- Research
- Open access
- Published:
Speaker-dependent model interpolation for statistical emotional speech synthesis
EURASIP Journal on Audio, Speech, and Music Processing volume 2012, Article number: 21 (2012)
Abstract
In this article, we propose a speaker-dependent model interpolation method for statistical emotional speech synthesis. The basic idea is to combine the neutral model set of the target speaker and an emotional model set selected from a pool of speakers. For model selection and interpolation weight determination, we propose to use a novel monophone-based Mahalanobis distance, which is a proper distance measure between two Hidden Markov Model sets. We design Latin-square evaluation to reduce the systematic bias in the subjective listening tests. The proposed interpolation method achieves sound performance on the emotional expressiveness, the naturalness, and the target speaker similarity. Moreover, such performance is achieved without the need to collect the emotional speech of the target speaker, saving the cost of data collection and labeling.
Introduction
Statistical speech synthesis (SSS) is a fast-growing research area for text-to-speech (TTS) systems. While a state-of-the-art concatenative method [1, 2] for TTS is capable of synthesizing natural and smooth speech for a specific voice, an SSS-based approach [3, 4] has the strength to produce a diverse spectrum of voices without requiring significant amount of new data. This is an important feature for building next-generation applications such as a story-telling robot capable of synthesizing the speech of multiple characters with different emotions, personalized speech synthesis such as in speechto-speech translation [5, 6], and clinical applications such as voice reconstruction of patients with speech disorders [7]. In this article, we study the problem of generating new models of SSS from existing models. The model parameters of SSS can be systematically modified to express different emotions. Many instances of this problem have been investigated in the literature. In [8], the prosody is mapped from neutral to emotional using Gaussian mixture models and classification and regression trees. In [9], the spectrum and duration are converted in a voice conversion system with duration-embedded hidden Markov models (HMMs). In [10, 11], style-dependent and style-mixed modeling methods for emotional expressiveness are investigated. In [12], adaptation methods are used to transform the neutral model to the target model, requiring only small amounts of adaptation data. In [13–15], simultaneous adaptation of speaker and style is applied to an average voice model of multiple-regression HMMs to synthesize speaker-dependent styled speech. A few methods without the requirement of target speaker’s emotional speech have been studied. In [16], neutral speech are adapted based on analysis of emotional speech from the prosodic point of view. In [17, 18], speech with emotions or mixed styles are generated by interpolating styled speech models trained independently. In [19], prosodic parameters including pitch, duration, and strength factors are adjusted to generate emotional speech from neutral voice.
The method that we propose for emotional SSS models is called the speaker-dependent model interpolation. By being speaker-dependent, we mean that the interpolating model sets and weights are dependent on the speaker identity. By model interpolation, we mean that the target synthesis model set is a convex combination of multiple synthesis model sets. One major difference between our approach and the previous approaches for emotional expressiveness is that the emotional speech directly from the target speaker is not required by our design. This feature is particularly attractive when the collection of target emotional speech is difficult or even infeasible.
This article is organized as follows. First, we introduce our HMM-based speech synthesis system in Section “HMM-based speech synthesis”. The proposed method for emotional expressiveness based on speaker-dependent model interpolation is described in Section “Interpolation methods”. The evaluation methods and the results of the proposed approach are presented in Section “Experiments”. Lastly, the concluding remarks are given in Section “Conclusion and future work”.
HMM-based speech synthesis
An HMM-based speech synthesis system (also known as HTS) models speech units as HMMs [20]. An HTS system uses parameters of the multi-stream HMMs structure which combine the spectrum and excitation to generate the speech feature sequence, and uses a vocoder to convert the feature sequence to speech waveforms [21]. The parameters of the HMMs are learned in the training stage with labeled speech data via expectation-maximization algorithm [22, 23], as is well known and commonly used in machine learning and automatic speech recognition.
The block diagram of an HTS system is shown in Figure 1. The spectral features are modeled by HMM with a single Gaussian per state, while the excitation features are modeled by the multi-space probability distribution HMM (MSD-HMM) [24] to deal with the off-and-on property of periodic excitation. The duration of an HMM state is modeled by a Gaussian random variable, whose parameters are estimated by the state occupancies estimated on the training data. In the synthesis phase, given the input text, the corresponding state sequence is decided by maximizing the overall duration probability. With the state sequence, the static spectral and excitation features are determined by maximizing the joint data-likelihood of the combined static and dynamic feature streams. Finally, a synthesis filter is used to synthesize the speech samples.

