- Research Article
- Open access
- Published:
Tracking Intermittently Speaking Multiple Speakers Using a Particle Filter
EURASIP Journal on Audio, Speech, and Music Processing volume 2009, Article number: 673202 (2009)
Abstract
The problem of tracking multiple intermittently speaking speakers is difficult as some distinct problems must be addressed. The number of active speakers must be estimated, these active speakers must be identified, and the locations of all speakers including inactive speakers must be tracked. In this paper we propose a method for tracking intermittently speaking multiple speakers using a particle filter. In the proposed algorithm the number of active speakers is firstly estimated based on the Exponential Fitting Test (EFT), a source number estimation technique which we have proposed. The locations of the speakers are then tracked using a particle filtering framework within which the decomposed likelihood is used in order to decouple the observed audio signal and associate each element of the decomposed signal with an active speaker. The tracking accuracy is then further improved by the inclusion of a silence region detection step and estimation of the noise-only covariance matrix. The method was evaluated using live recordings of 3 speakers and the results show that the method produces highly accurate tracking results.
1. Introduction
The ability to track the locations of intermittently speaking multiple speakers in the presence of background noise and reverberation is of great interest due to the vast number of potential applications. In the traditional approach to this problem, firstly the location of each speaker is estimated using a sound source localization method such as the MUSIC or time-delay of arrival (TDOA) methods, and then the estimated locations (contacts) are used as inputs to the tracking process using a Kalman filter or extended Kalman filter. In addition, in order to track multiple targets, a data association technique such as Joint Probability Data Association (JPDA) is exploited to bind each estimated location to a target [1].
Recently, the framework of Bayesian unified tracking has been applied to the multiple-target tracking problem [2]. In this framework, the location of a target is not explicitly estimated. Instead, the location estimation, data association, and tracking are simultaneously solved by combining an observation model with a motion model. Moreover, in this framework, a Kalman or extended Kalman filter is not used because the tracking process treats raw input signals from array sensors directly, instead of using the estimated contacts as inputs.
Under these circumstances particle filtering techniques are often applied, and in recent years, some authors have reported the application of these techniques to tracking audio sources, for example, [3, 4]. Using the particle filtering approach, the probability distribution of the estimated locations of the sources being tracked is approximated with a distribution of a state vector of particles and the state of each particle is recursively updated. The prediction step uses prior information about each source's previous location together with a predefined motion model (usually a random walk, which is a simple model and one that allows us to evaluate the performance of the particle algorithm itself), to predict the current locations of the sources. This "prediction-likelihood" is then weighted using received microphone signals, through the measurement likelihood, and particles are resampled according to their weights to obtain the posterior distribution from which the location estimate can be found.
The incorporation of any prior knowledge into this framework allows for more robust tracking as seen in [3], where the application of Time Delay Estimation (TDE) within a particle filtering framework provides improved robustness to spurious peaks in the correlation caused by reverberation and background noise. As well as this increased robustness the number of data samples required by particle filtering methods is less than that required for high resolution techniques such as MUSIC [5]. This is a particularly important point when tracking moving sources.
While various particle filtering methods have been applied to the problem of tracking a single speaker, the extension of these techniques to the case of multiple speakers is not straightforward. This is mainly due to the fact that one or more of the speakers may not be speaking at any given moment, making it necessary to estimate the number of "active" speakers and also which particular speakers are active at that time.
In the literature this problem is solved by introducing hidden variables which represent the status of each speaker. Then the particle filter is applied to solve the joint problem of estimating the speaker status and tracking the locations of speakers [6, 7]. However, this approach leads to greater computational complexity as the number of speakers increases. Therefore in this paper we instead use an alternative approach of firstly estimating the number of active speakers and then using the particle filter to perform the tracking of their locations.
In order to estimate the number of active speakers, we introduce a method based on the Exponential Fitting Test (EFT), a source number estimation technique proposed in [8] and which is extended to allow for the presence of reverberation in [9]. Identification of the active speakers is then performed. Finally, all speakers, including inactive speakers who are silent for some periods of time during the recording process are tracked using a particle filter.
It should be noted that once a speaker becomes inactive, he can no longer be tracked. However, using the state transition probability, an estimate of an inactive speaker location can be retained, which is an advantage in updating the speaker location once the speaker becomes active again. A block diagram for the proposed algorithm is shown in Figure 1. Live recordings are used, firstly, to evaluate the tracking algorithm and then, secondly, to evaluate the performance of the proposed speaker activity detection step.

