- Research
- Open access
- Published:
Enhancement of speech dynamics for voice activity detection using DNN
EURASIP Journal on Audio, Speech, and Music Processing volume 2018, Article number: 10 (2018)
Abstract
Voice activity detection (VAD) is an important preprocessing step for various speech applications to identify speech and non-speech periods in input signals. In this paper, we propose a deep neural network (DNN)-based VAD method for detecting such periods in noisy signals using speech dynamics, which are time-varying speech signals that may be expressed as the first- and second-order derivatives of mel cepstra, also known as the delta and delta-delta features. Unlike these derivatives, in this paper, the dynamics are highlighted by speech period candidates, which are calculated based on heuristic rules for the patterns of the first and second derivatives of the input signals. These candidates, together with the log power spectra, are input into the DNN to obtain VAD decisions. In this study, experiments are conducted to compare the proposed method with a DNN-based method, which exclusively utilizes log power spectra by using speech signals smeared with five types of noise (white, babble, factory, car, and pink) with signal-to-noise ratios (SNRs) of 10, 5, 0, and − 5 dB. The experimental results show that the proposed method is superior under all the considered noise conditions, indicating that the speech period candidates improve the log power spectra.
1 Introduction
Voice activity detection (VAD) is used as a preprocessing stage for various speech applications to identify speech and non-speech periods. In speech enhancement, for example, in spectral subtraction, speech/non-speech detection is applied to identify the signal periods that contain only noise. This is useful for noise estimations, which are then used in the noise reduction process [1]. In digital cellular telecommunication systems, such as the Universal Mobile Telecommunication Systems (UMTS) [2], VAD is employed to detect non-speech frames and thus reduce average bit rates [3]. VAD may also improve the performance of speech recognition by identifying the boundaries of the speech to be recognized [4].
Because background noise is a challenging problem, selecting features that are discriminative for properties of speech and noise is an important aspect of the design of VAD algorithms [5]. In prior studies, simple acoustic features such as energy and zero crossing rates have been used to detect speech periods [6]. This type of technique is suitable for clean signals, and its performance is degraded under low signal-to-noise ratios (SNRs). Hence, various modifications of energy-based features, such as those described in [1, 7], have been proposed to improve the VAD performance. Other acoustic features have also been examined and investigated to improve the VAD performance. For example, the VAD algorithm proposed in [8] measures the long-term spectral divergence between speech and noise. Periodic to aperiodic component ratios were employed in [9]. Pek et al. [10] used modulation indices of the modulation spectra of speech data. Kinnunen and Rajad [11] introduced likelihood ratio-based VAD method in which speech and non-speech models are trained on an utterance-by-utterance basis using mel-frequency cepstral coefficients (MFCCs). Sohn et al. [12] proposed a method based on a Gaussian statistical model, in which a decision rule is derived from the mean of the likelihood ratios for individual frequency bands by assuming that the noise is known a priori. Davis et al. [13] proposed a scheme that incorporates a low-variance spectrum estimation technique and a method for determining an adaptive threshold based on noise statistics. These methods perform well under stationary noise; however, their performances are degraded under non-stationary noise. To improve the performance of VAD, machine learning methods have been explored. For instance, support vector machine (SVM) methods [14–16] and deep neural networks (DNNs) [17–19] have been found to be highly competitive with traditional VAD.
The great flexibility, deep and generative training properties of DNNs are useful in speech processing [20]. Espi et al. [21] utilized spectro-temporal features as the input to a convolutional neural network (CNN) to detect non-speech acoustic signals. Ryant et al. [22] utilized MFCCs as the input to a DNN to detect speech activity on YouTube. Mendelev et al. [23] proposed a DNN with a maxout activation function and dropout regularization to improve the VAD performance. Zhang et al. [24] attempted to optimize the capability of DNN-based VAD by combining multiple features, such as pitch, discrete Fourier transform (DFT), MFCCs, linear prediction coefficients (LPCs), relative-spectral perceptual linear predictive analysis (RASTA-PLP), and amplitude modulation spectrogram (AMS) along with their delta features, as the input to DNNs. However, choosing features as the input for a DNN is not a trivial problem. Research in automatic speech recognition has shown that raw features have the potential to be used as the input of a DNN, replacing “hand-crafted” features [25].
