- Research
- Open access
- Published:
Phoneme and Sentence-Level Ensembles for Speech Recognition
EURASIP Journal on Audio, Speech, and Music Processing volume 2011, Article number: 426792 (2011)
Abstract
We address the question of whether and how boosting and bagging can be used for speech recognition. In order to do this, we compare two different boosting schemes, one at the phoneme level and one at the utterance level, with a phoneme-level bagging scheme. We control for many parameters and other choices, such as the state inference scheme used. In an unbiased experiment, we clearly show that the gain of boosting methods compared to a single hidden Markov model is in all cases only marginal, while bagging significantly outperforms all other methods. We thus conclude that bagging methods, which have so far been overlooked in favour of boosting, should be examined more closely as a potentially useful ensemble learning technique for speech recognition.
1. Introduction
This paper examines the application of ensemble methods to hidden Markov models (HMMs) for speech recognition. We consider two methods: bagging and boosting. Both methods feature a fixed mixing distribution between the ensemble components, which simplifies the inference, though it does not completely trivialise it.
This paper follows up on and consolidates previous results [1–3] that focused on boosting. The main contributions are the following. Firstly, we use an unbiased model testing methodology to perform the experimental comparison between the various different approaches. A larger number of experiments, with additional experiments on triphones, shed some further light on previous results [2, 3]. Secondly, the results indicate that, in an unbiased comparison, at least for the dataset and features considered, bagging approaches enjoy a significant advantage to boosting approaches. More specifically, bagging consistently exhibited a significantly better performance than either any of the boosting approaches examined. Furthermore, we were able to obtain state-of-the art results on this dataset using a simple bagging estimator on triphone models. This indicates that perhaps a shift towards bagging and perhaps, more generally, empirical Bayes methods may be advantageous for any further advances in speech recognition.
Section 2 introduces notation and provides some background to speech recognition using hidden Markov models. In addition, it discusses multistream methods for combining multiple hidden Markov models to perform speech recognition. Finally, it introduces the ensemble methods used in the paper, bagging and boosting, in their basic form.
Section 3 discusses related work and their relation to our contributions, while Section 4 gives details about the data and the experimental protocols followed.
In the speech model considered, words are hidden Markov models composed of concatenations of phonetic hidden Markov models. In this setting it is possible to employ mixture models at any temporal level. Section 5 considers mixtures at the phoneme model level, where data with a phonetic segmentation is available. We can then restrict ourselves to a sequence classification problem in order to train a mixture model. Application of methods such as bagging and boosting to the phoneme classification task is then possible. However, using the resulting models for continuous speech recognition poses some difficulties in terms of complexity. Section 5.1 outlines how multistream decoding can be used to perform approximate inference in the resulting mixture model.
Section 6 discusses an algorithm, introduced in [3], for word error rate minimisation using boosting techniques. While it appears trivial to do so by minimising some form of loss based on the word error rate, in practice successful application additionally requires use of a probabilistic model for inferring error probabilities in parts of misclassified sequences. The concepts of expected label and expected loss are introduced, of which the latter is used in place of the conventional loss. This integration of probabilistic models with boosting allows its use in problems where labels are not available.
Sections 7 and 8 conclude the paper with an extensive comparison between the proposed models. It is clearly shown neither of the boosting approaches employed manage to outperform a simple bagging model that is trained on presegmented phonetic data. Furthermore, in a follow-up experiment, we find that the performance of bagging when using triphone models achieves state-of-the art results for the dataset used. These are significant findings, since most of the recent ensemble-based hidden Markov model research on speech recognition has focused invariably on boosting.
2. Background and Notation
Sequence learning and sequential decision making deal with the problem of modelling the relationship between sequential variables from a set of data and then using the models to make decisions. In this paper, we examine two types of sequence learning tasks: sequence classification and sequence recognition.
The sequence classification task entails assigning a sequence to one or more of a set of categories. More formally, we assume a finite label set  and a possibly uncountably infinite observation set
and a possibly uncountably infinite observation set  . We denote the set of sequences of length
. We denote the set of sequences of length  as
as  and the null sequence set by
and the null sequence set by  . Finally, we denote the set of all sequences by
. Finally, we denote the set of all sequences by  . We observe sequences
. We observe sequences  , with
, with  and
and  , and we use
, and we use  to denote the length of a sequence
to denote the length of a sequence  , while
, while  denotes subsequences. In sequence classification, each
denotes subsequences. In sequence classification, each  is associated with a label
is associated with a label  . A sequence classifier
. A sequence classifier  , is a mapping
, is a mapping  , such that
, such that  corresponds to the predicted label, or classification decision, for the observed sequence
corresponds to the predicted label, or classification decision, for the observed sequence  .
.
We focus on probabilistic classifiers, where the predicted label is derived from the conditional probability of the class given the observations, or posterior class probability , with
, with  ,
,  , where we make no distinction between random variables and their realisations. More specifically, we consider a set of models
, where we make no distinction between random variables and their realisations. More specifically, we consider a set of models  and an associated set of observation densities and class probabilities
and an associated set of observation densities and class probabilities  indexed by
indexed by  . The posterior class probability according to model
. The posterior class probability according to model  can be obtained by using Bayes' theorem:
can be obtained by using Bayes' theorem:

Any model  can be used to define a classification rule.
can be used to define a classification rule.
Definition 1 (Bayes classifier).
A classifier  that employs (1) and makes classification decisions according to
that employs (1) and makes classification decisions according to

is referred to as a Bayes classifier or a Bayes decision rule.
Formally, this task is exactly the same as nonsequential classification. The only practical difference is that the observations are sequences. However, care should be taken as this makes the implicit assumption that the costs of all incorrect decisions are equal.
In sequence recognition, we attempt to determine a sequence of events from a sequence of observations. More formally, we are given a sequence of observations  and are required to determine a sequence of labels
and are required to determine a sequence of labels  , that is, the sequence
, that is, the sequence  ,
,  , with maximum posterior probability
, with maximum posterior probability  . In practice, models are used for which it is not necessary to exhaustively evaluate the set of possible label sequences. One such simple, yet natural, class is that of hidden Markov models.
. In practice, models are used for which it is not necessary to exhaustively evaluate the set of possible label sequences. One such simple, yet natural, class is that of hidden Markov models.
2.1. Speech Recognition with Hidden Markov Models
Definition 2 (hidden Markov model).
A hidden Markov model (HMM) is a discrete-time stochastic process, with state variable  in some discrete space
in some discrete space  , and an observation variable
, and an observation variable  , such that
, such that

The model is characterised by the observation distribution  , the transition distribution
, the transition distribution  , and the initial state distribution
, and the initial state distribution  . These dependencies are shown graphically in Figure 1.
. These dependencies are shown graphically in Figure 1.

Graphical representation of a hidden Markov model, with arrows indicating dependencies between variables. The observations  and the next state
and the next state  only depend on the current state
only depend on the current state  .
.
Training consists of two steps. First, select a class of hidden Markov models  , with each model
, with each model  corresponding to a pair of transition and observation densities
corresponding to a pair of transition and observation densities  ,
,  . The second step is to select a model from
. The second step is to select a model from  . By additionally defining a prior density
. By additionally defining a prior density  over
over  , we can try to find the maximum a posteriori (MAP) model
, we can try to find the maximum a posteriori (MAP) model  , given a set of observation sequences
, given a set of observation sequences 

The class  is restricted to models with a particular number of states and allowed transitions between states. In this paper, the optimisation is performed through expectation maximisation.
is restricted to models with a particular number of states and allowed transitions between states. In this paper, the optimisation is performed through expectation maximisation.
The most common way to apply such models to speech recognition is to associate each state  with phonological units
with phonological units  , such as phonemes, syllables, or words, through a distribution
, such as phonemes, syllables, or words, through a distribution  , which takes values in
, which takes values in  in usual practice; thus, each state is mapped to only one phoneme. This is done by modelling each phoneme as a small HMM (Figure 2) and combining them into a larger HMM, such as the one shown in Figure 3, with a set of parallel chains such that each chain maps to one word; for example, given that we are in the state
in usual practice; thus, each state is mapped to only one phoneme. This is done by modelling each phoneme as a small HMM (Figure 2) and combining them into a larger HMM, such as the one shown in Figure 3, with a set of parallel chains such that each chain maps to one word; for example, given that we are in the state  at some time
at some time  , then we are also definitely (i.e., with probability 1) in Word A and Phoneme B at time
, then we are also definitely (i.e., with probability 1) in Word A and Phoneme B at time  . In general, if we can determine the probabilities for sequences of states, we can also determine the most probable sequence of words or phonemes; that is, given a sequence of observations
. In general, if we can determine the probabilities for sequences of states, we can also determine the most probable sequence of words or phonemes; that is, given a sequence of observations  , we calculate the state distribution
, we calculate the state distribution  and subsequently a distribution over phonologies, to wit the probabilities of possible word, syllable, or phoneme sequences. Thus, the problem of recognising word sequences is reduced to the problem of state estimation.
and subsequently a distribution over phonologies, to wit the probabilities of possible word, syllable, or phoneme sequences. Thus, the problem of recognising word sequences is reduced to the problem of state estimation.

