- Research Article
- Open access
- Published:
Ageing Voices: The Effect of Changes in Voice Parameters on ASR Performance
EURASIP Journal on Audio, Speech, and Music Processing volume 2010, Article number: 525783 (2010)
Abstract
With ageing, human voices undergo several changes which are typically characterized by increased hoarseness and changes in articulation patterns. In this study, we have examined the effect on Automatic Speech Recognition (ASR) and found that the Word Error Rates (WER) on older voices is 10% absolute higher compared to those of adult voices. Subsequently, we compared several voice source parameters including fundamental frequency, jitter, shimmer, harmonicity, and cepstral peak prominence of adult and older males. Several of these parameters show statistically significant difference for the two groups. However, artificially increasing jitter and shimmer measures do not effect the ASR accuracies significantly. Artificially lowering the fundamental frequency degrades the ASR performance marginally but this drop in performance can be overcome to some extent using Vocal Tract Length Normalisation (VTLN). Overall, we observe that the changes in the voice source parameters do not have a significant impact on ASR performance. Comparison of the likelihood scores of all the phonemes for the two age groups show that there is a systematic mismatch in the acoustic space of the two age groups. Comparison of the phoneme recognition rates show that mid vowels, nasals, and phonemes that depend on the ability to create constrictions with tongue tip for articulation are more affected by ageing than other phonemes.
1. Introduction
Older people form an important user group for a variety of spoken dialogue systems. Systems with speech-based interactions can be particularly useful for older people with mobility restrictions and visual impairment. One of the main challenges in developing such systems is to build Automatic Speech Recognition (ASR) systems that give good performance on older voices.
With ageing, several changes occur in the human speech production mechanism consisting of the lungs, vocal cords, and the vocal cavities including the pharynx, mouth, and nose.
In the respiratory system, loss of elasticity [1], stiffening of the thorax, reduction in respiratory muscle strength [2], and loss in the diaphragm strength [3] are the most significant changes. This leads to a reduction in forced expiratory volume and lung pressure in older people, as a result of which there is a decline in the amount of air that moves in and out and the efficiency with which it moves [4, 5].
Changes in the larynx that occur during old age, such as stiffening of the cartilages [6] to which the vocal cords are attached and degeneration of intrinsic muscles [7], reduce the ease of vocal fold adjustments during phonation [8]. Increase in the stiffness of vocal cord cover is also observed, leading to instability of the vocal fold vibrations [7]. Thickening of laryngeal epithelium progressively with age has been reported [9] which may contribute to the lowering of fundamental frequency and increased harshness observed in older voices.
Changes observed in the vocal cavity include degeneration of pharyngeal muscles, decline in salivary function, loss of tongue strength and tooth loss [4, 10]. Degenerative changes are also observed in the temporomandibular joint which controls the jaw movement during speech production [11]. These changes could considerably affect the articulation of speech. Changes in vocal tract dimensions have also been observed in older speakers [12], which may affect the resonance patterns in older speakers resulting in reduction of articulatory precision.
There is, however, a large variability in the extent and the rate at which voices age. Vocal ageing is not only dependent on chronological age, but also on several other factors that influence voice such as lifestyle, medical condition, smoking habits, and profession of the person.
Although there have been numerous studies on the effects of ageing on voice, there has been limited work to understand how these changes affect the performance of Automatic Speech Recognition (ASR) systems. Higher Word Error Rates (WERs) of about 9–12% absolute in older voices as compared to adult voices have been reported in [13, 14]. In a study of speech recognition for the children and older people [15], it was found that the WERs increased dramatically for voices above 70 years of age.
Apart from the difference in acoustics, older people also appear to differ in linguistic characteristics when interacting with Spoken Dialogue Systems (SDS) [16]. They tend to use a lot of words compared to younger adults in their queries and talk to systems as if they were humans [17]. This kind of interaction style also needs to be accommodated into the design of ASR systems [18] by appropriate language modeling targeted towards the user age group.
The speech production mechanism can be viewed as a source filter model, where the glottal excitation represents the source and the vocal tract acts as the filter modifying the excitation to generate the desired sounds. In this article, we focus on the voice parameters that capture the source characteristics of the speech and attempt to understand the effect of changes in these parameters on ASR accuracies. We have compared several important voice characteristics such as the fundamental frequency, jitter, shimmer, harmonicity, and cepstral peak prominance of adult and older voices and wherever the measures differ significantly, we analysed the effect of changes in these parameters on ASR performance. We have also compared the average likelihoods of the phonemes and phoneme error rate to find out if the drop in ASR performance with ageing is due to changes in articulation patterns of a subset of the phonemes.