The block diagram of a general HMM-based speech synthesis system. In the training phase we train the parameters in the HMMs given a labeled speech data set. In the synthesis phase, we use the model parameters to generate speech given text.
Our system is based on HTS version 2.1. We use the mel-generalized cepstral coefficients [25] (α=0.42,γ=0) as the spectral features, and use the logarithm of the fundamental frequency (log F0) as the excitation feature. The hts_engine API version 1.02 is used to synthesize speech waveforms from trained HMMs via a mel-generalized log-spectral approximation filter [26].
An HTS system for continuous Mandarin speech synthesis is constructed for this research. In this system, the basic HMM units are the tonal phone models (TPMs) [27]. The TPMs are based on the well-known initial/final models. In order to model the tones in Mandarin, we include two or three variants of tonal-final models based on the pitch positions (High, Medium, Low). In order to model the transition of pitch position during a syllable final, we concatenate an initial model and two tonal-final models for a tonal syllable. In total, there are 53 initial models and 52 tonal-final models. Thus, there are 105 “monophones” in our acoustic model. The initial models and the tonal-final models are listed in Table 1. The context-dependent phones (called the full-context phones) are based on these monophones. The question set for training the decision trees for state-tying consists of questions on the tonal context, the phonetic context, the syllabic context, the word context, the phrasal context, and the utterance context [28].
 (wonderful)
(wonderful)
Interpolation methods
Background
In this article, the target model seta for SSS is obtained through interpolation. Model interpolation offers two distinctive advantages. First, the data collection cost is reduced compared to retraining or model adaptation. Second, the properties of the synthesized speech can be refined by incrementally adjusting the interpolation ratios. These features are analyzed in the following sections.
Data collection costs
Suppose we need to synthesize the voices of S different speakers, and each speaker has E non-neutral emotions. Let the data required for training an SSS model set be D t , and for adapting a model set be D a , where we often have D a <D t . To synthesize all emotional voices of all speakers, retraining (training each model set from scratch) requires collecting and labeling a dataset of the size of
model adaptation requires the amount of
and our interpolation-based approach requires the amount of
where L is the number of model sets in the pool for each emotion (cf. Section “Speaker-dependent model interpolation”). The difference among (1), (2), and (3) is the marginal amount of data required per new speaker. For comparison, Equation (1) requires the amount of D t + E×D t to train a neutral model set and E different emotional model sets, Equation (2) requires the amount of D t + E×D a to train a neutral model set for the new speaker and then adapt for E different emotions, while Equation (3) requires only the amount of D t to train a new neutral model set. Clearly, the unpleasant efforts of data collection and labeling are significantly reduced with the proposed interpolation approach.
Applications
Model interpolation has been applied to continuously display a full spectrum of specific attributes for the synthesized speech, such as gender [29], style [17], and accent [30]. In this article, we study three emotional attributes including angry, happy, and sad.
HMM interpolation
Given model sets M1,…,M K , where K is the number of available model sets, a model set can be created by interpolation as follows. Let μ k (i) be the mean vector of state i in M k , Σ k (i) be the covariance matrix, and a k (i) be the interpolation weights of M k for state i. Then, the interpolated model is
where and are the mean and covariance of state i of .
There are a few methods to decide the interpolation weights a k (i)’s in (4). In [29], they are tied across states and then be decided by minimizing the weighted sum of the Kullback–Leibler distance. In [17], a k (i) is assumed to be proportional to γ k (i), the occupancy counts of state i in M k (with respect to a training set)
The block diagram of model interpolation is shown in Figure 2.

The block diagram of the procedure for model interpolation. Note that the interpolation is carried out with the model parameters.
Monophone-based Mahalanobis distance measure
In our approach, we need a distance measure to find the closest model set and the interpolation weight. Since two context-dependent phone model sets generally have different state-tying structures (decision trees), we propose a measure based on the context-independent models. It is called the monophone-based Mahalanobis distance (MBMD) defined by
In (6), α and β are HMM model sets, Z is the set of monophone HMM states, and μ α (i) and Σ α (i) are the mean vector and the covariance matrix of the Gaussian of state i in model set α (similarly for β).