Graphical representation of a phoneme model with 3 emitting states, as well as initial and terminal nonemitting states. The arrows depict dependencies between specific states. All the phoneme models used in this paper employed the above topology.

A hidden Markov model for speech recognition. The figure depicts how models of three phonemes,  ,
,  ,
,  , are used to construct a single hidden Markov model for distinguishing between two different words. The states are indexed uniquely. Black circles indicate non-emitting states.
, are used to construct a single hidden Markov model for distinguishing between two different words. The states are indexed uniquely. Black circles indicate non-emitting states.
2.2. Multistream Decoding
When we wish to combine evidence from  different models, state estimation is significantly harder, as the number of effective states is
different models, state estimation is significantly harder, as the number of effective states is  . However, multistream decoding techniques can be used as an approximation to the full mixture model [4]. Such techniques derive their name from the fact that they were originally used to combine models which had been trained on different streams of data or features [5]. In this paper, we instead wish to combine evidence from models trained on different samples of the same data.
. However, multistream decoding techniques can be used as an approximation to the full mixture model [4]. Such techniques derive their name from the fact that they were originally used to combine models which had been trained on different streams of data or features [5]. In this paper, we instead wish to combine evidence from models trained on different samples of the same data.
In multistream decoding each subunit model corresponding to a phonological unit  is comprised of
is comprised of  submodels
submodels  associated with the subunit level at which the recombination of the input streams should be performed. For any given
associated with the subunit level at which the recombination of the input streams should be performed. For any given  and a distribution over models
and a distribution over models  , the observation density conditioned on the unit
, the observation density conditioned on the unit  can be written as
can be written as

where  can be seen as a weight for expert
can be seen as a weight for expert  . This may vary across
. This may vary across  , but herein we consider the case where the weight is fixed, that is,
, but herein we consider the case where the weight is fixed, that is,  for all
for all  . We considerstate-locked multistream decoding, where all submodels are forced to be at the same state. This can be viewed as creating another Markov model with emission distribution
. We considerstate-locked multistream decoding, where all submodels are forced to be at the same state. This can be viewed as creating another Markov model with emission distribution

An alternative is the exponentially weighted product of emission distributions:

However, this approximation does not arise from (5) but from assuming a factorisation of the observations  , which is useful when there is a different model for different parts of the observation vector.
, which is useful when there is a different model for different parts of the observation vector.
Multistream techniques are hardly limited to the above. For example, Misra et al. [6] describe a system where  is related to the entropy of each submodel, while Ketabdar et al. [7] describe a multistream method utilising state posteriors. We, however, shall concentrate on the two techniques outlined above, as well as a single-stream technique to be described in Section 5.1.
is related to the entropy of each submodel, while Ketabdar et al. [7] describe a multistream method utilising state posteriors. We, however, shall concentrate on the two techniques outlined above, as well as a single-stream technique to be described in Section 5.1.
2.3. Ensemble Methods
We investigate the use of ensemble methods in the class ofstatic mixture models for speech recognition. Such methods construct an aggregate model from a set of base hypotheses  . Each hypothesis
. Each hypothesis  indexes a set of conditional distributions
indexes a set of conditional distributions  . To complete the model, we employ a set of weights
. To complete the model, we employ a set of weights  corresponding to the probability of each base hypothesis, so that
corresponding to the probability of each base hypothesis, so that  . Thus, we can form a mixture model, assuming
. Thus, we can form a mixture model, assuming  for all
for all  :
:

Two questions that arise when training such models are how to select  and
and  . In this paper, we consider two different approaches, bagging and boosting.
. In this paper, we consider two different approaches, bagging and boosting.
2.3.1. Bagging
Bagging [8] can be seen as a method for sampling the model space  . We first require a learning algorithm
. We first require a learning algorithm  that maps (While we restrict ourselves to the deterministic case for simplicity, bagging is applicable to stochastic learning algorithms as well.) from adataset
that maps (While we restrict ourselves to the deterministic case for simplicity, bagging is applicable to stochastic learning algorithms as well.) from adataset of data pairs
of data pairs  to models
to models  . We then sample
. We then sample  datasets
datasets  from a distribution
from a distribution  , for
, for  . For each
. For each  , the learning algorithm
, the learning algorithm  generates a model
generates a model  . The models
. The models  can be combined into a mixture with
can be combined into a mixture with  for all
for all  :
:

In Bagging,  is generated by sampling with replacement from the original dataset
is generated by sampling with replacement from the original dataset  , with
, with  . Thus,
. Thus,  is a bootstrap replicate of
is a bootstrap replicate of  .
.
2.3.2. Boosting
Boosting algorithms [9–11] are another family of ensemble methods. The most commonly used boosting algorithm for classification is AdaBoost [9]. Though many variants of AdaBoost for multiclass classification problems exist, in this paper we will use AdaBoost.M1.
An AdaBoost ensemble is a mixture model composed of  models
models  and weights
and weights  , as in the previous section. The models and weights are created in an iterative manner. At iteration
, as in the previous section. The models and weights are created in an iterative manner. At iteration  , the model
, the model  is created from aweighted bootstrap sample
is created from aweighted bootstrap sample  of the training dataset
of the training dataset  , with
, with  . The probability of adding example
. The probability of adding example  to the bootstrap replicate
to the bootstrap replicate  is denoted as
is denoted as  , with
, with  . At the end of iteration
. At the end of iteration  of AdaBoost.M1,
of AdaBoost.M1,  is calculated according to
is calculated according to

where  is the empirical expected loss of the
is the empirical expected loss of the  th, with
th, with  being the sample loss of example
being the sample loss of example  , where
, where  is an indicator function. At the end of each iteration, sampling probabilities are updated according to
is an indicator function. At the end of each iteration, sampling probabilities are updated according to