In this paper, we first attempt to utilize raw features, i.e., log power spectra, to detect speech periods using a DNN. In our preliminary experiment (Appendix Appendix 1: preliminary experiment, Table 4), two findings are obtained. First, the performance of VAD using the log power spectra as the input of the DNN outperforms standard features, such as MFCCs and MFCCs combined with delta and delta-delta cepstra, for both clean and noisy speech signals. MFCCs lose some information from the speech signals; this may occur because of the use of discrete cosine transform (DCT) compression. Second, in the preliminary experiment, we find that the addition of delta and delta-delta cepstra to the MFCCs improves the VAD performance. Delta and delta-delta cepstra are features that express dynamics that refer to the time-varying properties of speech signals [26]. Thus, this result indicates that the dynamics may contribute to improving the VAD performance. Based on the second finding, we attempt to enhance the VAD performance based on the usage of log power spectra, adding the first and second derivatives of the log power spectra. In contrast to the dynamic features, i.e., delta and delta-delta features, which are computed as the first- and second-order derivatives of MFCCs, respectively; here, the derivatives are derived directly from the log power spectra, and these derivatives are used to obtain the speech period candidates, which are derived based on the patterns carried by those derivatives. Figure 1 shows the outline of the proposed method.

Outline of the proposed method
As shown in Fig. 1, first, major speech characteristics are highlighted using a running spectral filter (RSF) [27]. Next, masks are composed using the first and second derivatives of the log power spectra of the RSF output through heuristic rules. These masks, which consist of binary values, are then multiplied by spectra, expressed in decimal form, to obtain speech period candidates. Since not all subband signals may contribute to the VAD decision, we consider obtaining the speech period candidates for individual subbands. These speech period candidates, together with the log power spectra, are input into a DNN to obtain the VAD output. The experimental results show that the proposed method is superior to a DNN-based VAD method that utilizes the log power spectra alone.
The paper is organized as follows. In Section 2, we describe the proposed method for detecting speech periods using a combination of speech period candidates and log power spectra. In Section 3, the experimental results and a discussion of the results are provided. In Section 4, the conclusions of the paper are presented.
2 Proposed method
A speech signal can be analyzed by using a short-time Fourier transform (STFT) as follows:
where x(n) is a speech signal; h(n) is an analysis window, which is time reversed and shifted by m frames; k is a frequency bin variable; K is the number of frequency bins; and \(W_{K}=\exp ^{-j\left (\frac {2\pi }{K}\right)}\). X(m,k) can be further expressed as follows:
As shown in several investigations [28–31], the energy of clean speech signals is mostly concentrated within a modulation frequency range of 1 to 16 Hz. Hence, each subband envelope, |X(m,k)|, is filtered through an RSF to remove noise outside the modulation frequency range, and negative values in the filter output are replaced by zeros [32].
A subband log power spectrum of the RSF output, E(m,k), is expressed as
Hereafter, we call the log power spectrum of the RSF output as LPS-RSF. The first and second derivatives of the log power spectrum, E(m,k), obtained through the above filtering, are calculated as follows:
These derivatives are used to produce speech period candidates that highlight the dynamics in the LPS-RSF. These candidates are used together with the log power spectra, derived from Eq. (2), to detect speech periods in the DNN described in the next subsection. The detailed process is shown in Fig. 2.

Block diagram of the proposed method
2.1 Speech period candidates
In spoken language, an utterance is a continuous piece of speech that has a start and an end and is separated from a successive utterance by a pause. Figure 3 shows the subband observations at 250 and 875 Hz of an utterance /ha/ and the observations’ first and second derivatives of the LPS-RSF obtained using Eqs. (4) and (5). The frame size used to obtain this representation is 20 ms, which implies that each frame consists of 160 samples, and the analysis window is a Hamming window with a 10-ms frame shift.

Subband observations of utterance /ha/, log power spectra, and their first and second derivatives. Blue and red lines represent first and second derivatives, respectively. a Subband at 250 Hz. b Subband at 875 Hz
As shown in Fig. 3, the starting and ending points of the utterance /ha/ may be identified from the patterns of the first and second derivatives. The starting and ending point candidates of utterance /ha/ in the subband at 250 Hz are located at frames 6 and 33, respectively. In contrast, in the subband at 875 Hz, the starting and ending point candidates are found to lie at frames 6 and 30, respectively. These observations indicate that not all subband signals may contribute to the VAD decision. Therefore, we calculate the first and second derivatives for the individual subbands to obtain the speech period candidates.
We will use Fig. 4 to explain the mechanism for identifying the starting (Fig. 4a) and ending (Fig. 4b) points. These two figures show the observation frames. To determine the starting and ending points, the speech signal is observed in segments of eight frames with an overlap of four frames. The rules for identifying the starting and ending points are as follows:
-
(i)
To identify a starting point, we consider eight frames at once and check the former four frames, as shown in Fig. 4a. We observe these frames to find a frame that has the local maximum second derivative followed by a positive first derivative in the successive frame. When this pattern holds, such frame becomes a starting point candidate. This process continues for the successive eight frames with an overlap of four frames from the previous observation.