Note that (6) defines a proper distance measure, since
Furthermore, the difference in the temporal structures of model sets α,β is not ignored in our method. That is, we include the Mahalanobis distance between the Gaussians modeling the duration of HMM states in (6). Thus, the difference in the state transition distributions of two model sets is taken into account.
Speaker-dependent model interpolation
We can now describe the proposed speaker-dependent model interpolation for SSS. Let the number of pool speakers be L. Let ϕ1,…,ϕ L denote the neutral model sets, and ψ1,…,ψ L denote the emotional model sets. These model sets are trained by HTS. Note that as mentioned in Section “HMM-based speech synthesis”, certain features of HTS have to be customized for Mandarin, such as the phone set and the question set for full-context phone models. Given a target speaker with neutral model set , an emotional model set for is created by interpolation with the following proposed Method of Model Interpolation.
Method of model interpolation
-
Find the speaker whose neutral model set is closest to ,
(8) -
Find the emotional model set closest to ,
(9) -
Find the interpolation weight r∗ which results in the model set closest to ψl∗,
(10)Note is the monophone model set interpolation by and M2=ψ∗with weights
(11)The interpolation weight is found by a grid search. That is, r is varied from 0 to 1 with increment 0.1 to find r∗.
-
Given a text, the speech is synthesized by interpolating the parameters computed by ψ∗ and with weights r∗and 1−r∗. This is denoted by
(12)
The basic idea behind using ψl∗as the target in determining the interpolation weight (10) is that similar neutral speech implies similar emotional speech. The motivation of making interpolation between ϕ T and ψ∗is twofold. First, if ψl∗were used directly to represent ψ T , the target speaker identity would have been lost. Therefore, we interpolate the target speaker’s speech model ϕ T . Secondly, to achieve better speech quality, we find an emotional model ψ∗that is closest to the target speaker’s model to interpolate, reducing potential artifacts resulting from interpolating different models. The block diagram of the proposed Method of Model Interpolation is shown in Figure 3. The interpolation scheme is applied separately to the spectrum, the excitation, and the duration models. We note that
-
The interpolation ratio (12) used for the context-dependent models is estimated via MBMD (10), which is based on context-independent models. This approximation works for our system.
Figure 3 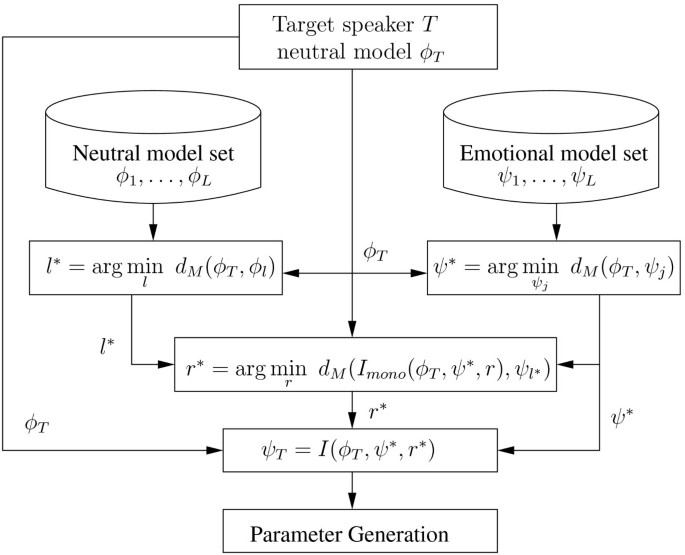
The block diagram of the proposed scheme for model interpolation. The interpolation is speaker-dependent.
-
For a given target speaker, if ψ∗=ψl∗, the optimal weight r∗in (10) would be 0, and we would have . That is, the model set of the target speaker would not have contributed to the synthesized voice. In our system, if the closest neutral model set and the closest emotional model set are from the same pool speaker, the system simply uses the second closest emotional model set.