where  is a normalisation factor. Thus, incorrectly classified examples are more likely to be included in the next bootstrap data set. The final model is a mixture with
is a normalisation factor. Thus, incorrectly classified examples are more likely to be included in the next bootstrap data set. The final model is a mixture with  components
components  and weights
and weights  .
.
3. Contributions and Related Work
The original AdaBoost algorithm had been defined for classification and regression tasks, with the regression case receiving more attention recently (see [10] for an overview). In addition, research in the application of boosting to sequence learning and speech recognition has intensified [12–15]. The application of other ensemble methods, however, has been limited to random decision trees [16, 17]. In our view, bagging [8] is a method that has been somewhat unfairly neglected, and we present results that show that it can outperform boosting in an unbiased experiment.
One of the simplest ways to apply ensemble methods to speech recognition is to employ them at the state level. For example, Schwenk [18] proposed a HMM/artificial neural network (ANN) system, with the ANNs used to compute the posterior phoneme probabilities at each state. Boosting itself was performed at the ANN level, using AdaBoost with confidence-rated predictions, using the frame error rate as the sample loss function. The resulting decoder system differed from a normal HMM/ANN hybrid in that each ANN was replaced by a mixture of ANNs that had been provided via boosting. Thus, such a technique avoids the difficulties of performing inference on mixtures, since the mixtures only model instantaneous distributions. Zweig and Padmanabhan [19] appear to be using a similar technique, based on Gaussian mixtures. The authors additionally describe a few boosting variants for large-scale systems with thousands of phonetic units. Both papers report mild improvements in recognition.
One of the first approaches to utterance-level boosting is due to Cook and Robinson [20], who employed a boosting scheme, where the sentences with the highest error rate were classified as "incorrect" and the rest "correct," irrespective of the absolute word error rate of each sentences. The weights of all frames constituting a sentence were adjusted equally and boosting was applied at the frame level. This however does not manage to produce as good results as the other schemes described by the authors. In our view, which is partially supported by the experimental results in Section 6, this could have been partially due to the lack of a temporal credit assignment mechanism such as the one we present. An early example of a nonboosting approach for the reduction of word error rate is [21], which employed a "corrective training scheme."
In related work on utterance-level boosting, Zhang and Rudnicky [22] compared use of the posterior probability of each possible utterance for adjusting the weights of each utterance with a "nonboosting" method, where the same weights are adjusted according to some function of the word error rate. In either case, utterance posterior probabilities are used for recombining the experts. Since the number of possible utterances is very large, not all possible utterances are used but an  -best list. For recombination, the authors consider two methods: firstly, choosing the utterance with maximal sum of weighted posterior (where the weights have been determined by boosting). Secondly, they consider combining via ROVER, a dynamic programming method for combining multiple speech recognisers (see [23]). Since the authors' use of ROVER entails using just one hypothesis from each expert to perform the combination, in [15] they consider a scheme where the
-best list. For recombination, the authors consider two methods: firstly, choosing the utterance with maximal sum of weighted posterior (where the weights have been determined by boosting). Secondly, they consider combining via ROVER, a dynamic programming method for combining multiple speech recognisers (see [23]). Since the authors' use of ROVER entails using just one hypothesis from each expert to perform the combination, in [15] they consider a scheme where the  -best hypotheses are reordered according to their estimated word error rate. In further work [24] the authors consider a boosting scheme for assigning weights to frames, rather than just to complete sentences. More specifically, they use the currently estimated model to obtain the probability that the correct word has been decoded at any particular time, that is, the posterior probability that the word at time
-best hypotheses are reordered according to their estimated word error rate. In further work [24] the authors consider a boosting scheme for assigning weights to frames, rather than just to complete sentences. More specifically, they use the currently estimated model to obtain the probability that the correct word has been decoded at any particular time, that is, the posterior probability that the word at time  is
is  given the model and the sequence of observations. In our case we use a slightly different formalism in that we calculate the expectation of the loss according to an independent model.
given the model and the sequence of observations. In our case we use a slightly different formalism in that we calculate the expectation of the loss according to an independent model.
Finally, Meyer and Schramm [13] propose an interesting boosting scheme with a weighted sum model recombination. More precisely, the authors employ AdaBoost.M2 at the utterance level, utilising the posterior probability of each utterance for the loss function. Since the algorithm requires calculating the posterior of every possible class (in this case an utterance) given the data, exact calculation is prohibitive. The required calculation however can be approximated by calculating the posterior only for the subset of the top  utterances and assuming the rest are zero. Their model recombination scheme relies upon treating each expert as a different pronunciation model. This results in essentially a mixture model in the form of (5), where the weight of each expert is derived from the boosting algorithm. They further robustify their approach through a language model. Their results indicate a slight improvement (in the order of
utterances and assuming the rest are zero. Their model recombination scheme relies upon treating each expert as a different pronunciation model. This results in essentially a mixture model in the form of (5), where the weight of each expert is derived from the boosting algorithm. They further robustify their approach through a language model. Their results indicate a slight improvement (in the order of  ) in a large vocabulary continuous speech recognition experiment.
) in a large vocabulary continuous speech recognition experiment.
More recently, an entirely different and interesting class of complementary models were proposed in [12, 16, 17]. The core idea is the use of randomised decision trees to create multiple experts, which allows for more detailed modelling of the strengths and weaknesses of each expert, while [12] presents an extensive array of methods for recombination during speech recognition. Other recent work has focused on slightly different applications. For example, a boosting approach for language identification was used in [14, 25], which utilised an ensemble of Gaussian mixture models for both the target class and the antimodel. In general, however, bagging methods, though mentioned in the literature, do not appear to be used, and recent surveys, such as [12, 26, 27] do not include discussions of bagging.
3.1. Our Contribution
This paper presents methods and results for the use of both boosting and bagging for phoneme classification and speech recognition. Apart from synthesising and extending our previous results [2, 3], the main purpose of this paper is to present an unbiased experimental comparison between a large number of methods, controlling for the appropriate choice of hyperparameters and using a principled statistical methodology for the evaluation of the significance of the results. If this is not done, then it is possible to draw incorrect conclusions.
Section 5 describes our approach for phoneme-level training of ensemble methods (boosting and bagging). In the phoneme classification case, the formulation of the task is essentially the same as that of static classification; the only difference is that the observations are sequences rather than single values. As far as we know, our past work [2] is the only one employing ensemble methods at the phoneme level. In Section 5, we extend our previous results by comparing boosting and bagging in terms of both classification and recognition performance and show, interestingly, that bagging achieves the same reduction in recognition error rates as boosting, even though it cannot match boosting classification error rate reduction. In addition, the section compares a number of different multistream decoding techniques.
Another interesting way to apply boosting is to use it at the sentence level, for the purposes of explicitly minimising the word error rate. Section 6 presents a boosting-based approach to minimise the word error rate originally introduced in [3].
Finally, Section 7 presents an extensive, unbiased experimental comparison, with separate model selection and model testing phase, between the proposed methods and a number of baseline systems. This shows that the simple phoneme-level bagging scheme outperforms all of the other boosting schemes explored in this paper significantly. Finally, further results using tri-phone models indicate that state-of-the-art performance is achievable for this dataset using bagging but not boosting.
4. Data and Methods
The phoneme data was based on a presegmented version of the OGI Numbers 95 (N95) data set [28]. This data set was converted from the original raw audio data into a set of features based on Mel-Frequency Cepstrum Coefficients (MFCC) [29] (with 39 components, consisting of three groups of 13 coefficients, namely, the static coefficients and their first and second derivatives) that were extracted from each frame. The data contains 27 distinct phonemes (or 80 tri-phones in the tri-phone version of the dataset) that compose 30 dictionary words. There are 3233 training utterances and 1206 test utterances, containing 12510 and 4670 words, respectively. The segmentation of the utterances into their constituent phonemes resulted in 35562 training segments and 12613 test segments, totalling 486537 training frames and 180349 test frames, respectively. The feature extraction and phonetic labelling are described in more detail in [30].
4.1. Performance Measures
The comparative performance measure used depends on the task. For the phoneme classification task, the classification error is used, which is the percentage of misclassified examples in the training or testing data set. For the speech recognition task, the following word error rate is used:

where  is the number of word insertions,
is the number of word insertions,  the number of word substitutions, and
the number of word substitutions, and  the number of word deletions. These numbers are determined by finding the minimum number of insertions, substitutions, or deletions necessary to transform the target utterance into the emitted utterance for each example and then summing them for all the examples in the set.
the number of word deletions. These numbers are determined by finding the minimum number of insertions, substitutions, or deletions necessary to transform the target utterance into the emitted utterance for each example and then summing them for all the examples in the set.
4.2. Bootstrap Estimate for Speech Recognition
In order to establish the significance of the reported results, we employ a bootstrap method; (see [31]). More specifically, we use the approach suggested by Bisani and Ney [32] for speech recognition. It amounts to using the results of speech recognition on a test set of sentences as an empirical distribution of errors. Using this method, we obtain a bootstrap estimate of the probability distribution of the difference in word error rate  between two systems, from
between two systems, from  bootstrap samples
bootstrap samples  of the word error rate difference:
of the word error rate difference:

where  is an indicator function. This approximates the probability that system
is an indicator function. This approximates the probability that system  is better than system
is better than system  by more than
by more than  . See [31] for more on the properties of the bootstrap and [33] for the convergence of empirical processes and their relation to the bootstrap.
. See [31] for more on the properties of the bootstrap and [33] for the convergence of empirical processes and their relation to the bootstrap.
4.3. Parameter Selection
The models employed have a number of hyperparameters. In order to perform unbiased comparisons, we split the training data into a smaller training set of 2000 utterances and a hold-out set of 1233 utterances. For the preliminary experiments performed in Sections 5 and 6, we train all models on the small training set and report the performance on both the training and the hold-out set. For the experiments in Section 7, each model's hyperparameters are selected independently on the hold-out set. Then the model is trained on the complete training set and evaluated in the independent test set.
For the classification task (Section 5), we used presegmented data. Thus, the classification could be performed using a Bayes classifier composed of 27 hidden Markov models, each one corresponding to one class. Each phonetic HMM was composed of the same number of hidden states (And an additional two nonemitting states: the initial and final states.), in a left-to-right topology, and the distributions corresponding to each state were modelled with a Gaussian mixture model, with each Gaussian having a diagonal covariance matrix. In Section 5.2, we select the number of states per phoneme from  and the mixture components from
and the mixture components from  in the hold-out set for a single HMM and then examine whether bagging or boosting can improve the classification or speech recognition performance.
in the hold-out set for a single HMM and then examine whether bagging or boosting can improve the classification or speech recognition performance.
In all cases, the diagonal covariance matrix elements of each Gaussian were clamped to a lower limit of 0.2 times the global variance of the data. For continuous speech recognition, transitions between word models incurred an additional likelihood penalty of  while calculating the most likely sequence of states. Finally, in all continuous speech recognition tasks, state sequences were constrained to remain in the same phoneme for at least three acoustic frames.
while calculating the most likely sequence of states. Finally, in all continuous speech recognition tasks, state sequences were constrained to remain in the same phoneme for at least three acoustic frames.
For phoneme-level training, the adaptation of each phoneme model was performed in two steps. Firstly, the acoustic frames belonging to each phonetic segment were split into a number of equally sized intervals, where the number of intervals was equal to the number of states in the phonetic model. The Gaussian mixture components corresponding to the data for each interval were initialised via 25 iterations of the K-means algorithm (see, e.g., [34]). After this initialisation was performed, a maximum of 25 iterations of the EM algorithm were run on each model, with optimisation stopping earlier if, at any point in time  , the likelihood
, the likelihood  satisfied the stopping criterion
satisfied the stopping criterion  , with
, with  being used in all experiments that employed EM for optimisation.
being used in all experiments that employed EM for optimisation.
For the utterance-level training described in Section 6, the same initialisation was performed. The inference of the final model was done through expectation maximisation (using the Viterbi approximation) on concatenated phonetic models representing utterances. Note that performing the full EM computation is costlier and does not result in significantly better generalisation performance, at least in this case. The stopping criterion and maximum iterations were the same as those used for phoneme-level training.
Finally, the results in Section 7 present an unbiased comparison between models. In order to do this, we selected the parameters of each model, such as the number of Gaussians and number of experts, using the performance in the hold-out set. We then used the selected parameters to train a model on the full training dataset. The models were evaluated on the separate testing dataset and compared using the bootstrap estimate described in Section 4.2.
5. Phoneme-Level Bagging and Boosting
A simple way to apply ensemble techniques such as bagging and boosting is to cast the problem into the classification framework. This is possible at the phoneme level, where each class  corresponds to a phoneme. As long as the available data are annotated so that subsequences containing single phoneme data can be extracted, it is natural to adapt each hidden Markov model
corresponds to a phoneme. As long as the available data are annotated so that subsequences containing single phoneme data can be extracted, it is natural to adapt each hidden Markov model  to a single class
to a single class  out of the possible
out of the possible  , where
, where  denotes the cardinality of the set, and combine the models into a Bayes classifier in the manner described in Section 2. Such a Bayes classifier can then be used as an expert in an ensemble.
denotes the cardinality of the set, and combine the models into a Bayes classifier in the manner described in Section 2. Such a Bayes classifier can then be used as an expert in an ensemble.
In both cases, each example  in the training dataset
in the training dataset  is a sequence segment corresponding to data from a single phoneme. Consequently, each example
is a sequence segment corresponding to data from a single phoneme. Consequently, each example  has the form
has the form  , with
, with  being a subsequence of features corresponding to single phoneme data and
being a subsequence of features corresponding to single phoneme data and  being a phoneme label.
being a phoneme label.
Both methods iteratively construct an ensemble of  models. At each iteration
models. At each iteration  , a new classifier
, a new classifier  is created, consisting of a set of hidden Markov models:
is created, consisting of a set of hidden Markov models:  . Each model
. Each model  is adapted to the set of examples
is adapted to the set of examples  , where
, where  is a bootstrap replicate of
is a bootstrap replicate of  . In order to make decisions, the experts are weighted by the mixture coefficients
. In order to make decisions, the experts are weighted by the mixture coefficients  . The only difference between the two methods is the distribution that
. The only difference between the two methods is the distribution that  is sampled from and the definition of the coefficients.
is sampled from and the definition of the coefficients.
For "bagging",  is sampled uniformly from
is sampled uniformly from  , and the probability over the mixture components is also uniform, that is,
, and the probability over the mixture components is also uniform, that is,  .
.
For "boosting",  is sampled from
is sampled from  using the distribution defined in (11), while the expert weights are defined as
using the distribution defined in (11), while the expert weights are defined as  , where
, where  is given by (10). The AdaBoost method used was AdaBoost.M1.
is given by (10). The AdaBoost method used was AdaBoost.M1.
Since previous studies in nonsequential classification problems had shown that an increase in generalisation performance may be obtained through the use of those two ensemble methods, it was expected that they would have a similar effect on performance in phoneme classification tasks. This is tested in Section 5.2. While using the resulting phoneme classification models for continuous speech recognition is not straightforward, we describe some techniques for combining the ensembles resulting from this training in order to perform sequence recognition in Section 5.1.
5.1. Continuous Speech Recognition with Mixtures
The approach described is easily suitable for phoneme classification, since each phonetic model is now a mixture model (Figure 4), which can be used to classify phonemes given presegmented data. However, the phoneme mixtures can also be combined into a speech recognition mixture. Thus, we can still employ ensemble methods for the full speech recognition problem by training with segmented data to produce a number of expert models which can then be recombined during decoding on unsegmented data.

A phoneme mixture model. The generating model depends on the hidden variable  , which determines the mixing coefficients between model 1 and 2. The random variable
, which determines the mixing coefficients between model 1 and 2. The random variable  may in general depend on other variables. The distribution of the observation is a mixture between the two distributions predicted by the two hidden models, mixed according to the mixture model
may in general depend on other variables. The distribution of the observation is a mixture between the two distributions predicted by the two hidden models, mixed according to the mixture model  .
.
The first technique employed for sequence decoding uses an HMM comprising all phoneme models created during the boosting process, connected in the manner shown in Figure 5. Each phase of the boosting process creates a submodel  , which we will refer to as expert for disambiguation purposes. Each expert is a classification model that employs one hidden Markov model for each phoneme. For some sequence of observations, each expert calculates the posterior probability of each phonetic class given the observation and its model. Two types of techniques are considered for employing the models for inferring a sequence of words.
, which we will refer to as expert for disambiguation purposes. Each expert is a classification model that employs one hidden Markov model for each phoneme. For some sequence of observations, each expert calculates the posterior probability of each phonetic class given the observation and its model. Two types of techniques are considered for employing the models for inferring a sequence of words.

Single-path multistream decoding for two vocabulary words consisting of two phonemes each. When there is only one expert, the decoding process is done normally. In the multiple-expert case, phoneme models from each expert are connected in parallel. The transition probabilities leading from the anchor states to the hidden Markov model corresponding to each experts are the weights  of each expert.
of each expert.
In the single-stream case, decoding is performed using the Viterbi algorithm in order to find a sequence of states maximising the posterior probability of the sequence. A normal hidden Markov model is constructed in the way shown in Figure 5, with each phoneme being modelled as a mixture of expert models. In this case we are trying to find the sequence of states  with maximum likelihood. The transition probabilities leading from anchor states (black circles in the figure) to each model are set to
with maximum likelihood. The transition probabilities leading from anchor states (black circles in the figure) to each model are set to  .
.
This type of decoding would have been appropriate if the original mixture had been inferred as a type of switching model, where only one submodel is responsible for generating the data at each point in time and where switching between models can occur at anchor states.
The models may also be combined using multistream decoding (see Section 2.2). The advantage of such a method is that it uses information from all models. The disadvantage is that there are simply too many states to be considered. In order to simplify this, we consider multistream decoding synchronised at the state level, that is, with the constraint that  if
if  . This corresponds to (5), where the weight of stream
. This corresponds to (5), where the weight of stream  is again
is again  .
.
5.2. Experiments with Boosting and Bagging Phoneme-Level Models
The experiments described in this section were performed with a fixed number of states for all phonemes, as well as with a fixed number of Gaussians per state. The selection of these hyperparameters was performed on a hold-out set, as described in Section 4. The hold-out set results are shown in Figure 6. After selecting those hyperparameters, we perform an exploratory comparison (An experiment that uses an unbiased procedure to select the number of experts independently for boosting and bagging is described in Section 7.) of the performance of boosting and bagging as the number of mixture components are increased, for the tasks of phoneme classification and speech recognition. For the latter problem, we also examine the relative merits of different decoding techniques.