The organisation of the rest of this article is as follows. In Section 2, the ASR experimental setup is described and the ASR performance on adult and older voices are compared. Voice parameters of the two age groups are compared and their effect on ASR performance is analysed in Section 3. In Section 4, the likelihood scores and phoneme error rates for the two age groups are compared. The results are discussed in Section 5 followed by conclusions in Section 6. Wherever suitable, the results have been shown in graphs and the relevant numbers are tabulated in the Appendix.
2. ASR Performance
2.1. Corpus
Most of the speech corpora used in ASR research have inadequate representation of older voices. The Supreme Court of the United States (SCOTUS) speech corpus [19] was found appropriate for our experiments as it has sufficient speech data from healthy older and adult voices. One advantage of this corpus for ASR experiments is that the recording setup for the court proceedings has remained the same over a period of time and hence the variations in noise and microphone characteristics are minimal. The other advantage is that the language used in the Supreme Court is formal and is fairly similar across all the speakers.
The SCOTUS corpus has been made public under the Oyez project (http://www.oyez.org/). Each court case recording's duration is about one hour and consists of speech from the advocates and judges arguing the case. These recordings were archived on reel-to-reel tapes, which were later digitized and made public.
The recordings from later half of 1990s until 2005 have been used in our experiments. In all, the experimental corpus contains 534 recordings. It consists of speech from 10 Judges over several years and about 500 advocates. The birth dates of the Judges are known and hence their age at the time of an argument can be precisely calculated. The birth dates of the advocates are not easily available, hence wherever the birth dates were not available, their age has been approximated by using the year of their law graduation and assuming their age at graduation to be 25.
In order to obtain the sentence boundaries and speaker turn alignments in each of these one-hour-long audio recordings, forced alignment was performed on each recording using acoustic models trained on 73 hours of meetings data recorded by the International Computer Science Institute (ICSI), 13 hours of meeting corpora from the National Institute of Standards and Technology (NIST) and 10 hours of corpora from Interactive Systems Laboratory (ISL) [20].
Using this corpus, we have built a state of the art ASR system using the Hidden Markov Model Toolkit (HTK) (HTK version 3.4 http://htk.eng.cam.ac.uk/).
2.2. Feature Extraction
The SCOTUS corpus in MP3 format was first converted to 16 kHz wav format and then parametrised using perceptual linear prediction (PLP) Cepstral features. A window size of 25 ms and frame shift of 10 ms were used for feature extraction. Energy along with 1st and 2nd order derivatives were appended giving a 39-dimensional feature vector.
Cepstral means and variances were computed for each speaker in each recording. These were then used to normalise the feature vectors to minimise any channel introduced effects.
2.3. Acoustic Models
The acoustic models were trained on 90 hours of speech data from 279 speakers. A major portion of the entire corpus is from males, hence the training data set is also similarly skewed in favour of males with around 77 hours of speech from 189 male speakers and 13 hours of speech from 75 female speakers. Age information of only 61 of the training set speakers is available. The average age computed over these speakers is 44.3 years (Std.Dev: 10.1). Since most of the speakers used in the training set are Advocates in the Supreme Court, the average age over all the speakers is expected to lie in the range of 40–50 years.
The acoustic models have been trained as cross-word context-dependent triphone Hidden Markov Models (HMM) [21], each state modeled as 18 components Gaussian Mixture Model (GMM) for all speech phones and 36 components GMM for nonspeech (sil & short pause) models, respectively.
2.4. Language Models
The language models were constructed from the transcripts of 260 United States Supreme Court recordings from the 1970s comprising of about 2.5 million words. Back off bigram language models [22] were constructed from this data. The vocabulary consists of 23445 words. The pronunciations used in the AMI vocabulary [20] were used for those vocabulary words common to AMI and the pronunciations for the rest of the vocabulary words were generated using the Festival speech synthesis system [23].
2.5. Test Utterances
For the adult test set, speech utterances from 27 speakers (23 Males and 4 Females) in an age range of 30–45 (Average: 41.3) were chosen. For the older test set, speech data from 12 speakers (10 Males and 2 Females) in the age range of 60–85 (Average: 68.4) were used. The speaker set used for testing is disjoint from the training set speakers. 10 utterances (about 130 seconds on average) for each test speaker were kept aside for speaker adaptation and the remaining utterances formed the test set. In all the adult test set comprises of 4323 utterances (12.5 hours) and the older test set comprises of 6410 utterances (18 hours). The perplexity [22] of the language model on the adult test set is 178.3 with Out Of Vocabulary (OOV) rate of 3.8% and on the older test set is 169.7 with OOV rate of 4.3%.