Fig. 4 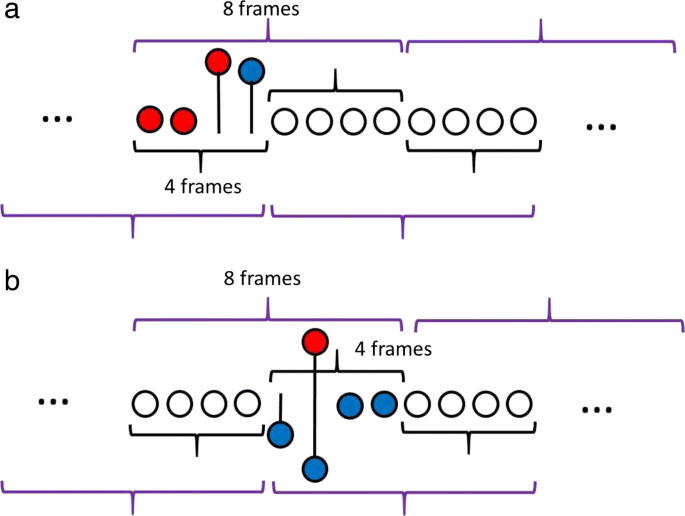
Method of identifying the starting and ending points. a Starting point. b Ending point
-
(ii)
To identify an ending point, we consider eight frames at once and check the subsequent four frames, as shown in Fig. 4b. We observe these frames to find a frame that has the combination of a local minimum first derivative and a local maximum second derivative that is preceded by at least one negative first derivative. When this pattern holds, such frame becomes an ending point candidate. This process continues for the successive eight frames overlapped with four frames from the previous observation.

The above two processes continue until the last observation frames have been examined.
The starting and ending point candidates that are found based on rules (i) and (ii) are marked by the simple binary number of one. Figure 5b shows the starting and ending point candidates of the speech signal. We then simply add the binary ones between the starting and ending points to obtain masks, as shown in Fig. 5c.

Representation of a speech signal (a), its starting and ending point candidates using rules (i) and (ii) (b), masks (c), and speech period candidates as a result of multiplying masks by the spectra expressed in decimal form (d)
The masks, however, may cause misjudgments for non-speech periods because such masks do not carry information coming from the amplitude of the observed signal. To minimize such misjudgment, we attempt to remove values of “one” coming from the signal parts when the amplitudes are relatively small simply by multiplying the raw spectra expressed in decimal by the masks. Hereafter, the output of this process is referred to as speech period candidates. The result of the process is shown in Fig. 5d. These speech period candidates, together with the log power spectra from Eq. (2), become input for the DNN. The same signal that is smeared by factory noise is shown in Fig. 6a. Figure 6d shows the speech period candidates for the noisy signal smeared with factory noise (−5 dB).

Representation of the speech signal smeared by factory noise (−5 dB) (a), its starting and ending point candidates using rules (i) and (ii) (b), masks (c), and speech period candidates as a result of multiplying masks by the spectra expressed in decimal form (d)
2.2 DNN-based VAD
DNNs have been shown to be effective in various speech applications, including the detection of speech periods, as shown in [22]. According to [33], a DNN is a conventional multilayer perceptron (MLP) with many hidden layers. For simplicity, for an L+1-layer DNN, the input layer is regarded as layer 0, and the output layer is considered layer L. In the first L layers, an activation vector aℓ is obtained as follows:
where \(\mathbf {z}^{\ell }\in \mathbb {R}^{\mathbf {N}_{\ell } \times 1}\) is an excitation vector, \(\mathbf {W}^{\ell }\in \mathbb {R}^{\mathbf {N}_{\ell } \times \mathbf {N}_{\ell -1}}\) is a weight matrix, \(\mathbf {b}^{\ell } \in \mathbb {R}^{\mathbf {N}_{\ell } \times 1}\) is a bias vector, and \(\mathbf {N}_{\ell }\in \mathbb {R}\) is the number of neurons in layer ℓ. \(f(.):\in \mathbb {R}^{N_{\ell } \times 1} \rightarrow \mathbb {R}^{N_{\ell } \times 1}\) is an activation function applied to the excitation vector element-wise z. Here, the sigmoid function
is used.
In the input layer, \(\mathbf {a}^{0}=\mathbf {P}(m,k)\in \mathbb {R}^{N_{0}\times 1}\) denotes the input feature vector of the DNN, where P(m,k) denotes the log power spectra and the speech period candidates. P(m,k) is used as a learning instance and is mapped onto the correct speech periods that are identified during the training process.
