mask map we have obtained, which will cause unnecessary fluctuation in the segregated speech. In previous CASA systems, little attention has been paid to this problem. In our system, missing auditory elements are complemented and unwanted particles are pruned while the original target segments being maintained in a novel and systematic way.
Though the mask map is a two-dimensional T-F representation of audio signal, it is also a binary image and viewed as a bi-valued function of 1 and 0. In this binary mask image, the discrete fragments less than a certain threshold is likely to be the residual noise while the broken auditory elements with narrow gaps indicate the discontinuous speech in the resynthesized speech. So, the problem of speech enhancement becomes the image restoration. In this way, we can use the image processing technique to improve the quality of the segregated speech signal.
2.6.1 Morphological image processing
Mathematical morphology is often used in binary image processing for pre- or post processing, such as morphological filtering, thinning, and pruning[17]. The language and theory of the mathematical morphology often present a dual view of binary images. It is an effective way to remove the noise while retaining the information details in binary image.
With proper morphological image processing operations, we can suppress the intrusions by removing the unwanted particles and enhance the segregated speech by complementing the broken auditory segments in the obtained mask.
The operations of dilation and erosion are fundamental to morphological image processing. The unwanted particles can be pruned and the broken auditory elements can be complemented in the mask map by combining the two operations properly.
-
(1)
Dilation: Dilation is an operation that “grows” and “thickens” objects in a binary image. The specific manner and extent of this thicken is controlled by a shape referred to as a structuring element.Let B be the structuring element and A be the mask, we define some basic operations first. is the reflection of set B, defined as
(13)(B) z is the translation of set B by point z = (z1,z2), defined as
(14)Based on the above definitions, the dilation of A by B, denoted A ⊕ B, is defined as follows
(15)where Ø is the empty set.
-
(2)
Erosion: Erosion is an operation that “shrinks” or “thins” objects in a binary image. As in dilation, the manner and extent of shrinking is controlled by a structuring element. The erosion of A by B, denoted A ⊖ B, is defined as follows
(16)where Ac is the complement of set A[17].
2.6.2 Mask smoothing based on morphological image processing
In this stage, we complement the missing auditory elements and prune the unwanted particles by combining dilation and erosion operations.
Each marked T-F unit is considered as an active element. All the active elements are considered as having similar periodicity patterns. The structuring element defines the smoothing extent of the resulting mask. For time dimension, since the actual speech segments should be no shorter than 30 ms[5], the target speech segments should last for two frames as each frame representing 20 ms with 10 ms time shift. For frequency dimension, since the segments that cross less than three channels are considered to be edge elements[18], the target segments should cross three channels at least. Thus, the segments less than two frames or does not cross three channels should be pruned by morphological image processing. Similarly, the gaps no larger than the same size should be complemented, too. Hence, the structuring element are selected to be a 3 × 2 mask. Here, we perform the smoothing operation with the following structuring element:
With this proper size of structuring element, the operation can remove the unwanted particles and complement the broken auditory element while maintaining the original target segments. The smoothing operation rules take the form as follows:
-
(1)
Pruning: To suppress the synthesized noise, pruning stage is used to remove the isolated particles and smooth the spurious salience of the segments in the obtained mask. We apply erosion of the mask A by the structuring element B and followed dilation of the result by B. After these operations, we remove the small isolated particles and obtain the resulting mask A ′ [17]:
(18)Figure5 illustrates the original mask A and the mask A′ after pruning.
Figure 5 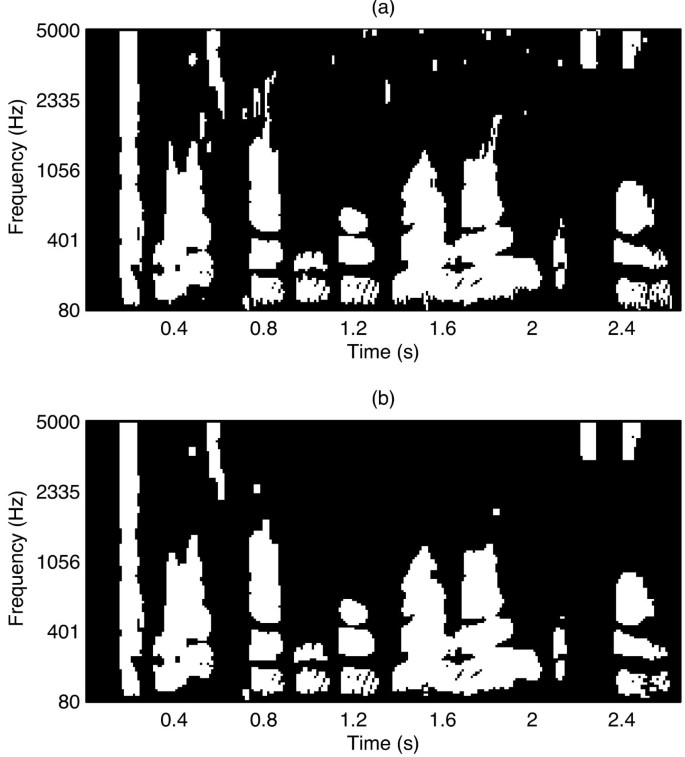
An illustrative example of pruning the mask. (a) The original mask A. (b) The mask A′after pruning.
From Figure5, it can be seen that the isolated segments which unlikely arise from target speech are removed successfully.
-
(2)
Complementing: We complement the broken auditory elements in the low-frequency range (below 1 kHz) after pruning based on the morphological image processing. We apply A ′with dilation by B and followed by erosion. This operation will fill the discontinuous gaps of the target speech [17]. The resulting mask C in the low-frequency is obtained after complementing step:
(19)In many situations, there will be some residual interference energy distributed in the high-frequency range. If complementing is applied in the high-frequency range, unnecessary noise may be also brought in the segregated speech. Therefore, we only complement the mask map to recover the broken auditory elements in the low-frequency range[18]. The comparison for complementing results is presented in Section 3 for details.