Block diagram for the proposed algorithm.
2. Problem Formulation
In this paper we investigate the problem of tracking the location of  moving speakers using an array of
moving speakers using an array of  microphones. Each speaker speaks intermittently. The audio signal is treated in the frequency domain. The short-time Fourier transform (STFT) of the
microphones. Each speaker speaks intermittently. The audio signal is treated in the frequency domain. The short-time Fourier transform (STFT) of the  microphone inputs is denoted as
microphone inputs is denoted as

where  denotes the STFT of the
denotes the STFT of the  th microphone input at time
th microphone input at time  and frequency
and frequency  , and the superscript
, and the superscript  denotes the transpose of a vector or a matrix. We estimate the location of speakers every
denotes the transpose of a vector or a matrix. We estimate the location of speakers every  STFT frames. A processing data block is denoted as
STFT frames. A processing data block is denoted as

where  is the start time of the
is the start time of the  th block.
th block.
Let  and
and  denote the entire data in the
denote the entire data in the  th block and the locations of the
th block and the locations of the  speakers, respectively. That is
speakers, respectively. That is

where  and
and  are the lowest and highest frequencies respectively. Then our problem is to estimate
are the lowest and highest frequencies respectively. Then our problem is to estimate  using observed data
using observed data  .
.
2.1. Bayesian Multiple Target Tracking
We treat the problem within the framework of Bayesian tracking theory [2]. In this framework, the tracking problem is reduced to calculating the posterior probability distribution  of the target variable
of the target variable  given the observation
given the observation  . We introduce the standard Markov assumption about the movement of the speakers and the observation process. That is, we assume that the following recursive equation holds for all
. We introduce the standard Markov assumption about the movement of the speakers and the observation process. That is, we assume that the following recursive equation holds for all  :
:

where  is the normalization constant,
is the normalization constant,  is the measurement likelihood (observation model), and
is the measurement likelihood (observation model), and  is the state transition probability (motion model).
is the state transition probability (motion model).
2.2. Particle Filters
In general, computing the integral according to  in (4) is analytically impossible for nonlinear observation/motion models. The usual numerical integration becomes intractable as the number of speakers
in (4) is analytically impossible for nonlinear observation/motion models. The usual numerical integration becomes intractable as the number of speakers  increases because the dimension of the integrated variable space increases and the computational cost increases exponentially. The particle filter is a popular approach to calculate the posterior distribution approximately for nonlinear models [10].
increases because the dimension of the integrated variable space increases and the computational cost increases exponentially. The particle filter is a popular approach to calculate the posterior distribution approximately for nonlinear models [10].
The posterior distribution of the target variable  is approximated by the distribution of a number of weighted discrete points, that is, particles. The
is approximated by the distribution of a number of weighted discrete points, that is, particles. The  th particle is associated with a state value of
th particle is associated with a state value of  and a weight value
and a weight value  called "the importance" of the particle. Then the empirical probability density of
called "the importance" of the particle. Then the empirical probability density of  is defined as
is defined as

where  is the number of particles and
is the number of particles and  is Dirac's delta function. If the particles are correctly distributed, then according to Kolmogorov's strong law of large numbers, as the number of particles increases toward infinity the empirical distribution approaches the true posterior density.
is Dirac's delta function. If the particles are correctly distributed, then according to Kolmogorov's strong law of large numbers, as the number of particles increases toward infinity the empirical distribution approaches the true posterior density.
A recursive step of the simplest particle filtering algorithm for computing the posterior  is as follows.
is as follows.
-
(1)
Let a set of particles and weights for the
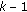 th block
th block  be given.
be given. -
(2)
Generate a new set of particles
 by propagating the particles according to the motion model
by propagating the particles according to the motion model  .
. -
(3)
(3)Compute the measurement likelihood
 for each particle.
for each particle. -
(4)
Revise the weight values as
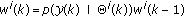 and normalize the weights as
and normalize the weights as  .
. -
(5)
Resample particles in proportion to the weight values and reset all weights as
 .
.
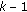 th block
th block  be given.
be given. by propagating the particles according to the motion model
by propagating the particles according to the motion model  .
. for each particle.
for each particle.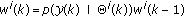 and normalize the weights as
and normalize the weights as  .
. .
.Hence, for implementing the basic particle filter, only the evaluation of the measurement likelihood for each particle is necessary.
The final estimate of the source locations can then be obtained by maximizing the posterior probability distribution (MAP estimate), or by taking the weighted mean over the particles as