In the output layer for classification tasks such as VAD, each output neuron represents a class i∈{1,…,C}, where C=NL is the number of classes. In the output layer, a softmax function is added as a linear classifier for VAD:
where \(z_{i}^{L}\) is an ith element of the excitation vector zL. The value of the ith output neuron \(\mathrm {a}_{i}^{L}\) represents the probability Pdnn(i|P) that the observation P(m,k) belongs to class i (speech or non-speech).
The training process for the DNN mentioned above consists of two stages. First, a greedy layer-wise unsupervised learning procedure is performed as the pre-training stage. Next, fine-tuning is performed on the entire network [34]. The DNN considered in this study is composed of five layers of restricted Boltzmann machines (RBMs), which consist of visible and hidden units. Here, Bernoulli (visible)–Bernoulli (hidden) RBMs, i.e., vℓ∈{0,1} and hℓ∈{0,1}, are used. Once the learning process has been completed for an RBM, the activity values of its hidden units can be used as the feature input for training the next RBM [35]. A contrastive divergence algorithm is used in the pre-training stage to approximate the gradient of the negative log likelihood of the data with respect to the RBM’s parameters [36]. After the layer-by-layer pre-training stage, a backpropagation technique is applied throughout the entire net to fine-tune the weights to obtain optimal results [37]. Because the VAD output consists of two classes (i.e., speech and non-speech), the DNN-based VAD output for each frame is a binary vector whose elements are determined as follows:
The DNN outputs trains of 1s (ones) representing the speech periods.
3 Experimental results and discussion
3.1 Experimental setup
In the experiments, we use 99 speech files from the ASJ Continuous Speech Corpus for Research vol. 2 [38]. These speech files are divided equally into three data sets. Then, we create three groups, each with 66 files for training (a combination of two data sets to obtain three distinct groups), and the rest of the speech files are used for evaluation purposes. The objective of dividing the data is to evaluate the proposed method inside a different data set. To obtain noisy signals, the clean speech files are mixed with five types of noise, white, babble, factory, car, and pink, from NOISEX-92 [39]. Each noise signal is differently selected for the speech files as well as SNRs of 10, 5, 0, and −5 dB. Thus, 21 sets of data are used to produce 1386 speech files for the training of each group.
In this work, the input signals are sampled at 8 kHz. The frame size is 20 ms, and the analysis window is a Hamming window with a 10-ms frame shift. After the RSF filtering process, the LPS-RSF is calculated for an individual subband using Eq. (3). Next, the first and second derivatives for each subband are calculated using Eqs. (4) and (5). These derivatives are used to obtain the starting and ending point candidates in accordance with rules (i) and (ii). After the conversion of the starting and ending point candidates from the sparse representation to the masks, the masks are multiplied by the spectra, expressed in decimal form to obtain speech period candidates. Then, the DNN is applied to the speech period candidates in combination with the log power spectra derived from Eq. (2). This combination (i.e., the dynamic features) is fed to the DNN to obtain the final VAD decision regarding the speech periods. The dynamic features are normalized to zero mean and unit variance in each dimension. To train the DNN, we use five RBMs. These RBMs are stacked together, and the number of neurons for each RBM is 200, 200, 200, 200, and 100, in sequence. The learning rate is 0.0001, and the maximum number of epochs for both the pre-training and fine tuning stages is 200.
Note that, after determining the speech and non-speech periods, we did not perform any post processing, such as a VAD hangover, because such processing is outside the scope of this paper.
3.2 Results and discussion
The VAD decisions on noisy signals smeared with factory noise at various SNRs are shown in Fig. 7. In Fig. 7, the red dashed lines indicate the true speech and non-speech periods, whereas the solid magenta lines represent the generated VAD output. As shown in the figure, the output of the proposed VAD method is reasonably close to the ground truth.

Representative results of the proposed VAD method. a Clean speech. b Factory noise, SNR = 10 dB. c Factory noise, SNR = 5 dB. d Factory noise, SNR = 0 dB. e Factory noise, SNR = − 5 dB
To evaluate the effectiveness of the proposed method, we compare it with the DNN-based VAD method, which only utilizes the log power spectra, as the baseline of the evaluation.
To represent the performance of the proposed method, the receiver operation characteristic (ROC) curve, in which true positive rate (TPR) is plotted against false positive rate (FPR), is considered. The TPR, or sensitivity, and FPR are defined based on the number of true positives (TPs), false positives (FPs), true negatives (TNs), and false negatives (FNs) as follows [40]:
To obtain a quantitative ROC value, the area under the curves (AUCs) are calculated. These AUCs are the main metric for evaluation.