2.6. ASR Word Error Rates
The ASR word error rates on adult and older test sets are seen in Figure 1. The results show a significant difference of 10% absolute higher WERs for older voices as compared to adult voices. The WERs difference for males is 8.7% absolute while for females it is 13.7%. The differences in WERs are statistically significant with  using the Mann-Whitney test [24].
using the Mann-Whitney test [24].

Comparison of WER on adult and older voices.
Speaker adaptation and speaker normalisation techniques are often used to improve ASR performance [25]. We have used the standard Maximum Likelihood Linear Regression (MLLR) mean adaptation [26] to see if speaker adaptation can alleviate age-induced errors in ASR. Using the adaptation set of 10 utterances for each speaker, MLLR transforms were computed for each speaker and used in decoding the test utterances. One of the main sources of interspeaker variability in acoustic features is the variation in vocal tract dimensions. Vocal Tract Length Normalisation (VTLN) is a standard approach used to overcome this variability. Vocal tract length normalised acoustic models were constructed using an iterative approach as described in [27]. Using the normalised models, warping factors were estimated for each of the test speakers from the adaptation set utterances.
From Figure 1, we observe that though speaker adaptation and speaker normalisation improve the recognition performance marginally, the gap between the WERs for adult and older voices is not bridged. The results for females may not be a true representation of the difference as the sample set is very small, but overall the difference in WERs seems to be large enough for investigation into the possible causes.
3. Voice Parameter Analysis
Since the number of female speakers in the corpus is very small, we used only the male speakers test set for voice analysis. This also helps to keep the analysis free from gender-related effects. We have analysed and compared the samples of phoneme "aa" from adult and older male speakers.
Voice analysis is typically carried out on sustained vowel pronunciations in a noise-free recording environment. However the SCOTUS corpus is spontaneous speech with a considerable amount of background noise. Being spontaneous in nature, the corpus also does not have sustained vowel pronunciations with durations over few seconds. Most of the samples of the vowels are typically a fraction of a second long and are part of a longer utterance. In order to pick the best available instances of the phoneme "aa" from the speech the following procedures were used.
-
(1)
Each utterance was force aligned to triphone transcription, in order to determine the frame boundaries and the likelihood of each triphone in the utterance.
-
(2)
All the triphone samples with the centre phoneme "aa" were selected.
-
(3)
Out of the selected samples, the ones with negative log likelihood greater than a threshold of 1000 were rejected.
-
(4)
From the remaining, those samples having a duration less than 0.1 seconds were rejected, to get the final set of vowel "aa" samples for analysis.
In all, 2970 samples of "aa" from 23 adult male speakers and 2105 samples from 10 older male speakers were used for voice analysis. Several voice parameters such as the fundamental frequency, jitter, shimmer, and harmonicity measures were computed for the selected samples using "Praat" [28].
Apart from these parameter computations on sustained vowels, using complete speech utterances cepstral peak prominence measures and speaking rates were computed and analysed.
Each of the following subsections deals with one voice parameter analysing if there is a significant difference in the parameter value between adult and older speakers. Wherever the difference is significant, we artificially modify those parameters in clean speech to analyse the effect on ASR performance.
3.1. Fundamental Frequency (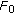 )
)
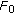 )
)Among the several parameters affected by ageing, the fundamental frequency  has been one of the most extensively studied. There is no general agreement on the trend of changes in
has been one of the most extensively studied. There is no general agreement on the trend of changes in  due to ageing. While results reported in [29, 30] indicate that the
due to ageing. While results reported in [29, 30] indicate that the  reduces significantly by about 40–60 Hz for both males and females above 60 years of age, the results reported in [4, 31] suggest that
reduces significantly by about 40–60 Hz for both males and females above 60 years of age, the results reported in [4, 31] suggest that  decreases in females after menopause but in males, it decreases till a certain age around 60 years and increases again.
decreases in females after menopause but in males, it decreases till a certain age around 60 years and increases again.
The results of the analysis of fundamental frequency are tabulated in Table 1. We observe that the fundamental frequencies for older voices are about 15 Hz (10%) lower than those of adult male voices. The differences in  measures are statistically significant at
measures are statistically significant at  using Mann-Whitney rank sum test.
using Mann-Whitney rank sum test.
 Analysis.