Experiments
Speech data collection
We collect the speech of five pool speakers, including four male speakers and one female speaker. The speech samples of three emotions from each pool speaker, angry, happy, and sad, are collected, as well as the neutral (non-emotional) speech samples. There are three disjoint sets of sentences corresponding to the three different emotions. Each set consists of 300 sentences which are phonetically balanced by design. The set of neutral prompts is a subset of the union of the three disjoint sets. As a result, each pool speaker contributes 900 emotional utterances and 300 neutral utterances. The neutral model set of a pool speaker is trained by 300 neutral utterances, and each emotional model set is also trained by 300 emotional utterances. These model sets constitute the pools for L=5 speakers and E=3 emotions (cf. Section “Speaker-dependent model interpolation”). The MBMDs between the neutral models of the pool speakers are summarized in Table 2. It summarizes the distance (similarity) between pairs of neutral models of the pool speakers. Note that to achieve good speaker-independent interpolation performance, the set of pool speakers should be representative of the voice space, so the voices in the pool are better to be diverse.
In addition to the pool speakers, we also collect the speech of five target speakers, including one female speaker and four male speakers, for the evaluation of the proposed approach. The neutral speech samples of 300 utterances from each target speaker are collected and used to train the neutral speech model set of that target speaker. The MBMDs between the neutral models of the pool speakers and neutral models of the target speakers are summarized in Table 3. It is used to decide l∗ in Equation (8), as shown in boldface in the table.
Evaluation on emotional expressiveness
For the emotional expressiveness, we evaluate whether the synthesized speech conveys the target emotion by subjective listening tests. In one selection, a listener listens to five waveforms (from five different target speakers in five different emotions in randomized pairs), and chooses the speech with the nominated emotion (1-out-of-5 choice of emotion identification). We note that this setting is significantly harder than a binary choice between a synthesized neutral speech and a synthesized emotional speech, which could lead to a systematic bias toward the emotional speech to be selected.
The pairing of the target speaker and the emotion are randomized via a Graeco-Latin square commonly used in evaluation [31], as shown in Figure 4, for each emotion. With five listener groups and five utterance sets, each column of the 5×5 Graeco-Latin square corresponds to an utterance set and each row corresponds to a listener group. The entity in the intersection of row i and column j, denoted by (s ij e ij ), means that a listener in group i listens to utterance set j synthesized via the model set of target speaker s ij for the emotion e ij . We make sure that

The 5 × 5 Graeco-Latin square used in the evaluation of emotional expressiveness of the synthesized speech.
and
In reality, we only have four model sets per target speaker, angry, happy, sad, and neutral. To complete the Graeco-Latin square, we add the non-synthetic flavor. The score of this flavor provides us with a performance reference.
The test results are summarized in Table 4. For the reference case of the non-synthetic flavor, the correct answer is almost always chosen (40/45). However, in five cases the synthesized speech are chosen as non-synthetic, meaning that they sound more natural than the natural (non-synthetic) speech! For the synthesized emotional speech, we can see that the proposed method works remarkably well for sad and reasonably well for the neutral, given that the choice is 1-out-of-5. The happy and angry appears to form a confusable set, which can be attributed to the similar patterns in their respective excitation (pitch) models and duration (speaking rate) models.
To decide if the results are statistically significant, we conduct the following test of significance. For the results of the angry case, the p-value is
where n c is the number of correctly answered questions, μ is the mean under the null hypothesis of random guess, n is the number of tested questions, σ is the variance of a Bernoulli random variable, and Φ(x) is the cumulative distribution function of a standard normal random variable . For other emotions (happy and sad), the p-values of the test statistics are even smaller than p m . Therefore, the results in Table 4 are statistically significant.
Evaluation on naturalness
We use an MOS-based method for the evaluation on the naturalness of the synthesized speech. Basically, a listener listens to an utterance and rate the quality between 1 and 5 with the following scale: 5 for excellent, 4 for good, 3 for fair, 2 for poor, and 1 for bad. Note that the emotion of the speech is revealed to the listener, so a synthesized speech needs to be both natural and emotionally expressive to score high.
A Latin square as shown in Figure 5 is used in this evaluation. For each emotion, a listener listens to five synthesized speeches, each from a different target speaker and with a different prompt (text). In addition, a listener also rates a non-synthetic utterance. This non-synthetic utterance is randomly inserted during a test session. These non-synthetic utterances serve the purpose of calibrating the MOS scale to avoid MOS scores that are systematically biased upwards.

The 5 × 5 Latin square used in the evaluation of naturalness of the synthesized speech.