Table 1 compares the average of the AUCs achieved by the DNN-based VAD methods using the log power spectra alone, the speech period candidates alone, and the proposed method. As shown in Table 1, the proposed method may improve the performance of the DNN-based VAD method using the log power spectra for all cases. As shown in Fig. 8, a relatively good improvement is obtained in low SNR cases. The highest improvement occurs at − 5 dB, for example, the performance improves by 6.52% for babble noise at − 5 dB.

Improvement of VAD performance
This method is also applied to SNR environments (7, 3, − 3, and − 7 dB) that are not known scenarios. The results for such SNR environments are shown in Table 2. The results in Tables 1 and 2 are from the known and unknown scenarios, respectively. Both tables show that the proposed method is able to enhance the usage of the log power spectra, even for the unknown SNR environments.
To evaluate the effect of introducing the speech period candidates, we measure the TPR (sensitivity) and the true negative rate (TNR or specificity). Sensitivity gives the percentage of the frames that were correctly classified as speech from all the speech frames in the signal, and specificity gives the percentage of the frames that were correctly classified as non-speech from all the non-speech frames in the signal [41].
Figure 9 shows the mean TPR (sensitivity) and TNR (specificity). As shown in the figure, the proposed method has a high sensitivity and specificity for both the clean and noisy cases. Interestingly, the performance of the DNN-based VAD method using speech period candidates approaches and even outperforms the log power spectra in finding speech, as shown in Fig. 9a, particularly for low SNRs and non-stationary cases. This fact may imply that the addition of speech period candidates is useful to find speech periods in low SNRs and non-stationary cases. Additionally, the specificity of speech period candidates is higher than the log power spectra as shown in Fig. 9b. This fact may imply that the speech period candidates may improve the log power spectra for finding non-speech periods. Thus, the speech period candidates may carry valuable information for judging speech and non-speech detection. In the proposed method, the addition of the speech period candidates is effective at improving the accuracy of the log power spectra at finding speech and non-speech periods, especially for low SNRs and non-stationary cases.

Sensitivity and specificity comparison between the proposed method and the DNN-based VAD methods using speech period candidates and log power spectra. a TPR (sensitivity). b TNR (specificity)
Figure 10 shows the ROC curves for the proposed method and the DNN-based VAD methods using speech period candidates and log power spectra, respectively, at an SNR of − 5 dB. As shown in the figure, the proposed method shows an advantage over the DNN-based VAD method using the log power spectra. The proposed method is effective for low SNR cases. In the cases of stationary noise, such as white and pink noise, the working points of the proposed method are close to those of the DNN-based VAD method using the log power spectra. These methods achieve a high TPR and a low FPR. In the cases of non-stationary noise, such as babble and factory noise, the proposed method is less affected by the noise than the DNN-based VAD method using the log power spectra. The performance of the proposed method is superior to that of the DNN-based VAD method using the log power spectra mainly due to introducing dynamics expressed by speech period candidates. To evaluate its effectiveness, the proposed method is also compared to other methods (Appendix Appendix 2: comparison to conventional methods, Table 5).

ROC curves for the proposed method and for DNN-based VAD methods using log power spectra and speech period candidates, respectively. a White noise, SNR = − 5 dB. b Babble noise, SNR = − 5 dB. c Factory noise, SNR = − 5 dB. d Car noise, SNR = − 5 dB. e Pink noise, SNR = − 5 dB
In addition to the contribution of the speech period candidates, which may highlight dynamics, we attempt to find useful subbands for obtaining VAD decisions in the employed DNN. We evaluate which subbands have more valuable information than the others, by finding the similarity between the input (i.e., speech period candidates) and the VAD output. This similarity is evaluated by employing mutual information (MI), which aims to measure whether the inputs are dependent on the associated labels (VAD output). According to [42], the MI between the discretized feature values a and the class labels y is evaluated according to the formula
where p(a,y) is a joint probability function of a and y and p(a) and p(y) are marginal probability distribution functions of a and y, respectively. Here, the feature values, a, are the input of the DNN (speech period candidates), and the class labels, y, are the VAD output. The larger the MI, the higher the dependency between the feature values, which represent speech period candidates for individual subbands, and the class labels (VAD output). Here, we rank the subbands according to their scores.
Table 3 shows the top 4 subband ranks using MI. As shown in Table 3, the top 4 ranks for clean, and noisy signals show a similar tendency for frequency bins 6, 7, 8, and 9 (156.25 Hz, 187.5 Hz, 218.75 Hz, and 250 Hz). Such subband may play some roles in obtaining the VAD decision in the proposed method. To clarify this, we perform experiments in which the four top subband values in the proposed method are replaced with zeros, and the resulting VAD performance is shown in Fig. 11.