Figure6a shows an example of mask A′ while Figure6b shows the final mask results C after complementing. It can be seen that the auditory element groups are compensated so that there are no missing parts between speech elements after complementing stage.

Result of complementing the mask. (a) The mask A′before complementing. (b) The final mask C after complementing.
Through morphological image processing smoothing, the likely residual noise is removed and the discontinuous target speech is complemented, so the mask map and the segregated speech are both enhanced.
2.7 Speech resynthesis
After smoothing stage, this algorithm resynthesizes the segregated speech from input mixture and the final mask C with an inverse filter of the gammatone filterbank[12].
Figure7 illustrates the segregated result for the speech of a female utterance and the alarm clock mixture. Figure7a shows the waveform of the original female utterance and Figure7b of the mixture. The resynthesized speech by the tandem system and the proposed CASA system are shown in Figure7c,d respectively.

Segregation illustration. (a) The waveform of the original female utterance. (b) The waveform of the mixture. (c) The waveform of the resynthesized speech by the tandem system. (d) The waveform of the resynthesized speech by the proposed CASA system.
As shown in Figure7, the waveform of segregated speech by the proposed system is more closer to the original one for that it extracts more exact energy and retrieves the auditory mask map.
3 Evaluation and comparison
To validate the effectiveness of the proposed method, we evaluate the speech segregation results. The database consists of a set of 170 mixtures, which are obtained by mixing utterances with 17 intrusions at different SNR levels. The original utterances (ten sentences spoken by five male speakers and five female speakers) are randomly selected from the TIMIT database. The sampling frequency is 16 kHz. The added 17 different intrusions are as follows: N1, white noise; N2, rock music; N3, siren; N4,telephone; N5, electric fan; N6, alarm clock; N7, traffic noise; N8, bird chirp with water flow; N9, wind noise; N10, rain; N11, cocktail party; N12, crowd noise at a playground; N13, crowd noise with music; N14, crowd noise with clap; N15, babble noise; N16, male speech; N17, female speech. In N16 and N17 cases, the target utterance is much stronger than the interference. These intrusions are of a considerable variety and used to test CASA systems[7, 9].
3.1 Selection of α
First, we present the experiment results for the selection of α in initial segmentation. Here, average signal-to-noise ratio (SNR) gain over the conventional threshold method is employed as the criterion for the selection of α. SNR is an objective and straightforward criterion to measure the performance of the algorithm, which is calculated as
where S0(n) is the original speech and is the segregated speech.
The average SNR gain over the conventional method, denoted as S G , is calculated as follows
where S P is the average SNR result generated by the proposed threshold selection method and S C is the result generated by the conventional constant threshold.
Figure8 shows the S G results at different values of α from 0.8 to 1.8 through experiments with various intrusions. It can be seen that when α = 1.2, S G exhibits a peak of 0.42 dB, so α = 1.2 is appropriate in our method.