This yields an approximation of the expectation of  under the posterior
under the posterior  , which is called the minimum mean-square error (MMSE) estimate. In this research, we used the MMSE estimate.
, which is called the minimum mean-square error (MMSE) estimate. In this research, we used the MMSE estimate.
2.3. The Problem of Intermittent Speech
So far we have explained the standard procedure for Bayesian multiple target tracking. The main difficulty with our problem comes from the fact that speakers speak intermittently. This means that the measurement likelihood  changes depending on the status of each speaker, that is, which speakers are active in the
changes depending on the status of each speaker, that is, which speakers are active in the  th block.
th block.
In previous studies this problem has been solved by introducing hidden variables which represent the status of each speaker. Then a particle filter is applied to solve the joint problem of estimating the speaker status and tracking the locations of speakers [6, 7]. However this approach turns out to require large numbers of particles when the number of speakers increases, in order to estimate the active speakers using a particle filter, because the number of possible combinations of active and inactive speakers increases exponentially. This property is not suitable for real-time applications.
In this paper we instead propose an alternative approach of firstly estimating the number of active speakers and identifying them, then using a particle filter to perform the tracking. With this approach, the particle filter is not used to track the combinatorial speakers' status and the number of particles can be reduced. In addition, we introduce online estimation of the noise covariance matrix based on detection of the silence region (for details of the detection method, see Section 3.2). Figure 1 depicts a block diagram of the overall tracking process. Each step is explained in detail in the following sections.
3. Noise-Only Covariance Estimation
As the first step, the noise-only frequency subbands are identified by a pause detection technique, and the noise-only covariance matrix is estimated. In order to determine the number of speakers, we need the eigenvalues of the noise-plus-reverberation matrix. However, this matrix is unknown. Instead, since we can estimate the noise-only covariance matrix, we consider obtaining a better approximation to the true noise-plus-reverberation eigenvalues by correcting the eigenvalues of the noise-only covariance matrix with a correction factor. The correction factor is discussed in Section 4. Therefore, in this section, we propose a method for estimating the noise-only covariance matrix.
3.1. Signal Model
We denote the number of active speakers by  . The microphone input
. The microphone input  for
for  directional signals
directional signals  plus background noise
plus background noise  is modeled as
is modeled as

where  is the matrix composed of the
is the matrix composed of the  direct path transfer function vectors:
direct path transfer function vectors:

Here we assume that  is constant during a processing data block, that is,
is constant during a processing data block, that is,  depends only on
depends only on  . This assumption is satisfied when
. This assumption is satisfied when  , the size of the processing block, is small enough. In the experiment below, we set
, the size of the processing block, is small enough. In the experiment below, we set  equal to
equal to  ; this means that the block length is 0.1 second, where the time 0.1 second is derived from the experimental conditions shown in Table 1 in Section 6. Each transfer function vector is
; this means that the block length is 0.1 second, where the time 0.1 second is derived from the experimental conditions shown in Table 1 in Section 6. Each transfer function vector is

where  and
and  denote the gain and the time delay, respectively, between the
denote the gain and the time delay, respectively, between the  th speaker and the
th speaker and the  th microphone.
th microphone.  is the source spectrum vector, and
is the source spectrum vector, and  is the background noise spectrum vector.
is the background noise spectrum vector.
Normally it is assumed that the signal and noise are uncorrelated and that the noise is Gaussian with known power. However, in most practical situations this assumption will not hold because of the existence of reverberation, and it is shown in [11] that it leads to degraded tracking results. It is therefore desirable to use a more accurate model of the background noise.
3.2. Determination of Silence Regions of Speakers
We first detect the noise-only subbands based on the noise characterization method proposed in [12], in which a threshold is applied to each frequency subband in order to distinguish between frequencies containing only noise and frequencies containing speech components.The energy of a subband  for the
for the  th block is defined as
th block is defined as