In the experiments reported in Section 5. 2, the number of states and number of Gaussian mixtures per state were tuned on a hold-out set prior to the analysis. (a) displays the word error rate performance of an HMM with 10 Gaussians per state when the number of emitting states per phoneme is varied, with rather dramatic effects. (b) displays the word error rate performance of an HMM with 3 emitting states as the number of Gaussians per state varies. In this case, the effect on generalisation is markedly lower.Hold-out set, 10 Gaussians/stateHold-out set, 3 states/phoneme
Since the available data includes segmentation information, it makes sense to first limit the task to training for phoneme classification. This enables the direct application of ensemble training algorithms by simply using each segment as a training example.
Two methods were examined for this task: bagging and boosting. At each iteration of either method, a sample from the training set was made according to the distribution defined by either algorithm and then a Bayes classifier composed of  hidden Markov models, one for each phonetic class
hidden Markov models, one for each phonetic class  , was trained.
, was trained.
It then becomes possible to apply the boosting and bagging algorithms by using Bayes Classifiers as the experts. The N95 data was presegmented into training examples, so that each one was a segment containing a single phoneme. Bootstrapping was performed by sampling through these examples. The classification error of each classifier was used to calculate the boosting weights. The test data was also segmented in subsequences consisting of single phoneme data, so that the models could be tested on the phoneme classification tasks.
Figure 7 compares the classification performance of bagging and boosting as the number of experts increases with that of the Bayes classifier trained on the full training data. As can be seen in Figure 7(a), both bagging and boosting manage to reduce the phoneme classification error considerably in the training, with boosting continuing to make improvements until the maximum number of iterations. For bagging, the improvement in classification was limited to the first 4 iterations, after which performance remained constant. The situation was similar when comparing the models in the hold-out set, shown in Figure 7(b). There, however, bagging failed to improve upon the baseline system.

Classification errors for a bagged and a boosted ensemble of Bayes Classifiers as the number of experts is increased. For reference, the corresponding errors for a single Bayes Classifier trained on the complete training set are also included. There were 10 Gaussians per state and 3 states per phoneme for all models.TrainingHoldout
Finally, an exploratory comparison between the models on the task of continuous speech recognition was made. This was necessary, in order to decide on a method for performing decoding when dealing with multiple models. The three relatively simple methods of single-stream and multistream decoding (the latter employing either weighted product or weighted sum) were evaluated on the hold-out set. As can be seen in Figure 8, the weighted sum method consistently performed the best for both bagging and boosting. This was expected since it was the only method with some justification in our particular case, as it arises out of constraining the full state inference problem on the mixture. The multistream product method is not justified here, since each model had exactly the same observation variables. The single-stream model could perhaps be justified under the assumption of a switching model, where a different expert can be responsible for the observations in each phoneme. That might explain the fact that its performance is not degrading in the case of bagging, as the components of each mixture should be quite similar to each other, something which is definitely not the case with boosting, where each model is trained on a different distribution of the data.

Generalisation performance on the hold-out set in terms of word error rate after training with segmentation information. Results are shown for both boosting and bagging, using three different methods for decoding. Single-path and multistream. Results are shown for three different methods single-stream (single), and state-locked multistream using either a weighted product (wprod) or weighted sum (wsum) combination.
A fuller comparison between bagging and boosting at the phoneme level will be given in Section 7, where the number of Gaussian units per state and the number of experts will be independently tuned on the hold-out set and evaluated on a separate test set. There, it will be seen that with an unbiased hyperparameter selection, bagging actually outperforms boosting.
6. Expectation Boosting for WER Minimisation
It is also possible to apply ensemble training techniques at the utterance level. As before, the basic models used are HMMs that employ Gaussian mixtures to represent the state observation distributions. Attention is restricted to boosting algorithms in this case. In particular, we shall develop a method that uses boosting to simultaneously utilise information about the complete utterance, together with an estimate about the phonetic segmentation. Since this estimate will be derived from bootstrapping our own model, it is unreliable. The method developed will take into account this uncertainty.
More specifically, similarly to [20], sentence-level labels (sequences of words without time indications) are used to define the error measure that we wish to minimise. The measure used is related to the word error rate, as defined in (12). In addition to a loss function at the sentence level, a probabilistic model is used to define a distribution for the loss at the frame level. Combined, the two can be used for the greedy selection of the next base hypothesis. This is further discussed in the following section.
6.1. Boosting for Word Error Rate Minimisation
In the previous section (and [2]) we have applied boosting to speech recognition at the phoneme level. In that framework, the aim was to reduce the phoneme classification error in presegmented examples. The resulting boosted phoneme models were combined into a single speech recognition model using multistream techniques. It was hoped that we could reduce the word error rate as a side effect of performing better phoneme classification, and three different approaches were examined for combining the models in order to perform continuous speech recognition. However, since the measure that we are trying to improve is the word error rate and since we did not want to rely on the existence of segmentation information, minimising the word error rate directly would be desirable. This section describes such a scheme using boosting techniques.
We describe a training method that we introduced in [3], specific to boosting and hidden Markov models (HMMs), for word error rate reduction. We employ a score that is exponentially related to the word error rate of a sentence example. The weights of the frames constituting a sentence are adjusted depending on our expectation of how much they contribute to the error. Finally, boosting is applied at the sentence and frame level simultaneously. This method has arisen from a twofold consideration: firstly, we need to directly minimise the relevant measure of performance, which is the word error rate. Secondly, we need a way to more exactly specify which parts of an example most probably have contributed to errors in the final decision. Using boosting, it is possible to focus training on parts of the data which are most likely to give rise to errors while at the same time doing it in such a manner as take into account the actual performance measure. We find that both aspects of training have an important effect.
Section 6.1.1 describes word error rate-related loss functions that can be used for boosting. Section 6.1.2 introduces the concept of expected error, for the case when no labels are given for the examples. This is important for the task of word error rate minimisation. Previous sections on HMMs and multistream decoding described how the boosted models are combined for performing the speech recognition task. Experimental results are outlined in Section 6.2. We conclude with an experimental comparison between different methods in Section 7, followed by a discussion.
6.1.1. Sentence Loss Function
A commonly used measure of optimality for speech recognition tasks is the word error rate (12). We would like to minimise this quantity using boosting techniques. In order to do this, a dataset is considered, where each example is a complete sentence and where the loss for each example
for each example  is given by some function of the word error rate for the sentence.
is given by some function of the word error rate for the sentence.
The word error rate for any particular sentence can take values in  , while the AdaBoost algorithm that is employed herein requires a sample loss function with range
, while the AdaBoost algorithm that is employed herein requires a sample loss function with range  . For this reason we employ the ad hoc, but reasonable, mapping
. For this reason we employ the ad hoc, but reasonable, mapping 

where  is the word error rate. When
is the word error rate. When  , an example is considered as classified correctly, and, when
, an example is considered as classified correctly, and, when  , the example is considered to be classified incorrectly. This mapping includes a free parameter
, the example is considered to be classified incorrectly. This mapping includes a free parameter  . Increasing the parameter
. Increasing the parameter  increases the sharpness of the transition, as shown in Figure 9. This function is used for
increases the sharpness of the transition, as shown in Figure 9. This function is used for  in (11).
in (11).

The sentence loss function (14) for  .
.
While this scheme may well result in some improvement in word recognition with boosting, while avoiding relying on potentially erroneous phonetic labels, there is some information that is not utilised. Knowledge of the required sequence of words, together with the obtained sequence of words for each decoded sentence results in a set of errors that are fairly localised in time. The following sections discuss how it is possible to use a model that capitalises on such knowledge in order to define a distribution of errors over time.
6.1.2. Error Expectation for Boosting
In traditional supervised settings we are provided with a set of examples and labels, which constitute our training set, and thus it is possible to apply algorithms such as boosting. However, this becomes problematic when labels are noisy; (see, e.g., [35]). Such an example is a typical speech recognition data set. Most of the time such a data set is composed of a set of sentences, with a corresponding set of transcriptions. However, while the transcriptions may be accurate as far as the intention of the speakers or the hearing of the transcriber is concerned, subsequent translation of the transcription into phonetic labels is bound to be error prone, as it is quite possible for either the speaker to mispronounce words, or for the model that performs the automatic segmentation to make mistakes. In such a situation, adapting a model so that it minimises the errors made on the segmented transcriptions might not automatically lead into a model that minimises the word error rate, which is the real goal of a speech recognition system.
For this purpose, the concept of error expectation is introduced. Thus, rather than declaring with absolute certainty that an example is incorrect or not, we simply define  , so that the sample loss is now the probability that a mistake was made on example
, so that the sample loss is now the probability that a mistake was made on example  and we consider
and we consider  to be a random variable. Since boosting can admit any sample loss function [9], this is perfectly reasonable, and it is possible to use this loss as a sample loss in a boosting context. The following section discusses some cases for the distribution of
to be a random variable. Since boosting can admit any sample loss function [9], this is perfectly reasonable, and it is possible to use this loss as a sample loss in a boosting context. The following section discusses some cases for the distribution of  which are of relevance to the problem of speech recognition.
which are of relevance to the problem of speech recognition.
6.1.3. Error Distributions in Sequential Decision Making
In sequential decision-making problems, the knowledge about the correctness of decisions is delayed. Furthermore, it frequently lacks detailed information concerning the temporal location of errors. A common such case is knowing that we have made one or more errors in the time interval  . This form occurs in a number of settings. In the setting of individual sentence recognition, a sequence of decisions is made which corresponds to an inferred utterance. When this is incorrect, there is little information to indicate, where mistakes were made.
. This form occurs in a number of settings. In the setting of individual sentence recognition, a sequence of decisions is made which corresponds to an inferred utterance. When this is incorrect, there is little information to indicate, where mistakes were made.
In such cases it is necessary to define a model (Even if no model is explicitly defined, there is always one implied.) for the probability of having made an erroneous decision at different points in times  , given that there has been at least one error in the interval
, given that there has been at least one error in the interval  . Let us denote the probability of having made an error at time
. Let us denote the probability of having made an error at time  by
by  . A trivial example of such a model is to assume that the error probability is uniformly distributed. This can be expressed via the flat prior
. A trivial example of such a model is to assume that the error probability is uniformly distributed. This can be expressed via the flat prior