Analysis.In order to understand the effect of reduction in  on ASR performance, we artificially reduce the
on ASR performance, we artificially reduce the  by 10% and compare the WERs of the original waveforms and modified waveforms. The factor of 10% was used to reflect the difference in adult and older voices. For this experiment, the ASR system is the same as that described in Section 2. We use 400 utterances from 8 adult speakers (4 Males and 4 Females) as the test set. For each waveform, the pitch tier is calculated using using Praat. The frequencies are then scaled to 0.9 of their original value. Using the new pitch tier, the waveforms are resynthesized using pitch synchronous overlap and add (PSOLA) method [32]. Figure 2 shows an example of the waveforms and
by 10% and compare the WERs of the original waveforms and modified waveforms. The factor of 10% was used to reflect the difference in adult and older voices. For this experiment, the ASR system is the same as that described in Section 2. We use 400 utterances from 8 adult speakers (4 Males and 4 Females) as the test set. For each waveform, the pitch tier is calculated using using Praat. The frequencies are then scaled to 0.9 of their original value. Using the new pitch tier, the waveforms are resynthesized using pitch synchronous overlap and add (PSOLA) method [32]. Figure 2 shows an example of the waveforms and  contours before and after pitch manipulation.
contours before and after pitch manipulation.

Modification in F0. (a) Original: Waveform (b)F0 Modified: WaveformOriginal: (c) F0 (d) contourModified: F0 contour
The word error rates before and after reduction in pitch are given in Table 2. The WER increases by 1.1% absolute to 33.2% and is statistically significant with  using the Matched pair sentence segment word error (MAPSSWE) test [33]. In order to be able to attribute the increase in WER to the change in fundamental frequency and not to the resynthesis process, we repeated the resynthesis process described above without modifying the pitch tier. The WER for the resynthesized waveforms is 32.0 and the difference with respect to the original waveform is statistically insignificant with
using the Matched pair sentence segment word error (MAPSSWE) test [33]. In order to be able to attribute the increase in WER to the change in fundamental frequency and not to the resynthesis process, we repeated the resynthesis process described above without modifying the pitch tier. The WER for the resynthesized waveforms is 32.0 and the difference with respect to the original waveform is statistically insignificant with  using MAPSSWE test.
using MAPSSWE test.
 .
.We also perform VTLN calculating the warping factors for each speaker separately for the two sets. Using VTLN, the difference in WER is reduced to 0.7% absolute at  using MAPSSWE test.
using MAPSSWE test.
3.2. Jitter
Jitter is a measure of the cycle-to-cycle variation of the pitch period. Jitter is caused by instability in the vocal fold vibrations. It correlates with the hoarseness in voice. Increased jitter with age has been observed in both males and females [4, 34].
For our analysis, the following Jitter measurements as defined in Praat [28] were computed.
-
(i)
Jitter Local (Jit Loc) is the percentage ratio of average absolute distance between consecutive periods to the average period.
-
(ii)
Jitter Relative Average Perturbation (Jit RAP) is the ratio of average absolute difference between a period and the average of it and its two neighbours, to the average period.
Since the durations of the analysed segments of speech is small, jitter measures that are averaged over larger number of cycles have not been compared.
The variations of each of these jitter measurements are shown in Table 3. The changes are statistically significant at  using Mann-Whitney rank sum test.
using Mann-Whitney rank sum test.
In order to understand the effect of increased jitter on ASR performance, we artificially introduce jitter into the 400 test waveforms from 8 speakers.
Pulse positions representing the glottal closures are extracted from the speech utterances. Each pulse position  is then perturbed to get a new pulse position
is then perturbed to get a new pulse position  as follows
as follows

where  is a uniformly distributed random variable,
is a uniformly distributed random variable,  is a factor controlling the maximum perturbation allowed as a fraction of the average period
is a factor controlling the maximum perturbation allowed as a fraction of the average period  .
.
Using these new pulse positions, the waveform is resynthesized by pitch synchronous overlap and add method to get a waveform with increased jitter. Figure 3 shows an example of the waveforms before and after artificial increase in jitter.

Artificial increase in Jitter. (a) Waveform: OriginalWaveform: (b) Jitter Added
Maximum temporal perturbations of 5% ( ) and 10% (
) and 10% ( ) were introduced into the waveforms. Table 4 shows the ASR WERs on the original waveforms and the waveforms with increased jitter. With
) were introduced into the waveforms. Table 4 shows the ASR WERs on the original waveforms and the waveforms with increased jitter. With  , the waveforms sound very hoarse, yet the change in WER with increased jitter is statistically insignificant (using MAPSSWE test) and the ASR system performance is seen to be quite robust to jitter variations.
, the waveforms sound very hoarse, yet the change in WER with increased jitter is statistically insignificant (using MAPSSWE test) and the ASR system performance is seen to be quite robust to jitter variations.
3.3. Shimmer
Shimmer is a measure of variability of the peak-to-peak amplitude of the signal. This measure also correlates with hoarseness in voice. Shimmer has been found to have a strong correlation with age [29]. Amplitude perturbations have been reported to increase during old age in [4, 34, 35].
For our study, the following Shimmer measures were computed using Praat.