VAD performance of the proposed method after replacing the subband values of top 4 ranks and the lowest 4 ranks with zeros
As shown in Fig. 11, at a high SNR, the performance of the proposed method is only slightly degraded when the subbands of 156.25 Hz, 187.5 Hz, 218.75 Hz, and 250 Hz are replaced by zeros. In low SNR cases, the subbands are polluted by noise. Consequently, the performance might be degraded, and this degradation worsens when these top 4 subbands are not utilized. In contrast, when the four lowest subband values are replaced by zeros, the output accuracy can still be maintained. These results indicate that the top 4 subbands have a relatively important role in the decision-making process of the proposed method. We observe that the information carried by these subbands may correspond to the average of F0 or its neighbors (the average F0 for the data is 179.97 Hz, the average F0 for male is 149.09 Hz and 210.84 Hz for female; the F0s are measured using STRAIGHT algorithm [43]). Thus, in the proposed method, the DNN may utilize information coming from the useful subbands which may correspond to F0 and its neighbors.
4 Conclusions
This study presents a DNN-based VAD method for improving the performance of VAD by introducing dynamics, which may be highlighted by speech period candidates. These candidates are derived from heuristic rules based on the first and second derivatives of the log power spectrum of the RSF output (LPS-RSF). The speech period candidates are calculated for individual subbands and are then input into a DNN together with the log power spectra to generate the VAD decision. To evaluate the performance of the proposed method, we perform experiments using clean and noisy speech signals smeared with five types of noise, namely, white, babble, factory, car, and pink, with SNRs of 10, 5, 0 and − 5 dB. The proposed method effectively detects speech and non-speech periods. The experimental results show that the VAD performance based on log power spectra are improved after combining the log power spectra with the speech period candidates, particularly for noisy speech signals with low SNRs and non-stationary cases. The addition of dynamics expressed by the speech period candidates provides positive information that contributes to the detection of speech periods.
In this study, we also show that the DNN-based VAD utilizes subbands that may correspond to F0 and its neighbors. The VAD performance degrades when those subbands are eliminated. However, further studies should be performed to analyze other factors that influence the behavior of the employed DNN. Moreover, we intend to make the proposed method work in real time.
5 Appendix 1: preliminary experiment
In the preliminary experiment, we compared DNN-based VAD methods using log power spectra and “hand-crafted” features that are frequently used in speech processing, i.e., MFCC, delta features, and delta-delta features. All of these features were input into the DNN using the same configuration and parameters as mentioned in Section 3. The MFCCs were calculated using the same window length of 20 ms and the same shift of 10 ms. We consider 13 MFCCs augmented with delta features and delta-delta features, resulting in 39 combined features.
As shown in Table 4, the DNN-based VAD performance that was achieved using the log power spectra is superior to that achieved using the MFCCs and that using MFCCs in combination with their delta and delta-delta cepstra. The log power spectra features capture more detailed information in the time-frequency domain. Consequently, these features represent a variety of important information that may be related to the speech characteristics. In contrast, the MFCCs may suffer from information loss, which may occur due to the dimension reduction caused by the DCT compression. In the preliminary study, the DNN-based VAD performance that was achieved using the MFCCs is slightly improved when temporal derivatives, i.e., delta and delta-delta features, are considered in combination with the MFCCs. The enhancement achieved by using the MFCCs in combination with the delta and delta-delta cepstra implies that the dynamics that are expressed by delta and delta-delta cepstra play a role in improving the VAD performance.
6 Appendix 2: comparison to conventional methods
To evaluate the effectiveness of the proposed method, we also compare it with four other methods presented in [8, 11, 12, 44].
Table 5 shows the AUC results of the proposed method and the other methods. As shown in the table, the proposed method outperforms the other methods in [8, 11, 12, 44] for both clean and noisy signals. The performance of the method in [12], which utilizes a statistical method, approaches the performance of the method in [11], which utilizes MFCCs and a Gaussian mixture model (GMM) as the classifier. Their performance worsens for non-stationary noise. Alternatively, the method in [44] can give better performance for non-stationary and low SNRs than the method in [8]. The proposed method is superior to that of the other methods because it uses the advantages of using a DNN with features as the input, i.e., speech period candidates and log power spectra.
References
K. Sakhnov, E. Verteletskaya, B. Simak, Approach for energy-based voice detector with adaptive scaling factor. IAENG Int. J. Comput. Sci.36:, 394 (2009).
F. Beritelli, S. Casale, G. Ruggeri, in Proc. IEEE Int Conf on Acoustics, Speech, and Signal Processing. Performance evaluation and comparison of ITU-T/ETSI voice activity detectors (IEEESalt Lake City, 2001), pp. 1425–1428.
A. Benyassine, ITU-T Recommendation G. 729 Annex B: a silence compression scheme for use with G. 729 optimized for V. 70 digital simultaneous voice and data applications. IEEE Commun. Mag.35:, 64–73 (1997).