Another useful model is to assume an exponential prior such that

such that the expectation of an error near the end of the decision sequence is much higher. This is useful in tasks where it is expected that the decision error will be temporally close to the information that an error has been made. Ultimately, such models incorporate very little knowledge about the task, apart from this simple temporal structure.
In this case we focus on the application of speech recognition, which has some special characteristics that can be used to more accurately estimate possible locations of errors. For the case of labelled sentence examples, it is possible to have a procedure that can infer the location of an error in time. This is because correctly recognised words offer an indication of where possible errors lie. Assume some procedure that creates an indicator function  such that
such that  for instances in time, where an error could have been made. We can then estimate the probability of having an error at time
for instances in time, where an error could have been made. We can then estimate the probability of having an error at time  as follows:
as follows:

where the parameter  expresses our confidence in the accuracy of
expresses our confidence in the accuracy of  . A value of 1 will cause the probability of an error to be the same for all moments in time, irrespective of the value of
. A value of 1 will cause the probability of an error to be the same for all moments in time, irrespective of the value of  , while, when
, while, when  approaches infinity, we have absolute confidence in the inferred locations. Similar relations can be defined for an exponential prior, and they can be obtained through the convolution of (16) and (17).
approaches infinity, we have absolute confidence in the inferred locations. Similar relations can be defined for an exponential prior, and they can be obtained through the convolution of (16) and (17).
In order to apply boosting to temporal data, where classification decisions are made at the end of each sequence, we use a set of weights  corresponding to the set of frames in an example sentence. At each boosting iteration
corresponding to the set of frames in an example sentence. At each boosting iteration  the weights are adjusted through the use of (17), resulting in the following recursive relation:
the weights are adjusted through the use of (17), resulting in the following recursive relation:

In this manner, the loss incurred by the whole sentence is distributed to its constituent frames, although the choice is rather ad hoc. A different approach was investigated by Zhang and Rudnicky [24], where the loss on the frames was related to the probability of the relevant word being uttered at time  , but their results do not indicate that this is a better choice compared to the simpler utterance-level training scheme that they also propose in that paper.
, but their results do not indicate that this is a better choice compared to the simpler utterance-level training scheme that they also propose in that paper.
6.2. Experiments with Expectation Boosting
We experimented on the OGI Numbers 95 (N95) data set [28] (details about the setup and dataset are given in Section 4). The experiment was performed as follows: firstly, a set of HMMs  , composed of one model per phoneme, was trained using the available phonetic labels. This has the role of a starting point for the subsequent expert models. At each boosting iteration
, composed of one model per phoneme, was trained using the available phonetic labels. This has the role of a starting point for the subsequent expert models. At each boosting iteration  we take the following steps: firstly, we sample with replacement from the distribution of training sentences given by the AdaBoost algorithm. We create a new expert
we take the following steps: firstly, we sample with replacement from the distribution of training sentences given by the AdaBoost algorithm. We create a new expert  , initialised with the parameters of
, initialised with the parameters of  . The expert is trained on the sentence data using EM with the Viterbi approximation in the expectation step to calculate the expectation. The frames of each sequence carry an importance weight
. The expert is trained on the sentence data using EM with the Viterbi approximation in the expectation step to calculate the expectation. The frames of each sequence carry an importance weight  , computed via (18), which is factored into the training algorithm by incorporating it in the posterior probability of the model
, computed via (18), which is factored into the training algorithm by incorporating it in the posterior probability of the model  given the data
given the data  and time
and time  , which, if we assume independence of
, which, if we assume independence of  and
and  , can be written as
, can be written as

In this case,  will correspond to our importance weight
will correspond to our importance weight  .
.
After training, all sequences are decoded with the new expert. The weights of each sentence is increased according to (14), with  . This value was chosen so that any sentence decodings with more than 50% error rate would be considered nearly completely erroneous (see Figure 9). For each erroneously decoded sentence we calculate the edit distance using a shortest path algorithm. All frames for which the inferred state belonged to one of the words that corresponded to a substitution, insertion, or deletion are then marked. The weights of marked frames are adjusted according to (17). The parameter
. This value was chosen so that any sentence decodings with more than 50% error rate would be considered nearly completely erroneous (see Figure 9). For each erroneously decoded sentence we calculate the edit distance using a shortest path algorithm. All frames for which the inferred state belonged to one of the words that corresponded to a substitution, insertion, or deletion are then marked. The weights of marked frames are adjusted according to (17). The parameter  corresponds to how smooth we want the temporal credit assignment to be.
corresponds to how smooth we want the temporal credit assignment to be.
In order to evaluate the combined models we use the multistream method described in (6), where the weight  of each stream
of each stream  is
is  .
.
Experimental results comparing the performance of the above techniques to that of an HMM using segmentation information for training are shown in Figure 10(a) for the training data and Figure 10(b) for the test data. The figures include results for our previous results with boosting at the phoneme level. We have included results for values of  . Although we do not improve significantly upon our previous work with respect to the generalisation error, we found that on the training set, while boosting with presegmented phoneme examples had previously resulted in a reduction of the error to 3% after approximately 30 iterations (not shown), the sentence example training, combined with the error probability distribution over frames, converged to the same error after approximately 6 iterations. The situation was similar in the hold-out set, with the new approach converging to a good generalisation error at 10 iterations, while the previous approach required 16 iterations to reach the same performance. A drawback of the new approach, however, is the need to specify two new hyperparameters: (a) the shape of the cost function and (b) the shape of the expected error distribution. As mentioned previously, for (a) we are using (14) with
. Although we do not improve significantly upon our previous work with respect to the generalisation error, we found that on the training set, while boosting with presegmented phoneme examples had previously resulted in a reduction of the error to 3% after approximately 30 iterations (not shown), the sentence example training, combined with the error probability distribution over frames, converged to the same error after approximately 6 iterations. The situation was similar in the hold-out set, with the new approach converging to a good generalisation error at 10 iterations, while the previous approach required 16 iterations to reach the same performance. A drawback of the new approach, however, is the need to specify two new hyperparameters: (a) the shape of the cost function and (b) the shape of the expected error distribution. As mentioned previously, for (a) we are using (14) with  and for (b) we have chosen a mix between a uniform distribution and an indicator function, with
and for (b) we have chosen a mix between a uniform distribution and an indicator function, with  being a free parameter. Choosing
being a free parameter. Choosing  is not trivial (i.e., it cannot be chosen in the training set), since large values can lead to overfitting, while values that are too small seem to provide no benefit. For the experiments described in Section 7 we will be holding out part of the training set in order to select an appropriate value for
is not trivial (i.e., it cannot be chosen in the training set), since large values can lead to overfitting, while values that are too small seem to provide no benefit. For the experiments described in Section 7 we will be holding out part of the training set in order to select an appropriate value for  .
.