-
(i)
Shimmer Local (Shim Loc) is the percentage ratio of the average absolute difference between the amplitudes of consecutive periods to the average amplitude.
-
(ii)
Shimmer Three point Amplitude Perturbation Quotient (Shim APQ3) is the average absolute difference between the amplitude of a period and the average of the amplitudes of its neighbours, divided by the average amplitude.
Table 5 shows that the shimmer measures for older males are higher compared to the adult males and the results are statistically significant (with  using Mann-Whitney rank sum test).
using Mann-Whitney rank sum test).
We artificially introduce shimmer in the test waveforms to understand the effect of increased shimmer on ASR performance. Pulse positions representing glottal closures are extracted for each test waveform. From the location of the pulse positions, the voiced and unvoiced segments in speech are determined. To simulate shimmer effects, the speech samples  between two adjacent pulses in voiced segment are scaled to obtain
between two adjacent pulses in voiced segment are scaled to obtain  as follows
as follows

where  is a uniformly distributed random variable which is fixed for all the speech samples between two adjacent pulses, and
is a uniformly distributed random variable which is fixed for all the speech samples between two adjacent pulses, and  is a factor controlling the maximum perturbation allowed.
is a factor controlling the maximum perturbation allowed.
An example of the waveform before and after artificial introduction of shimmer is seen in Figure 4. (Examples of the original and modified waveforms can be accessed from http://homepages.inf.ed.ac.uk/s0680896/atypicalSpeech/) Table 6 shows that perturbations in amplitude between adjacent periods do not affect the ASR accuracies significantly.

Artificial increase in Shimmer. (a) Waveform: OriginalWaveform: (b) Shimmer Added
3.4. Harmonicity
Another voice quality associated with ageing is breathiness. Breathiness is thought to arise due to incomplete glottal closure during closed phase of the phonatory cycle. The nearly sinusoidal shape of the breathy glottal waveforms is responsible for the increase in the relative amplitude of the first harmonic [36]. Breathy signals tend to have more high frequency energy than normally phonated signal [37]. Breathy speech also tends to be less periodic, especially in the mid and high frequencies where aspiration noise is large [38].
Harmonic-to-Noise Ratio (HNR) measures the signal-to-noise ratio in a periodic waveform and acts as a good indicator of voice quality. It is computed as the ratio of the noise to the energy of the signal in the periodic part of the signal [39]. An increase in Noise-to-Harmonic Ratio (NHR) values in older voices has been reported in [29].
The results of the analysis of autocorrelation (Autocorr) and NHR in our experiments are tabulated in Table 7.
A measure that correlates well with breathiness in voice is Cepstral Peak Prominence (CPP) proposed by Hillenbrand and Houde [36]. The cepstrum is a Fourier analysis of the logarithmic amplitude spectrum of a signal. When the log amplitude of the spectrum contains regularly spaced harmonics, the Fourier analysis of the spectrum then captures the periodicity in the spectrum and will show a peak at a quefrency corresponding to the spacing between the harmonics. The cepstral peak reflects both the level of harmonic structure in the signal and the overall amplitude of the signal. To normalise for overall amplitude, a linear regression line is calculated relating quefrency to cepstral magnitude. The CPP measure is the difference in amplitude (in dB) between the cepstral peak and the value of the regression line at the cepstral peak (illustrated in Figure 5). CPP is computed on frames of 10 ms and averaged over all the frames in an utterance. CPP values for breathy voices are lower than those for normal voice since the cepstral peak is expected to be smaller in breathy voices due to loss of periodic structure in higher frequencies of the spectrum.

Illustration of Cepstral Peak Prominence.
A smoothed version of CPP called CPPS is computed similarly with some additional smoothing. For CPPS, a frame size of 2 ms is used instead of 10 ms and 2 levels of smoothing are applied. First the cepstrum is averaged across time by replacing an unsmoothed cepstrum at a time frame with the average of itself and the adjacent cepstral frames. A second level of smoothing is then applied by a running average of the cepstral magnitude across quefrency for each cepstral frame.
We computed CPP and CPPS for all the test utterances of adult and older speech and the average values are shown in Table 7 (The program cpps.exe available at http://homepages.wmich.edu/~hillenbr/ has been used for the computation of CPP and CPPS measures).
It is observed that the differences in the harmonicity measures of adult and older voices are statistically insignificant (by Mann Whitney rank sum test). Though the changes in CPP and CPPS measures are found to be statistically significant, the actual difference in the values is very small. CPPS, which has been reported [36] to be better correlated with perceived breathiness in voice than CPP, differs only by a value of 0.02 for the two age groups. This coupled with the comparative results of NHR suggests that the difference in breathiness chracteristics of adult and older test sets used in our experiments do not differ much.