S. Tong, N. Chen, Y. Qian, K. Yu, in Proc. IEEE Int Conf On Signal Processing. Evaluating vad for automatic speech recognition (IEEEHangzhou, 2014), pp. 2308–2314.
S. Graf, T. Herbig, M. Buck, G. Schmidt, Features for voice activity detection: a comparative analysis. EURASIP J. Adv. Sign. Process.2015:, 91 (2015).
L. R. Rabiner, M. R. Sambur, An algorithm for determining the endpoints of isolated utterances. Bell Labs Tech. J.54:, 297–315 (1975).
R. V. Prasad, A. Sangwan, H. S. Jamadagni, M. C. Chiranth, R. Sah, V. Gaurav, in Proc 7th Int Symp on Computers and Communications. Comparison of voice activity detection algorithms for VoIP (IEEETaormina-Giardini Naxos, 2002), pp. 530–535.
J. Ramırez, J. C. Segura, C. Benıtez, A. De La Torre, A. Rubio, Efficient voice activity detection algorithms using long-term speech information. Speech Comm.42:, 271–287 (2004).
K. Ishizuka, T. Nakatani, M. Fujimoto, N. Miyazaki, Noise robust voice activity detection based on periodic to aperiodic component ratio. Speech Comm.52:, 41–60 (2010).
K. Pek, T. Arai, N. Kanedera, Voice activity detection in noise using modulation spectrum of speech: investigation of speech frequency and modulation frequency ranges. Acoust. Sci. Technol.33:, 33–44 (2012).
T. Kinnunen, P. Rajan, in Proc. IEEE Int Conf on Acoustic, Speech and Signal Processing. A practical, self-adaptive voice activity detector for speaker verification with noisy telephone and microphone data (IEEEVancouver, 2013), pp. 7229–7233.
J. Sohn, N. S. Kim, W. Sung, A statistical model-based voice activity detection. IEEE Signal Proc. Lett.6:, 1–3 (1999).
A. Davis, S. Nordholm, R. Togneri, Statistical voice activity detection using low-variance spectrum estimation and an adaptive threshold. IEEE Trans. Audio Speech Lang. Process.14:, 412–424 (2006).
T. Kinnunen, E. Chernenko, M. Tuononen, P. Fränti, H. Li, in Proc Int. Conf. on Speech and Computer (SPECOM07). Voice activity detection using MFCC features and support vector machine (Moscow, 2007), pp. 556–561.
Q. H. Jo, J. H. Chang, J. W. Shin, N. S. Kim, Statistical model-based voice activity detection using support vector machine. IET Sign. Process.3:, 205–210 (2009).
D. Enqing, L. Guizhong, Z. Yatong, Z. Xiaodi, Applying support vector machines to voice activity detection, Proc Int Conf on Signal Processing (IEEE, Beijing, 2002).
G. Ferroni, R. Bonfigli, E. Principi, S. Squartini, F. Piazza, in A deep neural network approach for voice activity detection in multi-room domestic scenarios. Proc Int Joint Conference On Neural Networks (IEEEKillarney, 2015), pp. 1–8.
X.L. Zhang, D. Wang, Boosting contextual information for deep neural network based voice activity detection. IEEE/ACM Trans. Audio Speech Lang. Process.24:, 252–264 (2016).
F. Bie, Z. Zhang, D. Wang, T. Zheng, DNN-based voice activity detection for speaker recognition. CSLT Tech. Rep (2015). available online http://www.cslt.org/mediawiki/images/c/c8/Dvad.pdf.
A.R. Mohamed, G.E. Dahl, G. Hinton, in Proc IEEE Int Conf on Acoustics, Speech and Signal Processing. Understanding how deep belief networks perform acoustic modelling (IEEEKyoto, 2012), pp. 4273–4276.
M. Espi, M. Fujimoto, K. Kinoshita, T. Nakatani, Exploiting spectro-temporal locality in deep learning based acoustic event detection. EURASIP J. Audio Speech Music Process.2015(1), 26 (2015).
N. Ryant, M. Liberman, J. Yuan, in INTERSPEECH 2013, 14th Annual Conference of the International Speech Communication Association, ed. by F. Bimbot, C. Cerisara, C. Fougeron, G. Gravier, L. Lamel, F. Pellegrino, and P. Perrier. Speech activity detection on youtube using deep neural networks (Lyon, 2013), pp. 728–731. http://www.isca-speech.org/archive/interspeech_2013.
V.S. Mendelev, T.N. Prisyach, A.A. Prudnikov, Robust voice activity detection with deep maxout neural networks. Mod. Appl. Sci.9(8), 153 (2015).