The test results are summarized in Table 5. Note that the score is based on the average of 75=5×3×5 MOS scores per emotion, as there are five listener groups, three listeners per group, and five synthesized speeches per listener. On average, the synthesized speech achieves fair on angry and happy, slightly worse than fair for sad (2.9). Given that non-synthetic speech only achieves 4.6, the performance of the emotional synthesized speech is arguably acceptable.
Evaluation on similarity
The evaluation on the similarity is based on to what degree the synthesized emotional speech conveys the identity to the target speaker. The method of ABX test, where X is the synthesized emotional speech, A is a neutral non-synthetic speech from the target speaker, and B is a neutral non-synthetic speech from the pool speaker used in the interpolation (12), is used in this evaluation. Basically, a listener is asked to decide whether X sounds like the speaker of A or the speaker of B, without knowing the emotion label. For a fair comparison, the order of A and B for any given X is randomized, so there is no systematic bias towards the first choice or the second choice.
The test results are summarized in Table 6. They are based on 150=15×10 test samples as there are 15 listeners and each listener makes 10 choices. In all emotions, the correct choice is made by the test subjects in the majority of cases, with 73% for happy, 60% for angry, and 55% for sad. The overall accuracy is 62%. Therefore, the synthesized speech, even with emotions, still conveys the identity of the target speaker.
We use the Chi-squared test for testing statistical significance. The χ2-value is
Therefore, the null hypothesis is rejected at the 0.01 significance level. Therefore, the synthesized speech does convey the speaker identity information. Alternatively, the same conclusion can be drawn by computing the p-value via the central-limit theorem, which yields
Comparison with the adaptation method
In this section, the proposed model interpolation method is compared to the model adaptation method. For fair comparison, the same amount of speech data used in interpolation-based system is used in adaptation-based system. For each emotion, 1,500 emotional utterances from 5 pool speakers are used to train an average-voice emotional model. For a target speaker, 300 neutral utterances are used to adapt the average-voice emotional model. Fifteen test subjects participate in each of the following sets of evaluation. The results are summarized as follows.
-
Expressiveness
In the evaluation of emotional expressiveness, a test subject is asked to listen to two synthesized speech and indicate the one with better expressiveness. One speech is synthesized by the interpolation system, while the other is synthesized by the adaptation system. The order of the synthesized speech is randomized. For each emotion, a test subject listens to three pairs. The results are summarized in Table 7. In 70% (94 out of 135) of the tests, the interpolation-based synthesized speech is chosen. Thus, interpolation outperforms adaptation in emotional expressiveness. The p-value for the null hypothesis of random guess based on evaluation results in Table 7 is
(18)where Φ X (x) is the cumulative distribution function of a standard normal random variable . Therefore, the null hypothesis is rejected and the difference in performance is statistically significant. Note that in the case of happy emotion, over 90% (41 out of 45) cases the interpolation-based synthesized speech is chosen.
Table 7 Results of comparison between interpolation and adaptation regarding emotional expressiveness -
Similarity
For the comparison of interpolation and adaptation, we adopt the ABX scheme, where X is the target speaker’s non-synthetic speech, A is the synthetic emotional speech using adaptation, and B is the synthetic emotional speech using interpolation. Again, the order of A, B is randomized. The results are summarized in Table 8. Contrary to the emotional expressiveness, adaptation outperforms interpolation in 64% of the tests. The p-value for the null hypothesis of random guess based on evaluation results in Table 8 is
(19)Therefore, the performance of adaptation is significantly better than interpolation regarding similarity.
Table 8 Results of comparison between interpolation and adaptation regarding similarity -
Naturalness
The same Latin-square style MOS evaluation on naturalness as described in Section “Evaluation on naturalness” is used with synthesized speech by the adaptation-based system. The results are shown in Table 9. Comparing Table 5 with Table 9, we can see that interpolation-based system is slightly better. Furthermore, the “reference level” of non-synthetic speech is higher (by 0.3) in Table 9, which means that the difference between non-synthetic (natural) speech and synthesized speech is smaller with interpolation.
Table 9 Results for the evaluation of the naturalness of synthesized speech using model adaptation
In summary, interpolation outperforms adaptation regarding emotional expressiveness, underperforms adaptation regarding similarity, and is slightly better than adaptation regarding naturalness. Note that the adaptation method is computationally more expensive than the interpolation method due to the training of average voice models.