Word error rates for various values of  , compared with the phoneme boosting approach, for the training and the holdout set. TrainingHoldout
, compared with the phoneme boosting approach, for the training and the holdout set. TrainingHoldout
The main interesting feature of the utterance-level approach is that we are minimising the word error rate directly, which is the real objective. Secondly, we do not require segmentation information during training. Lastly, the temporal probability distribution, derived from the word errors and the state inference, provides us with a method to assign weights to parts of the decoded sequence. Its importance becomes obvious when we compare the performance of the method for various values of  . When the distribution is flat (i.e., when
. When the distribution is flat (i.e., when  ), the performance of the model drops significantly. This supports the idea of using a probabilistic model for the errors over training sentences.
), the performance of the model drops significantly. This supports the idea of using a probabilistic model for the errors over training sentences.
7. Generalisation Performance Comparison
In a real-world application one would have to use the training set for selecting hyperparameters to use in unknown data. To perform such a comparison between methods, the training data set was split in two parts, holding out 1/3rd of it for validation. For each training method, we selected the hyperparameters  having the best performance on the hold-out set. In our case, the hyperparameters are a tuple
having the best performance on the hold-out set. In our case, the hyperparameters are a tuple  , where
, where  is the number of Gaussians in the Gaussian mixture model,
is the number of Gaussians in the Gaussian mixture model,  is the number of experts, and
is the number of experts, and  is the temporal credit assignment coefficient for the expectation-boosting method. The number of states was fixed to 3, since our exploratory experiment, described in Section 5, indicated that it was the optimal value by a large margin. For each method, the hyperparameters
is the temporal credit assignment coefficient for the expectation-boosting method. The number of states was fixed to 3, since our exploratory experiment, described in Section 5, indicated that it was the optimal value by a large margin. For each method, the hyperparameters  which provided the best performance in the hold-out set were used to train the model on the full training set. We then evaluated the resulting model on the independent test set. Full details on the data and methods setup are given in Section 4.
which provided the best performance in the hold-out set were used to train the model on the full training set. We then evaluated the resulting model on the independent test set. Full details on the data and methods setup are given in Section 4.
We compared the following approaches: firstly, a Gaussian mixture model (GMM), where the same observation distribution was used for all three states of the underlying phoneme hidden Markov model. This model was trained on the segmented data only; secondly, a standard hidden Markov model (HMM) with three states per phoneme, also trained on the segmented data only. We also considered the same models trained on complete utterances, using embedded training after initialisation on the segmented data. The question we wanted to address was whether (and which) ensemble methods could improve upon these baseline results in an unbiased setting. We first considered ensemble methods trained using segmented data, using the phoneme-level bagging and boosting described in Section 5. This included both bagging and boosting of HMMs, as well as boosting of GMMs, for completeness. In all cases the experimental setup was identical, and the only difference between the boosting and the bagging algorithms was that bagging used a uniform distribution for each bootstrap sample of the data and uniform weights on the expert models. Finally, at the utterance level, we used expectation boosting, which is described in Section 6.
Table 1 summarises the results obtained, indicating the number of Gaussians per phoneme and the word error rate obtained for each model. If one considers only those models that were created strictly using the classification task, that is, without adapting word models, ensemble methods perform significantly better. Against the baseline HMM embed model, which is trained on full utterances, however, not all ensemble methods perform so well.
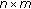 denotes
denotes  models, each having
models, each having 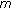 Gaussian components per state. GMM indicates a model consisting of a single Gaussian mixture for each phoneme. HMM indicates a model consisting of three Gaussian mixtures per phoneme. Thus, for HMMs, the total number of Gaussians is three times that of the GMMs with an equal number of components per state. Boost and Bag models indicate models trained using the standard boosting and bagging algorithm, respectively, on the phoneme classification task, while E-boost indicates the expectation boosting algorithm for word error rate minimisation. Finally embed indicates that embedded training was performed subsequently to initialisation of the model.
Gaussian components per state. GMM indicates a model consisting of a single Gaussian mixture for each phoneme. HMM indicates a model consisting of three Gaussian mixtures per phoneme. Thus, for HMMs, the total number of Gaussians is three times that of the GMMs with an equal number of components per state. Boost and Bag models indicate models trained using the standard boosting and bagging algorithm, respectively, on the phoneme classification task, while E-boost indicates the expectation boosting algorithm for word error rate minimisation. Finally embed indicates that embedded training was performed subsequently to initialisation of the model.This can be seen clearly in Figures 11 and 12 which show the probability (Calculated via the bootstrap estimate, detailed in Section 4.2.) that one model will be better than the other by a given amount. In particular, the estimated probability that Boost is better than HMM embed, shown in Figure 12(a), is merely 51%, and the mean difference in performance is just 0.23% while, against the simple HMM the result, shown in Figure 11(a), is statistically significant with a confidence of 91%. Slightly better performance is offered by E-Boost, with significance with respect to the HMM and HMM embed models at 98% and 65%, respectively. Overall bagging works best, performing better than other methods with a confidence of at least 99% in all cases, while approximately 97.5% of the probability mass lying above the 0.5% differential word error rate compared to the baseline model, as can be seen in Figure 12(a).

Significance levels of word error rate difference between the phoneme-level bagging and boosting and HMM. The histograms are created from 10,000 bootstrap samples of the test data, as described in Section 4.2. WERdiff displays the average difference in word error rate performance between the two methods. Positive values indicate that the first method has lower error than the second. The percentage values indicate the tail mass of the histogram to that point.Bag versus HMMBoost versus HMM