The average SNR gain S G results at different value of α .
3.2 Comparison of complementing
Similar to the selection of α, in smoothing stage, to compare the results between complementing in the full-frequency and the low-frequency range, the average SNR gain over the conventional smoothing method, denoted as, is used as the criterion. Here, is calculated as follows
where is the average SNR result after complementing by morphological image processing and is the result generated by conventional smoothing method.
Figure9 shows results of complementing in full-frequency and low-frequency range, respectively. Each column in the figure represents the average value of ten utterances. As shown in Figure9, in most noise conditions, it has a better SNR improvement to complement the mask only in the low-frequency rather than the full-frequency range.

The SNR gainresults of complementing. The comparison of SNR gain results between complementing in full-frequency range and low-frequency range is presented.
3.3 System evaluation
Since two novel techniques are proposed in this article, the evaluation for the proposed system is provided separately as follows.
Figure10 shows the segregation results when proposed threshold selection stage is applied. The columns in the figure represent the average SNR value of ten mixtures in the test database and segregated speech by conventional and proposed threshold selection method, respectively. The comparison among the results of the tandem system and the proposed method for speech separation is presented in Table1.

Segregation results when threshold selection is applied. SNR results for segregated speech and mixtures for a corpus of speech and various intrusions when threshold selection method is applied.
Figure11 and Table2 show the segregation results when morphological image processing smoothing stage is applied.

Segregation results when morphological image processing is applied. SNR results for segregated speech and mixtures for a corpus of speech and various intrusions when morphological image processing is applied.
The final segregation results are shown in Figure12 and Table3. As shown in the above tables, we can see that the proposed method improves the SNR by 8.55 dB on average for all noise conditions, whereas the tandem system improves by 7.63 dB compared with no processing case. It is proven that the proposed model performs better than the tandem system in SNR improvement.