Conclusion and future work
In this article, we propose and implement a speaker-dependent model interpolation method for HMM-based emotional speech synthesis. We use a novel MBMD measure to decide the interpolation model sets and weights. Comprehensive evaluation with subjective listening tests randomized by the Latin and Graeco-Latin squares to avoid systematic biases are carried out. The proposed model interpolation method has an intrinsic tradeoff between emotional expressiveness and similarity. Therefore, it is quite difficult to achieve both goals within the framework of interpolation. This can be seen as a drawback resulting from not using any emotional speech of the target speaker. Experiment results show that our method strikes a good balance between the emotional expressiveness, the naturalness, and the speaker identity. Additionally, our method does not require the emotional speech of new speakers, and can save enormous data collection and labeling costs. In the future, it will be interesting to compare the synthesized emotional speech with the non-synthetic emotional speech, with data collected from the target speaker, to further improve the performance.
Endnote
aNote that a model set refers to the entire set of HMMs for a given voice, while a model refers to only one basic linguistic unit such as a phone or a word, in this article.
References
Hunt AJ, Black AW: Unit selection in a concatenative speech synthesis system using a large speech database. Proceedings of International Conference on Acoustics, Speech and Signal Processing, 1996, pp. 373–376
Gros JZ, Zganec M: An efficient unit-selection method for concatenative text-to-speech synthesis systems. J. Comput. Inf. Technol 2008, 16: 69-78.
Yoshimura T, Tokuda K, Masuko T, Kobayashi T, Kitamura T: Simultaneous modeling of spectrum, pitch and duration in HMM-based speech synthesis. Proceedings of Eurospeech, 1999, pp. 2347–2350
Zen H, Tokuda K, Black AW: Statistical parametric speech synthesis. Proceedings of International Conference on Acoustics, Speech and Signal Processing, 2007, pp. 1229–1232
Kurimo M, Byrne W, Dines J, Garner PN, Gibson M, Guan Y, Hirsimäki T, Karhila R, King S, Liang H, Oura K, Saheer L, Shannon M, Shiota S, Tian J, Tokuda K, Wester M, Wu YJ, Yamagishi J: Personalising speech-to-speech translation in the EMIME project. Proceedings of the ACL 2010 System Demonstrations, Uppsala, Sweden, 2010
Wester M, Dines J, Gibson M, Liang H, Wu YJ, Saheer L, King S, Oura K, Garner PN, Byrne W, Guan Y, Hirsimäki T, Karhila R, Shannon M, Shiota S, Tian J, Tokuda K, Yamagishi J: Speaker adaptation and the evaluation of speaker similarity in the EMIME speech-to-speech translation project. Proceedings of 7th ISCA Speech Synthesis Workshop, Kyoto, Japan, 2010
Creer S, Green P, Cunningham S, Yamagishi J: Building personalised synthesised voices for individuals with dysarthria using the HTS toolkit. Computer Synthesized Speech Technologies: Tools for Aiding Impairment, January 2010
Tao J, Kang Y, Li A: Prosody conversion from neutral speech to emotional speech. IEEE Trans. Audio Speech Lang. Process 2006, 14(4):1145-1154.
Wu CH, Hsia CC, Liu TH, Wang JF: Voice conversion using duration-embedded bi-HMMs for expressive speech synthesis. IEEE Trans. Audio Speech Lang. Process 2006, 14(4):1109-1116.
Yamagishi J, Onishi K, Masuko T, Kobayashi T: Modeling of various speaking styles and emotions for HMM-based speech synthesis. Proceedings of Eurospeech, 2003, pp. 2461–2464
Yamagishi J, Onishi K, Masuko T, Kobayashi T: Acoustic modeling of speaking styles and emotional expressions in HMM-based speech synthesis. IEICE Trans. Inf. Syst 2005, E88-D(3):502-509. 10.1093/ietisy/e88-d.3.502
Yamagishi J, Kobayashi T, Nakano Y, Ogata K, Isogai J: Analysis of speaker adaptation algorithms for HMM-based speech synthesis and a constrained SMAPLR adaptation algorithm. IEEE Trans. Audio Speech Lang. Process 2009, 17: 66-83.