where the superscript  denotes the conjugate transpose of the matrix. The noise threshold
denotes the conjugate transpose of the matrix. The noise threshold  is calculated as
is calculated as

where  is a constant value lying between
is a constant value lying between  and
and  which can be chosen during the training period.
which can be chosen during the training period.  is the energy of the previous noise estimate at the given frequency
is the energy of the previous noise estimate at the given frequency  and it is determined by averaging the previous noise energy values at this frequency over a specified time period.
and it is determined by averaging the previous noise energy values at this frequency over a specified time period.
A decision is then made as to whether or not each frequency subband contains the required target signal. If the power of the subband  satisfies
satisfies  , the frequency value
, the frequency value  is determined as a noise-only subband and
is determined as a noise-only subband and  is updated using
is updated using  . Otherwise,
. Otherwise,  is considered to contain signal components, and
is considered to contain signal components, and  is not updated (
is not updated ( ). This allows the noise power estimate to be continuously updated on a frequency-by-frequency basis, even while someone is speaking.
). This allows the noise power estimate to be continuously updated on a frequency-by-frequency basis, even while someone is speaking.
3.3. Calculate Noise-Only Covariance Matrix
The noise-only covariance matrix estimate for a frequency subband  can be defined as
can be defined as

If  , the frequency subband is determined to contain no signal component. This means that
, the frequency subband is determined to contain no signal component. This means that  and the estimate of the covariance can be computed as
and the estimate of the covariance can be computed as

The resulting covariance estimate is then smoothed over some period of time in order to stabilize the estimate

where  is the number of previous values used for smoothing.
is the number of previous values used for smoothing.
4. Estimation of the Number of Active Speakers
The second step is estimating the number of active speakers  . For sound source number estimation, statistical model selection criteria such as the Minimum Description Length (MDL) [13] and Akaike's Information Criterion (AIC) [14] are traditionally used. However, both these approaches are based on an assumption of white noise and are known to consistently overestimate the number of sources present when reverberation is present [15].
. For sound source number estimation, statistical model selection criteria such as the Minimum Description Length (MDL) [13] and Akaike's Information Criterion (AIC) [14] are traditionally used. However, both these approaches are based on an assumption of white noise and are known to consistently overestimate the number of sources present when reverberation is present [15].
In what follows we use the method proposed in [8], extended to cover reverberant environments as detailed in [9]. The method is based on analyzing the eigenvalues of the covariance matrix of input signals. Hereinafter, we describe the procedure for a frequency subband  in a processing block
in a processing block  . The index of the block
. The index of the block  and the index of the subband frequency
and the index of the subband frequency  are omitted for the sake of simplicity where they are unnecessary.
are omitted for the sake of simplicity where they are unnecessary.
The spatial correlation matrix  of the received signals is defined as
of the received signals is defined as

where  denotes taking the average over time. Using the signal model (7), the covariance can be written as
denotes taking the average over time. Using the signal model (7), the covariance can be written as

where

As is described in the previous section, normally it is assumed that the signal and the noise are uncorrelated. Then the covariance matrices become

Here,  denotes a diagonal matrix with diagonal elements
denotes a diagonal matrix with diagonal elements  and
and  denotes the power of
denotes the power of  , that is,
, that is,  , where the superscript
, where the superscript  represents the conjugate. In the same manner, the observed noise is assumed to be uncorrelated:
represents the conjugate. In the same manner, the observed noise is assumed to be uncorrelated:

where  (
( ) denotes the power of
) denotes the power of  .
.
If we can assume that all  are equal to
are equal to  , the noise covariance can be written as
, the noise covariance can be written as  using the
using the  identity matrix
identity matrix  . Then (16) can be reexpressed as:
. Then (16) can be reexpressed as:

and the eigenvalues of  are therefore given by
are therefore given by

The number of eigenvalues corresponding to the signal subspace, the so-called signal eigenvalues, is equal to the number of active sources, and assuming that the source power is greater than that of the background noise, the number of sources present can now be easily determined as the number of eigenvalues not equal to  .
.
In practice, however,  is unknown and must instead be estimated using
is unknown and must instead be estimated using