4. Phoneme Acoustic Likelihoods and Phoneme Recognition Rates
From the results in Section 3, most of the changes in voice source parameters seem to have a negligible effect on the ASR performance. The changes in the articulation pattern during old age could be a strong factor that affects the ASR performance. It is hence of interest to see if ageing affects the recognition performance of certain phonemes more than others. Comparing the average log likelihood of each phoneme for adult and older speech is likely to give a good indication of the mismatch between the features.
In order to compare the likelihoods, all the test utterances (of adult and older male voices) as described in Section 2 were first force aligned to the triphone transcription. The left and right contextcs in the triphones were stripped and the average negative log likelihood per frame for the centre phoneme for each age group was computed.
Figure 6 shows that the likelihood scores for older voices are consistently lower than those of adult voices for all the phonemes. The difference is statistically significant at  for all phonemes except "oy" for which it is insignificant. We also observe that the variations in likelihood scores for each phoneme of older voices are higher than those for adult voices indicating a larger variability in the pronunciations of all phonemes.
for all phonemes except "oy" for which it is insignificant. We also observe that the variations in likelihood scores for each phoneme of older voices are higher than those for adult voices indicating a larger variability in the pronunciations of all phonemes.

Average phoneme negative log likelihood per frame.
These results indicate that there is a mismatch in the acoustic models (which are trained on speech dominated by adult voices) and feature space of older voices. These results are consistent with the findings in [13] where for an older test set, acoustic models trained on older voices resulted in about 3–5% absolute improvement in WER over acoustic models trained on younger adult speech. The mismatch in the acoustic space of younger and older people has also been exploited in speaker age group classification tasks [40, 41].
To get a picture of the ASR accuracies for individual phonemes for the two age groups, we trained monophone models, each phoneme modeled as a three-state HMM with 18 Gaussian components per state. A phone loop decoder was used to generate the phoneme sequence hypothesis for the test utterances of the two groups. Percentages of correct recognition for each phoneme is shown in Figure 7.

Phoneme recognition (% Correct).
We observe that the phonemes that are most affected are "aa", "ae", "ao", "aw", and "er" with over 10% drop in the recognition rates. These phonemes form the mid vowels where the tongue hump position is located in the central region of the mouth and the jaw is lowered relatively more than that for other phonemes. "hh" is a whisper sound which also has over 10% lower recognition rates for older voices. The nasals ("m", "n", "ng") have about 3–5% decrease in recognition rates. The phonemes in which the tongue forms a constriction near the upper teeth ("t", "th", "r", and "l") have a drop of around 4% in the recognition rates. The other phonemes that have a drop of around 5% are the affricate "jh" and the unvoiced fricative "f".
These results suggest that certain phonemes that are mainly dependent on the pronounced jaw movement and certain tongue movements (creating a constriction with middle of the tongue and the tongue tip) for clear articulation are the worst affected in terms of ASR accuracy.
5. Discussion
Many of the voice analysis measures reported in this article are somewhat higher than the published values in diagnostic medical research. This is due to the fact that we have not used sustained vowel pronunciations in clean recording conditions, but extracted sustained phones from spontaneous speech. Due to chunking, there is also a co-articulation effect at the beginning and the end of each analysed phone sample. However the same procedure has been applied to both adult and older voices in similar recording environments to analyse the differences between the two groups. Indeed our analysis is relevant in this context as it is made on natural speech which is the typical input to ASR systems.
Jitter and Shimmer measures have been extensively studied and have been used by researchers in age recognition from voice. From our experimental results too, we observe a clear increase in jitter and shimmer values for older voices. These measures can work well for the detection of older voices. In automatic speech recognition, the human speech production mechanism is seen as a source filter model, where vocal fold vibrations act as source forcing air out of the vocal tract channel to generate speech. Front end feature extraction techniques in ASR such as perceptual linear prediction used in our experiments are quite robust and suppress the variations in the source characteristics.
Language modeling plays a significant role in the performance of ASR systems and hence needs to be taken in account when comparing ASR performances. However due to the nature of the corpus (being court case arguments), linguistic characteristics do not vary much across speakers.
The results of the phoneme likelihood scores indicate that there is a mismatch in the acoustic space of adult and older voices. Training acoustic models for a particular age group are likely to improve the ASR accuracies for that group but are likely to degrade the performance for another age group. A suitable solution in such a scenario, where speakers from different age groups form the users of an ASR system, is to train gender and age group specific acoustic models and to allow the system to pick the acoustic model that maximises the likelihood score as the user speaks.