X.L. Zhang, J. Wu, Deep belief networks based voice activity detection. IEEE Trans Audio Speech Lang. Process.21:, 697–710 (2013).
L. Deng, J. Li, J. Huang, K. Yao, D. Yu, F. Seide, M. Seltzer, G. Zweig, X. He, J. Williams, Y. Gong, A. Acero, in Proc IEEE Int Conf On Acoustics, Speech and Signal Processing. Recent advances in deep learning for speech research at microsoft, (IEEEVancouver, 2013), pp. 8604–8608.
L. Deng, Dynamic speech models: theory, algorithms, and applications. Synth. Lect. Speech Audio Process.2(1), 1–118 (2006).
K. Fujioka, N. Hayasaka, Y. Miyanaga, N. Yoshida, Noise reduction of speech signals by running spectrum filtering. Syst. Comput. Jpn. 37:, 52–61 (2006).
N. Kanedera, T. Arai, H. Hermansky, M. Pavel, On the relative importance of various components of the modulation spectrum for automatic speech recognition. Speech Commun.28:, 43–55 (1999).
H. Hermansky, N. Morgan, RASTA processing of speech. IEEE Trans. Speech Audio Process.2:, 578–589 (1994).
L. Atlas, S.A. Shamma, Joint acoustic and modulation frequency. EURASIP J. Adv. Sign. Process.2003:, 310–290 (2003).
T. Arai, M. Pavel, H. Hermansky, C. Avendano, Syllable intelligibility for temporally filtered LPC cepstral trajectories. J. Acoust. Soc. Am.105:, 2783–2791 (1999).
Q. Zhu, N. Ohtsuki, Y. Miyanaga, N. Yoshida, in Proc IEEE Int Symp on Communications and Information Technology. Robust speech analysis in noisy environment using running spectrum filtering (IEEESapporo, 2004), pp. 995–1000.
D. Yu, L. Deng, Automatic speech recognition A deep learning approach (Springer, London, 2014).
H. Larochelle, Y. Bengio, J. Louradour, P. Lamblin, Exploring strategies for training deep neural networks. J. Mach. Learn. Res.10:, 1–40 (2009).
G.E. Hinton, Learning multiple layers of representation. Trends Cogn. Sci.11:, 428–434 (2007).
M.A. Carreira-Perpinan, G.E. Hinton, On contrastive divergence learning. AISTATS. 10:, 33–40 (2005).
M.A. Keyvanrad, M.M. Homanyounpour, A brief survey on deep belief networks and introducing a new object oriented toolbox (DeeBNet).arXiv preprint arXiv:1408.3264. (2014). https://arxiv.org/abs/1408.3264.
T. Kobayashi, S. Itabashi, S. Hayashi, T. Takezawa, ASJ continuous speech corpus for research. J. Acoust. Soc. Jpn. 48:, 888–893 (1992).
The Rice University, “Noisex-92 Database”. http://spib.linse.ufsc.br/noise.html. Accessed 22 Feb 2017.
R.O. Duda, P.E. Hart, D.G. Stork, Pattern classification, 2nd edn (New York, 2001).
M. Myllymäki, T. Virtanen, in Proc 16th European Signal Processing Conference. Voice activity detection in the presence of breathing noise using neural network and hidden markov model (IEEELausanne, 2008), pp. 1–5.
J. Pohjalainen, O. Räsänen, S. Kadioglu, Feature selection methods and their combinations in high-dimensional classification of speaker likability, intelligibility and personality traits. Comput Speech Lang.29(1), 145–171 (2015).
H. Kawahara, I. Masuda-Katsuse, A. De Cheveigne, Restructuring speech representations using a pitch-adaptive time–frequency smoothing and an instantaneous-frequency-based F0 extraction: Possible role of a repetitive structure in sounds. Speech Commun.27(3), 187–207 (1999).
M.V. Segbroeck, A. Tsiartas, S. Narayanan, in Proc INTERSPEECH 2013, 14th Annual Conference of the International Speech Communication Association, ed. by F. Bimbot, C. Cerisara, C. Fougeron, G. Gravier, L. Lamel, F. Pellegrino, and P. Perrier. A robust frontend for VAD: exploiting contextual, discriminative and spectral cues of human voice (Lyon, 2013), pp. 704–708. http://www.isca-speech.org/archive/interspeech_2013.
Author information
Authors and Affiliations
Contributions
All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License(http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Dwijayanti, S., Yamamori, K. & Miyoshi, M. Enhancement of speech dynamics for voice activity detection using DNN. J AUDIO SPEECH MUSIC PROC. 2018, 10 (2018). https://doi.org/10.1186/s13636-018-0135-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13636-018-0135-7