Significance levels of word error rate difference between the top four models. The histograms are created from 10,000 bootstrap samples of the test data, as described in Section 4.2. WERdiff displays the average difference in word error rate performance between the two methods. Positive values indicate that the first method has lower error than the second. The percentage values indicate the tail mass of the histogram to that point.Boost versus HMM embedE-Boost versus HMM embedBag versus HMM embedE-Boost versus BoostBag versus BoostBag versus E-Boost
However, these results are not quite near the state of the art on this database. Other researchers (see, e.g., [36–40]) have achieved word error rates  %, mainly through the use of different phonetic models. Accordingly, some further experiments were performed with Markov models using a more complex phonetic model (composed of 80 triphones, i.e., phonemes with contextual information). After performing the same model selection procedure as above, a single such model achieved word error rates of
%, mainly through the use of different phonetic models. Accordingly, some further experiments were performed with Markov models using a more complex phonetic model (composed of 80 triphones, i.e., phonemes with contextual information). After performing the same model selection procedure as above, a single such model achieved word error rates of  % (not shown in the table) which is in agreement with published state-of-the-art results. This suggests that using a more complex model could be better than using mixtures of simpler models. Corresponding results for ensembles of triphone models indicated that the boosting-based approaches could not increase generalisation performance, achieving a word error rate of 5.1%. However, the simpler bagging approach managed to reach a performance of 4.5%. However, the performance differences are not really significant in this case.
% (not shown in the table) which is in agreement with published state-of-the-art results. This suggests that using a more complex model could be better than using mixtures of simpler models. Corresponding results for ensembles of triphone models indicated that the boosting-based approaches could not increase generalisation performance, achieving a word error rate of 5.1%. However, the simpler bagging approach managed to reach a performance of 4.5%. However, the performance differences are not really significant in this case.
Nevertheless, it appears that, in all cases, phoneme bagging is the most robust approach. The reasons for this are not apparent, but it is tempting to conclude that the label noise combined with the variance-reducing properties of bagging is at least partially responsible. Although it should be kept in mind that the aforementioned triphone results are limited in significance due to the small difference in performance between methods, they nevertheless indicate that in certain situations ensemble methods and especially bagging may be of some use to the speech recognition community.
8. Discussion
We presented some techniques for the application of ensemble methods to HMMs. The ensemble training was performed for complete HMMs at either the phoneme or the utterance level, rather than at the frame level. Using boosting techniques at the utterance level was thought to lead to a method for reducing the word error rate. Interestingly, this word error rate reduction scheme did not improve generalisation performance for boosting, while the simplest approach of all, bagging, performed the best.
There are a number of probable causes. The first one is that the amount of data is sufficiently large for ensemble techniques to have little impact on performance; that is, there is enough data to train sufficiently good base models. The second is that the state-locked multistream decoding techniques that were investigated for model recombination led to an increase in generalisation error as the inference performed is very approximate. The third is that the boosting approach used is simply inappropriate. The first case must not be true, since bagging does achieve considerable improvements over the other methods. There is some evidence for the second case, since the GMM ensembles are the only ones that should not be affected by the multistream approximations and, while a more substantial performance difference can be observed, it nevertheless is not much greater. The fact that bagging's phoneme mixture components are all trained on samples from the same distribution of data and that it outperforms boosting is also in agreement with this hypothesis. This leaves the possibility that the type of boosting training used is inappropriate, at least in conjunction with the decoding method used, open.
Future research in this direction might include the use of other approximations for decoding than constrained multistream methods. Such an approach was investigated by Meyer and Schramm [13], where the authors additionally consider the harder problem of large vocabulary speech recognition (for which even inferring the most probable sequence of states in a single model may be computationally prohibitive). It could thus be also possible to use the methods developed herein for large vocabulary problems by borrowing some of their techniques. The first technique, also used in [22], relies on finding an  -best list of possible utterances, assuming that there are no other possible utterances and then fully estimating the posterior probability of the
-best list of possible utterances, assuming that there are no other possible utterances and then fully estimating the posterior probability of the  alternatives. The second technique, developed by Schramm and Aubert [41], combines multiple pronunciation models. In this case each model arising from boosting could be used in lieu of different pronunciation models. Another possible future direction is to consider different algorithms. Both AdaBoost.M1, which was employed here, and AdaBoost.M2, are using greedy optimisation for the mixture coefficients. Perhaps better optimisation procedures, such as those proposed by Mason et al. [42], may result in an additional advantage.
alternatives. The second technique, developed by Schramm and Aubert [41], combines multiple pronunciation models. In this case each model arising from boosting could be used in lieu of different pronunciation models. Another possible future direction is to consider different algorithms. Both AdaBoost.M1, which was employed here, and AdaBoost.M2, are using greedy optimisation for the mixture coefficients. Perhaps better optimisation procedures, such as those proposed by Mason et al. [42], may result in an additional advantage.
References
Dimitrakakis C: Ensembles for sequence learning, Ph.D. thesis. École Polytechnique Fédérale de Lausanne; 2006.
Dimitrakakis C, Bengio S: Boosting HMMs with an application to speech recognition. Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing, May 2004 621-624.
Dimitrakakis C, Bengio S: Boosting word error rates. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP '05), 2005 5: 501-504.
Morris A, Hagen A, Glotin H, Bourlard H: Multi-stream adaptive evidence combination for noise robust ASR. Speech Communication 2001,34(1-2):25-40. 10.1016/S0167-6393(00)00044-3
Misra H, Bourlard H: Spectral entropy feature in full-combination multi-stream for robust ASR. Proceedings of the 9th European Conference on Speech Communication and Technology, 2005, Lisbon, Portugal 2633-2636.
Misra H, Bourlard H, Tyagi V: New entropy based combination rules in HMM/ANN multi-stream ASR. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP '03), 2003, Hong Kong 2: 741-744.
Ketabdar H, Bourlard H, Bengio S: Hierarchical multistream posterior based speech recognition system. 2005, IDIAP-RR 25, IDIAP
Breiman L: Bagging predictors. Machine Learning 1996,24(2):123-140.
Freund Y, Schapire RE: A decision-theoretic generalization of on-line learning and an application to boosting. Journal of Computer and System Sciences 1997,55(1):119-139. 10.1006/jcss.1997.1504
Meir R, Rätsch G: An introduction to boosting and leveraging. in Advanced Lectures on Machine Learning, vol. 2600 of Lecture Notes in Computer Science, 2003 118-183.
Schapire RE, Singer Y: Improved boosting algorithms using confidence-rated predictions. Machine Learning 1999,37(3):297-336. 10.1023/A:1007614523901
Breslin C: Generation and combination of complementary systems for automatic speech recognition, Ph.D. thesis. Cambridge University Endingeering Department and Darwin College; 2008.
Meyer C, Schramm H: Boosting HMM acoustic models in large vocabulary speech recognition. Speech Communication 2006,48(5):532-548. 10.1016/j.specom.2005.09.009
Yang X, Siu M-h, Gish H, Mak B: Boosting with antimodels for automatic language identification. Proceedings of the 8th Annual Conference of the International Speech Communication Association (Inter-Speech '07), 2007 342-345.
Zhang R, Rudnicky AI: Apply n-best list re-ranking to acoustic model combinations of boosting training. Proceedings of the 8th International Conference on Spoken Language Processing (ICSLP '04), 2004 1949-1952.
Breslin C, Gales MJF: Directed decision trees for generating complementary systems. Speech Communication 2009,51(3):284-295. 10.1016/j.specom.2008.09.004
Siohan O, Ramabhadran B, Kingsbury B: Constructing ensembles of asr systems using randomized decision trees. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP '05), 2005 197-200.
Schwenk H: Using boosting to improve a hybrid HMM/neural network speech recognizer. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP '99), 1999 2: 1009-1012.
Zweig G, Padmanabhan M: Boosting Gaussian mixtures in an LVCSR system. Proceedings of IEEE Interntional Conference on Acoustics, Speech, and Signal Processing, June 2000 1527-1530.
Cook G, Robinson A: Boosting the performance of connectionist large vocabulary speech recognition. Proceedings of the International Conference on Spoken Language Processing (ICSLP '96), October 1996, Philadelphia, Pa, USA 3: 1305-1308.
Bahl L, Brown P, de Souza P, Mercer R: A new algorithm for the estimation of hidden Markov model parameters. Proceedings of the IEEE Inernational Conference on Acoustics, Speech and Signal Processig (ICASSP '88), 1988 493-496.
Zhang R, Rudnicky AI: Comparative study of boosting and non-boosting training for constructing ensembles of acoustic models. Proceedings of the 8th European Conference on Speech Communication and Technology (Eurospeech '03), 2003 1885-1888.
Fiscus JG: Post-processing system to yield reduced word error rates: Recognizer Output Voting Error Reduction (ROVER). Proceedings of IEEE Workshop on Automatic Speech Recognition and Understanding, December 1997 347-354.
Zhang R, Rudnicky AI: A frame level boosting training scheme for acoustic modeling. Proceedings of the 8th International Conference on Spoken Language Processing (ICSLP '04), 2004 417-420.
Siu MH, Yang X, Gish H: Discriminatively trained GMMs for language classification using boosting methods. IEEE Transactions on Audio, Speech and Language Processing 2009,17(1):187-197.
Gales M, Young S: The application of hidden Markov models in speech recognition. Foundations and Trends R in Signal Processing 2007,1(3):195-304. 10.1561/2000000004
Zhang R: Making an Effective Use of Speech Data for Acoustic Modeling, Ph.D. thesis. Carnegie Mellon University; 2007.
Cole RA, Roginski K, Fanty M: The OGI numbers database. Oregon Graduate Institute; 1995.
Rabiner LR, Juang B-H: Fundamentals of Speech Recognition. PTR Prentice-Hall; 1993.
Mariéthoz J, Bengio S: A new speech recognition baseline system for Numbers 95 version 1.3 based on Torch. 2004, IDIAP-RR 04-16, IDIAP
Efron B, Tibshirani RJ: An Introduction to the Bootstrap, Monographs on Statistics & Applied Probability. Volume 57. Chapmann & Hall; 1993.
Bisani M, Ney H: Bootstrap estimates for confidence intervals in ASR performance evaluation. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP '04), May 2004 1: 409-412.
Van der Vaart A, Wellner J: Weak Convergence and Empirical Processes: With Applications to Statistics. Springer, Berlin, Germany; 1996.
Bishop CM: Neural Networks for Pattern Recognition. Clarendon Press, Oxford, UK; 1995.
Rätsch G, Onoda T, Müller KR: Soft margins for AdaBoost. Machine Learning 2001,42(3):287-320. 10.1023/A:1007618119488
Athineos M, Hermansky H, Ellis DP: LP-TRAP: linear predictive temporal patterns. Proceedings of the 8th International Conference on Spoken Language Processing (ICSLP '04), 2004 949-952.
Doss MM: Using auxiliary sources of knowledge for automatic speech recognition, Ph.D. thesis. École Polytechnique Fédérale de Lausanne, Computer Science Department, Lausanne, Switzerland; 2005. Thesis No. 3263
Hermansky H, Sharma S: TRAPs—classifiers of temporal patterns. Proceedings of the 5th International Conference on Speech and Language Processing (ICSLP '98), 1998 1003-1006.
Ketabdar H, Vepa J, Bengio S, Bourlard H: Developing and enhancing posterior based speech recognition systems. Proceedings of the 9th European Conference on Speech Communication and Technology, September 2005, Lisbon, Portugal 1461-1464.
Lathoud G, Magimai.-Doss M, Mesot B, Bourlard H: Unsupervised spectral subtraction for noise-robust ASR. Proceedings of IEEE Automatic Speech Recognition and Understanding Workshop (ASRU '05), December 2005 189-194.
Schramm H, Aubert XL: Efficient integration of multiple pronunciations in a large vocabulary decoder. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP '00), 2000 3: 1659-1662.
Mason L, Bartlett PL, Baxter J: Improved generalization through explicit optimization of margins. Machine Learning 2000,38(3):243-255. 10.1023/A:1007697429651
Acknowledgments
This work was supported in part by the IST program of the European Community, under the PASCAL Network of Excellence, IST-2002-506778, and funded in part by the Swiss Federal Office for Education and Science (OFES) and the Swiss NSF through the NCCR on IM2, and the EU-FP7 project IM-CLeVeR.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Dimitrakakis, C., Bengio, S. Phoneme and Sentence-Level Ensembles for Speech Recognition. J AUDIO SPEECH MUSIC PROC. 2011, 426792 (2011). https://doi.org/10.1155/2011/426792
Received:
Accepted:
Published:
DOI: https://doi.org/10.1155/2011/426792