6. Conclusion
In this study we have performed experiments to understand the difference in ASR performance on adult and older voices. We then analysed several voice source parameters and found that the parameter values of fundamental frequency, jitter and shimmer measures show statistically significant differences in adult and older voices. Even though older voices show increased Jitter and Shimmer, these measures do not appear to effect the ASR performance significantly. Average phoneme likelihood scores indicate that older voices are not as well matched to the acoustic models as adult voices. This could possibly be overcome by the selection of training data targeted towards the domain of older speakers. Phoneme accuracy results also indicate that mid vowels, nasals, and phonemes requiring constriction with the tongue tip are more affected than other phonemes as a result of ageing.
References
Mahler DA, Rosiello RA, Loke J: The aging lung. Clinics in Geriatric Medicine 1986, 2(2):215-225.
Kahane J: Anatomic and physiologic changes in the aging peripheral speech mechanism. In Aging Communication Processes and Disorders. Grune & Stratton, New York, NY, USA; 1981:21-45.
Tolep K, Higgins N, Muza S, Criner G, Kelsen SG: Comparison of diaphragm strength between healthy adult elderly and young men. American Journal of Respiratory and Critical Care Medicine 1995, 152(2):677-682.
Linville V: Vocal Aging. Singular Thomson Learning, San Diego, Calif, USA; 2001.
Ramig LO, Gray S, Baker K, et al.: The aging voice: a review, treatment data and familial and genetic perspectives. Clinical Linguistics and Phonetics 2001, 53(5):252-265.
Paulsen FP, Tillmann BN: Degenerative changes in the human cricoarytenoid joint. Archives of Otolaryngology, Head & Neck Surgery 1998, 124(8):903-906.
Rodeno MT, Sánchez-Fernández JM, Rivera-Pomar JM: Histochemical and morphometrical ageing changes in human vocal cord muscles. Acta Oto-Laryngologica 1993, 113(3):445-449. 10.3109/00016489309135842
Hirano M, Kurita S, Sakaguchi S: Ageing of the vibratory tissue of human vocal folds. Acta Oto-Laryngologica 1989, 107(5-6):428-433. 10.3109/00016488909127535
Sato K, Hirano M: Age-related changes of elastic fibers in the superficial layer of the lamina propria of vocal folds. Annals of Otology, Rhinology and Laryngology 1997, 106(1):44-48.
Rother P, Wohlgemuth B, Wolff W, Rebentrost I: Morphometrically observable aging changes in the human tongue. Annals of Anatomy 2002, 184(2):159-164. 10.1016/S0940-9602(02)80011-5
Weinstein B: The biology of aging. In Geriatric Audiology. Georg Thieme, Stuttgart, Germany; 2000:15-40.
Xue SA, Hao GJ: Changes in the human vocal tract due to aging and the acoustic correlates of speech production: a pilot study. Journal of Speech, Language, and Hearing Research 2003, 46(3):689-701. 10.1044/1092-4388(2003/054)
Baba A, Yoshizawa S, Yamada M, Lee A, Shikano K: Acoustic models of the elderly for large-vocabulary continuous speech recognition. Electronics and Communications in Japan, Part II 2004, 87(7):49-57. 10.1002/ecjb.20101
Vipperla R, Renals S, Frankel J: Longitudinal study of ASR performance on ageing voices. Proceedings of the 9th Annual Conference of the International Speech Communication Association (INTERSPEECH '08), September 2008, Brisbane, Australia 2550-2553.
Wilpon JG, Jacobsen CN: A study of speech recognition for children and the elderly. Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP '96), 1996, Atlanta, Ga, USA 1: 349-352.
Möller S, Gödde F, Wolters M: Corpus analysis of spoken smarthome interactions with older users. Proceedings of the 6th International Language Resources and Evaluation (LREC '08), May 2008, Marrakech, Morocco
Wolters M, Georgila K, MacPherson S, Moore J: Being old doesn't mean acting old: older users' interaction with spoken dialogue systems. ACM Transactions on Accessible Computing 2009, 2(1):1-39.
Vipperla R, Wolters M, Georgila K, Renals S: Speech input from older users in smart environments: challenges and perspectives. In Proceedings of the 5th International Conference on Universal Access in Human-Computer Interaction (UAHCI '09), 2009, San Diego, Calif, USA, Lecture Notes in Computer Science. Volume 5615. Springer; 117-126.
Yuan J, Liberman M: Speaker identification on the SCOTUS corpus. Proceedings of Acoustics, 2008 5687-5690.