Final segregation results. Final SNR results for segregated speech and mixtures for a corpus of speech and various intrusions.
Despite its common use, SNR criterion does not provide much information about how different the segregated speech is from the original one. Here, we employ two complementary error measures to evaluate the performance by comparing the resynthesized speech from estimated mask with ideal binary mask (IBM)[5]:
-
(1)
The percentage of energy loss P EL:
(23)Here, e1 is the signal presenting in the original speech but missing from the segregated one. I(n) is the speech resynthesized from the IBM. To obtain e1, we construct a new mask by labeling the T-F units which is active in IBM but inactive in final target stream. e1 is the waveform resynthesized from the mixture and the mask.
-
(2)
The percentage of noise residue P NR:
(24)Here, e2 is the energy presenting in the segregated signal but not existing in the original one. O(n) is the segregated speech obtained by CASA system. Similar to e1, a new mask is constructed by labeling the T-F units which is inactive in IBM but active in final target stream. e2 is the waveform resynthesized from the mixture and the mask.
The two criteria provide a better reflection about the difference between original and segregated speech. The better the performance is, the lower PEL and PNR will be, and vice versa. The results of the energy loss and noise residue are shown in Tables4,5, and6. Since the mixture contains all the original speech information, the PELof the mixture is 0.
From the final results, it can be seen that the proposed system has cut PNR of the mixture by 25.36%. It has improved both PEL and PNR compared with the tandem system by 1.43 and 1.08%, respectively.
The criteria we have used above such as SNR, PEL and PNR, do not always reflect the objective speech quality of the segregated speech. To evaluate the segregated speech quality further, we use the perceptual evaluation of speech quality (PESQ) criterion further for comparison. This evaluation method has been proposed by the International Telecommunication Union (ITU) under the recommendation P.862[19]. The higher values of PESQ mean better performance. As shown in Table7, the superiority of the proposed method compared to that of the Hu–Wang tandem system is illustrated. It can be seen that the threshold selection has a better performance in PESQ improvement than the conventional threshold under most intrusion conditions except N8 and N16 while morphological image processing smoothing increases the criterion under all conditions.
From the experiment results by different criteria, it is proven that the proposed model has a better performance.
4 Conclusions
This article concentrates on the improvement for the initial segmentation and smoothing stage in CASA system. We set different thresholds in each channel to label the T-F units based on the response energy feature due to the unknown distribution of the intrusions while the tandem system uses constant threshold. As CASA system performs speech segregation based on the various features, it always produces broken auditory elements in the mask, which leads to the missing portions of the segregated signal. To solve this problem, morphological image processing is introduced to the smoothing stage for complementing and pruning the mask map. We evaluated the separation performance of the proposed system and compared it with the Hu–Wang tandem system for the speech segregation tasks with artificially mixed speech data. The comparison shows that the proposed method has a better performance by improving the average SNR and PESQ while cutting the energy loss and noise residue rate effectively.
Abbreviations
- AM:
-
amplitude modulation
- CASA:
-
computational auditory scene analysis
- IBM:
-
ideal binary mask
- ITU:
-
International Telecommunication Union
- PESQ:
-
perceptual evaluation of speech quality
- SNR:
-
signal-to-noise ratio.
References
Bregman A: Auditory Scene Analysis. MIT Press, Cambridge, MA; 1990.
Wang D, Brown G: Computational Auditory Scene Analysis: Principles, Algorithms and Applications. IEEE Press, New Jersey; 2006.
Brown G, Cooke M: Computational auditory scene analysis. Comput Speech Lang 1994, 8: 297-336. 10.1006/csla.1994.1016
Wang D, Brown G: Separation of speech from interfering sounds based on oscillatory correlation. IEEE Trans. Neural Netw 1999, 10(3):684-697. 10.1109/72.761727
Hu G, Wang D: Monaural speech segregation based on pitch tracking and amplitude modulation. IEEE Trans. Neural Netw 2004, 15(5):1135-1150. 10.1109/TNN.2004.832812
Hansler E, Schmidt G (Eds): Topics in Acoustic Echo and Noise Control. Springer, New York; 2006.
Hu G, Wang D: A tandem algorithm for pitch estimation and voiced speech segregation. IEEE Trans. Audio Speech Lang. Process 2010, 18(8):2067-2079.
Hu G, Wang D: Auditory segmentation based on onset and offset analysis. IEEE Trans. Audio Speech Lang. Process 2007, 15(2):396-405.
Hu G: Monaural speech organization and segregation. The Ohio State University, PhD thesis; 2006.
Hu G, Wang D: Segregation of unvoiced speech from non-speech interference. J. Acoust. Soc. Am 2008, 124: 1306-1319. 10.1121/1.2939132
Hu K, Wang D: Unvoiced speech segregation from nonspeech interference via CASA and spectral subtraction. IEEE Trans. Audio Speech Lang. Process 2011, 19(6):1600-1609.
Shao Y, Srinivasan S, Jin Z, Wang D: A computational auditory scene analysis system for speech segregation and robust speech recognition. Comput. Speech Lang 2010, 24: 77-93. 10.1016/j.csl.2008.03.004
Meddis R, et al.: Simulation of auditory-neural transduction: further studies. J. Acoust. Soc. Am 1988, 83(3):1056-1063. 10.1121/1.396050
Wang D: Tandem algorithm for pitch estimation and voiced speech segregation. 2010.http://www.cse.ohio-state.edu/pnl/software.html , Accessed 23 September 2012
Wang D, Hu G: Unvoiced speech segregation. IEEE, Toulouse; 2006.
Shao Y, Wang D: Model-based sequential organization in cochannel speech. IEEE Trans. Audio Speech Lang. Process 2006, 14(1):289-298.
Rafael C, Richard E, Steven L: Digital image processing using MATLAB (Publishing House of Electronics Industry. Beijing; 2009.
Lee Y, Kwon O: Application of shape analysis techniques for improved CASA-based speech separation. IEEE Trans. Consum. Electron 2009, 55(1):146-149.
Pichevar R, Rouat J, A quantitative evaluation of a bio-inspired sound segregation technique for two-and three-source mixtures sounds: Lecture Notes in Computer Science. Springer, Berlin; 2004.
Acknowledgements
This study was supported by the National Natural Science Foundation of China (Grant nos. 60903186, 61271349).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Yu, W., Jiajun, L., Ning, C. et al. Improved monaural speech segregation based on computational auditory scene analysis. J AUDIO SPEECH MUSIC PROC. 2013, 2 (2013). https://doi.org/10.1186/1687-4722-2013-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1687-4722-2013-2