Nose T, Yamagishi J, Masuko T, Kobayashi T: A style control technique for HMM-based expressive speech synthesis. IEICE Trans. Inf. Syst 2007, E90-D(9):1406-1413. 10.1093/ietisy/e90-d.9.1406
Tachibana M, Izawa S, Nose T, Kobayashi T: Speaker and style adaptation using average voice model for style control in HMM-based speech synthesis. ICASSP ’08, 2008, pp. 4633–4636
Nose T, Tachibana M, Kobayashi T: HMM-based style control for expressive speech synthesis with arbitrary speaker’s voice using model adaptation. IEICE Trans. Inf. Syst 2009, E92-D(3):489-497. 10.1587/transinf.E92.D.489
Jiang DN, Zhang W, Shen LQ, Cai LH: Prosody analysis and modeling for emotional speech synthesis. Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing 2005 (ICASSP ’05), 2005, pp. 281–284
Tachibana M, Yamagishi J, Masuko T, Kobayashi T: Speech synthesis with various emotional expressions and speaking styles by style interpolation and morphing. IEICE Trans. Inf. Syst 2005, E88-D(11):2484-2491. 10.1093/ietisy/e88-d.11.2484
Yoshimura T, Masuko T, Tokuda K, Kobayashi T, Kitamura T: Speaker interpolation in HMM-based speech synthesis system. Fifth European Conference on Speech Communication and Technology, EUROSPEECH 1997, Rhodes, Greece, September 22–25, 1997
Govind D, Prasanna SRM, Yegnanarayana B: Neutral to target emotion conversion using source and suprasegmental information. INTERSPEECH, ISCA, 2011, pp. 2969–2972
Rabiner LR: A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE 1989, 77(2):257-286. 10.1109/5.18626
Tokuda T, Masuko T, Miyazaki N, Kobayashi T: Multi-space probability distribution HMM. IEICE Trans. Inf. Syst 2002, E85-D(3):455-464.
Dempster AP, Laird NM, Rubin DB: Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B 1977, 39: 1-38.
Bilmes JA: A gentle tutorial of the EM algorithm and its application to parameter estimation for gaussian mixture and hidden Markov models. Technical report, International Computer Science Institute, University of California at Berkeley TR-97-021, April 1998
Tokuda K, Masuko T, Miyazaki N, Kobayashi T: Hidden Markov models based on multi-space probability distribution for pitch pattern modeling. Proceedings of International Conference on Acoustics, Speech and Signal Processing, 1999, pp. 229–232
Tokuda K, Kobayashi T, Masuko T, Imai S: Mel-generalized cepstral analysis. Proceedings of International Conference on Spoken Language Processing, 1994, pp. 1043–1046
Kobayashi T, Imai S, Fukuda T: Mel-generalized log spectral approximation filter. IEICE Trans. Fund 1985, J68-A(6):610-611.
Huang C, Shi Y, Zhou J, Chu M, Wang T, Chang E: Segmental tonal modeling for phone set design in, Mandarin LVCSR. Proceedings of International Conference on Acoustics, Speech and Signal Processing, 2004, pp. 901–904
Zen H: An Example of Context-dependent label format for HMM-based Speech synthesis in English. 2006.https://wiki.inf.ed.ac.uk/twiki/pub/CSTR/F0parametrisation/hts_lab_format.pdf
Yoshimura T, Tokuda K, Masuko T, Kobayashi T, Kitamura T: Speaker interpolation for HMM-based speech synthesis system. J. Acoust. Soc. Jpn 2000, 21(4):199-206. 10.1250/ast.21.199
Pucher M, Schabus D, Yamagishi J, Neubarth F, Strom V: Modeling and interpolation of Austrian German and Viennese dialect in HMM-based speech synthesis. Speech Commun 2010, 52(2):164-179. 10.1016/j.specom.2009.09.004
Fraser M, King S: The Blizzard challenge 2007. Proceedings of the Sixth ISCA Workshop on Speech Synthesis (SSW6), 2007.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Hsu, CY., Chen, CP. Speaker-dependent model interpolation for statistical emotional speech synthesis. J AUDIO SPEECH MUSIC PROC. 2012, 21 (2012). https://doi.org/10.1186/1687-4722-2012-21
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1687-4722-2012-21