Hain T, Burget L, Dines J, et al.: The 2005 AMI system for the transcription of speech in meetings. Proceedings of the Rich Transcription (RT '05), 2005, Lecture Notes in Computer Science 3869:
Rabiner LR: Tutorial on hidden Markov models and selected applications in speech recognition. Proceedings of the IEEE 1989, 77(2):257-286. 10.1109/5.18626
Jurafsky D, Martin JH: Speech and Language processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition. 2nd edition. Prentice Hall, Upper Saddle River, NJ, USA; 2008.
Taylor P, Black AW, Caley R: The architecture of the Festival speech synthesis system. Proceedings of the 3rd ESCA Workshop on Speech Synthesis, 1998 147-151.
Mann H, Whitney D: On a test whether one of two random variables is stochastically larger than the other. The Annals of Mathematical Statistics 1947, 18: 50-60. 10.1214/aoms/1177730491
Gales M, Young S: The application of hidden Markov models in speech recognition. Foundations and Trends in Signal Processing 2007, 1(3):195-304. 10.1561/2000000004
Leggetter CJ, Woodland PC: Maximum likelihood linear regression for speaker adaptation of continuous density hidden Markov models. Computer Speech and Language 1995, 9(2):171-185. 10.1006/csla.1995.0010
Garau G, Renals S, Hain T: Applying vocal tract length normalization to meeting recordings. Proceedings of the 9th European Conference on Speech Communication and Technology (INTERSPEECH '05), 2005 265-268.
Boersma P, Weenink D: Praat: doing phonetics by computer (Version 5.0.36) [Computer program]. October 2008, http://www.praat.org/
Xue SA, Deliyski D: Effects of aging on selected acoustic voice parameters: preliminary normative data and educational implications. Educational Gerontology 2001, 27(2):159-168. 10.1080/03601270151075561
Endres W, Bambach W, Flösser G: Voice spectrograms as a function of age, voice disguise, and voice imitation. Journal of the Acoustical Society of America 1971, 49(6):1842-1848. 10.1121/1.1912589
Schötz S, Müller C: A study of acoustic correlates of speaker age. In Speaker Classification II. Springer, Berlin, Germany; 2007:1-9.
Moulines E, Charpentier F: Pitch-synchronous waveform processing techniques for text-to-speech synthesis using diphones. Speech Communication 1990, 9(5-6):453-467. 10.1016/0167-6393(90)90021-Z
Gillick L, Cox SJ: Some statistical issues in the comparison of speech recognition algorithms. Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP '89), May 1989 1: 532-535.
Ramig LA, Ringel RL: Effects of physiological aging on selected acoustic characteristics of voice. Journal of Speech and Hearing Research 1983, 26(1):22-30.
Bruckl M, Sendlmeier W: Aging female voices: an acoustic and perceptive analysis. Proceedings of ISCA Tutorial and Research Workshop on Voice Quaility Functions, Analysis and Synthesis (VOQUAL '03), 2003, Geneva, Switzerland 163-168.
Hillenbrand J, Houde RA: Acoustic correlates of breathy vocal quality: dysphonic voices and continuous speech. Journal of Speech, Language, and Hearing Research 1996, 39(2):311-321.
Klich RJ: Relationships of vowel characteristics to listener ratings of breathiness. Journal of Speech and Hearing Research 1982, 25(4):574-580.
Hillenbrand J, Cleveland RA, Erickson RL: Acoustic correlates of breathy vocal quality. Journal of Speech and Hearing Research 1994, 37(4):769-778.
Boersma P: Accurate short-term analysis of the fundamental frequency and the harmonics-to-noise ratio of a sampled sound. Proceedings of the Institute of Phonetic Sciences 1993, 97-110.
Müller C, Burkhardt F: Combining short-term cepstral and longterm prosodic features for automatic recognition of speaker age. Proceedings of the 8th Annual Conference of the International Speech Communication Association (INTERSPEECH '07), 2007 2277-2280.
Wolters M, Vipperla R, Renals S: Age recognition for spoken dialogue systems: do we need it? Proceedings of the 10th Annual Conference of the International Speech Communication Association (INTERSPEECH '09), 2009 1435-1438.
Acknowledgments
This research was funded by SFC SRDG grant—HR04016: MATCH (Mobilising Advanced Technologies for Care at Home). This work has made use of the resources provided by Edinburgh Compute and Data Facility (ECDF) (http://www.ecdf.ed.ac.uk/). The ECDF is partially supported by the eDIKT initiative (http://www.edikt.org.uk/). The authors would like to thank Dr. Maria Wolters for reviewing the article and providing suggestions for improvement.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Vipperla, R., Renals, S. & Frankel, J. Ageing Voices: The Effect of Changes in Voice Parameters on ASR Performance. J AUDIO SPEECH MUSIC PROC. 2010, 525783 (2010). https://doi.org/10.1155/2010/525783
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1155/2010/525783