In this case the active source number estimation problem still consists of distinguishing between the signal and noise eigenvalues. However, with the statistical fluctuations in  , the noise eigenvalues are no longer all equal to
, the noise eigenvalues are no longer all equal to  . In particular, for moving sources, we cannot take large
. In particular, for moving sources, we cannot take large  and the fluctuations become larger. The separation between noise and signal eigenvalues is only clear now in the case of high Signal-to-Noise Ratio (SNR) and low reverberation, when a gap can be clearly observed.
and the fluctuations become larger. The separation between noise and signal eigenvalues is only clear now in the case of high Signal-to-Noise Ratio (SNR) and low reverberation, when a gap can be clearly observed.
In order to distinguish between signal and noise eigenvalues for moving sources conditions, we approximate the decreasing profile of the eigenvalues of the noise spatial correlation matrix  , and compare this to the profile of the observed eigenvalues of
, and compare this to the profile of the observed eigenvalues of  . It is known that a decreasing profile can be approximated using the first- and second-order moments of the eigenvalues together with an initial assumption of white noise [8]. The smallest observed eigenvalue
. It is known that a decreasing profile can be approximated using the first- and second-order moments of the eigenvalues together with an initial assumption of white noise [8]. The smallest observed eigenvalue  is assumed to be a noise eigenvalue, corresponding to a noise subspace dimension of
is assumed to be a noise eigenvalue, corresponding to a noise subspace dimension of  . Then incrementing
. Then incrementing  by 1 for each subsequent step until
by 1 for each subsequent step until  , the predicted profile of the noise only eigenvalues is found recursively using
, the predicted profile of the noise only eigenvalues is found recursively using

where


The relative differences between the predicted and observed  th eigenvalue profiles
th eigenvalue profiles  are calculated using
are calculated using

and  is then compared to a threshold value
is then compared to a threshold value  in order to distinguish the signal eigenvalues. These threshold values
in order to distinguish the signal eigenvalues. These threshold values  for
for  =
=  are selected from the distribution of the relative differences for each frequency component when there is only noise present at that frequency (for a discussion on how to select this threshold value see [9]). Also, for the details on the derivation of (23) through (25), see [8].
are selected from the distribution of the relative differences for each frequency component when there is only noise present at that frequency (for a discussion on how to select this threshold value see [9]). Also, for the details on the derivation of (23) through (25), see [8].
The predicted noise eigenvalue profile  is based on the assumption that the background noise can be modeled as white noise. This approximation is valid in many practical situations when none of the speakers are active. Once some of the speakers are active though, reverberant tails arising due to the presence of speech violate this white noise assumption and lead to an increase in the noise eigenvalue profile.
is based on the assumption that the background noise can be modeled as white noise. This approximation is valid in many practical situations when none of the speakers are active. Once some of the speakers are active though, reverberant tails arising due to the presence of speech violate this white noise assumption and lead to an increase in the noise eigenvalue profile.
In this case the noise eigenvalue profile predicted from (23)–(25) will be lower than that of the observed noise eigenvalues, resulting in frequent overestimation of the number of active sources. Therefore once it is known that at least one speaker is present, it is necessary to apply a correction factor to the predicted profile in order to account for the increase in the noise eigenvalues due to reverberation.
In order to calculate a suitable correction factor the eigenvalues of the estimated reverberation-only correlation matrix,  , are evaluated. These values are then used to find the corresponding predicted noise eigenvalues
, are evaluated. These values are then used to find the corresponding predicted noise eigenvalues  as described in (23)–(25). It should be noted that the reverberation-only correlation matrix is estimated using impulse responses recorded in the room in which the tracking is carried out.
as described in (23)–(25). It should be noted that the reverberation-only correlation matrix is estimated using impulse responses recorded in the room in which the tracking is carried out.
The difference between the predicted and observed profiles, relative to the largest observed eigenvalue, is then taken as a correction factor:

In the presence of at least one active source the correction factor is then used to modify the originally predicted noise eigenvalue profile:

Once again the predicted and observed profiles are compared by finding their relative difference:

If  then
then  is a signal eigenvalue. The number of active speakers at this subband is then estimated as the number of signal eigenvalues. In order to obtain the final estimate of the number of active speakers for the broad band signal,
is a signal eigenvalue. The number of active speakers at this subband is then estimated as the number of signal eigenvalues. In order to obtain the final estimate of the number of active speakers for the broad band signal,  , the estimate in each subband is averaged over all active subbands within the frequency range [
, the estimate in each subband is averaged over all active subbands within the frequency range [ ].
].
5. Evaluating Measurement Likelihood
The third step is identifying the active speakers and evaluating the measurement likelihood  for each particle. We exploit the random signal model in [16], that is, we assume that each
for each particle. We exploit the random signal model in [16], that is, we assume that each  is a 0-mean circular complex Gaussian random vector, with unknown covariance, and that successive samples of
is a 0-mean circular complex Gaussian random vector, with unknown covariance, and that successive samples of  are independent but share a common density. We also assume that components of
are independent but share a common density. We also assume that components of  are independent of each other; hence the covariance matrix
are independent of each other; hence the covariance matrix  is diagonal.
is diagonal.
5.1. Decomposing the Likelihood
For a while, we assume that all  speakers are speaking. Then the log likelihood function of the observed data
speakers are speaking. Then the log likelihood function of the observed data  given the location of the
given the location of the  speakers
speakers  , the signal covariance matrix
, the signal covariance matrix  , and the noise covariance matrix
, and the noise covariance matrix  is
is

where we have discarded unnecessary constant terms. As we described,  can be written as
can be written as

where

and  is the transfer function vector for the location
is the transfer function vector for the location  . Note that the log likelihood function
. Note that the log likelihood function  is a nonlinear function of the location parameters
is a nonlinear function of the location parameters  . Hence, it is impossible to apply the Kalman filter to our tracking problem.
. Hence, it is impossible to apply the Kalman filter to our tracking problem.
Now we introduce a hidden "complete data vector"  as in [16] which corresponds to the signal due to each speaker, and assume that the observed microphone signals can be decomposed into these signals as
as in [16] which corresponds to the signal due to each speaker, and assume that the observed microphone signals can be decomposed into these signals as

where

where  is an arbitrary decomposition of the noise vector
is an arbitrary decomposition of the noise vector  , which must satisfy
, which must satisfy  .
.
Then under the assumption of uncorrelated signals, that is,

the log likelihood of  can be decomposed into the sum of the log likelihoods of the individual
can be decomposed into the sum of the log likelihoods of the individual  thus
thus

Here


Using the sample covariance matrix  of the complete data
of the complete data 

the log-likelihood can be rewritten as:

As the complete data is not known  cannot be determined directly. However the correlation matrix can be estimated using the following equations in the Expectation step of the EM algorithm in [16]:
cannot be determined directly. However the correlation matrix can be estimated using the following equations in the Expectation step of the EM algorithm in [16]:

with

It can be seen that this expression requires  , an estimation of the power of the
, an estimation of the power of the  th speaker, and
th speaker, and  , an estimation of the decomposed noise covariance matrix
, an estimation of the decomposed noise covariance matrix  .
.  can be estimated from
can be estimated from  using
using

Finally the estimate of the decomposed noise covariance matrix  is given by evenly dividing the noise-only-reverberant covariance matrix, which is estimated in Section 3.3, among the number of speakers as:
is given by evenly dividing the noise-only-reverberant covariance matrix, which is estimated in Section 3.3, among the number of speakers as:

This method allows for tracking the sources in situations where there is no prior knowledge of the background noise, thus making it much more useful for practical tracking problems.
Applying the above procedure for all active frequency subbands  and taking the mean of
and taking the mean of  , we get the estimated partial log likelihood
, we get the estimated partial log likelihood  as
as

where  and
and  are the set of active frequency subbands and the number of active subbands respectively, and
are the set of active frequency subbands and the number of active subbands respectively, and  is the collection of
is the collection of  for all active subbands.
for all active subbands.
5.2. Identifying Active Speakers
So far we have assumed that all  speakers are active. When one or more speakers are inactive, we need to identify the active speakers. In this paper we identify the active speakers by comparing the values of the estimated partial likelihood
speakers are active. When one or more speakers are inactive, we need to identify the active speakers. In this paper we identify the active speakers by comparing the values of the estimated partial likelihood  for the
for the  th speaker.
th speaker.
We calculate the average of  for all particles as
for all particles as

where  is the
is the  th value of the state vector of the
th value of the state vector of the  th particle. Then the
th particle. Then the  th speaker which corresponds to the
th speaker which corresponds to the  largest values of (46) is determined to be active. Here
largest values of (46) is determined to be active. Here  is the estimate of the number of active speakers for the broad band signal which was given in Section 4. We denote the set of indices for the active speakers as
is the estimate of the number of active speakers for the broad band signal which was given in Section 4. We denote the set of indices for the active speakers as  .
.
5.3. Evaluating Likelihood
As the measurement likelihood of the audio input is irrelevant for the location of inactive speakers, the total log likelihood for the  th particle can be obtained by taking the sum of the decomposed log likelihoods only for active speakers as
th particle can be obtained by taking the sum of the decomposed log likelihoods only for active speakers as

Then the measurement likelihood for the  th particle is obtained as
th particle is obtained as

Using this likelihood, we can execute the particle filtering algorithm described in Section 2.2, and compute the estimate of the source location for the target processing block using the (6).
6. Experimental Results
The proposed tracking method was tested using recordings taken in a medium sized meeting room ( ) with a reverberation time of 500 millisecond. As shown in Figure 2, three people, one female and two males, moved around the room, while speaking intermittently. The speech was recorded using a uniform circular array of
) with a reverberation time of 500 millisecond. As shown in Figure 2, three people, one female and two males, moved around the room, while speaking intermittently. The speech was recorded using a uniform circular array of  microphones which was placed at ceiling height, and the distance between the microphone array and the speakers was sufficient to ensure far-field conditions. The recorded signals were divided into frames of length 32 millisecond, with an averaging interval of
microphones which was placed at ceiling height, and the distance between the microphone array and the speakers was sufficient to ensure far-field conditions. The recorded signals were divided into frames of length 32 millisecond, with an averaging interval of  (block length), or approximately 0.1 second. The experimental parameters are given in Table 1.
(block length), or approximately 0.1 second. The experimental parameters are given in Table 1.

Experimental layout. The three people are denoted P1, P2, P3, and the dashed line traces their movements. The microphone array is set at ceiling heightVideo image taken during recordings
We note that the rates of the time intervals for the cases when only one speaker, two speakers, and three speakers are speaking are  ,
,  , and
, and  , respectively. The time intervals for the case when no speaker is active is only
, respectively. The time intervals for the case when no speaker is active is only  . This means that the time during which multiple speakers are speaking simultaneously is rather long in the data. Moreover, the average times of a silence (inactive) region for speakers P1, P2, and P3 are 0.48 second, 0.26 second, and 0.93 second, respectively.
. This means that the time during which multiple speakers are speaking simultaneously is rather long in the data. Moreover, the average times of a silence (inactive) region for speakers P1, P2, and P3 are 0.48 second, 0.26 second, and 0.93 second, respectively.
The true trajectory of the speakers was found using a zone positioning system ZPS-3D by Furukawa Co., Ltd. and is depicted by the dashed lines in Figure 2(a) and Figures 3, 4, and 5, which shows the experimental layout. Using the zone positioning system, a badge is pinned on the chest of each of the speakers and the location of the badge is then tracked. According to the specification of the system, the measurement accuracy is  to
to  mm depending on the environment and the measured distance.
mm depending on the environment and the measured distance.

Tracking results. The dashed lines represent the trace of the actual motions.Measurement likelihood found using the proposed algorithm, Background noise assumed white.Measurement likelihood found using the proposed algorithm, Estimated background noise.

The tracking result (estimated covariance matrix of background noise, but the diagonal elements of the matrix are a constant value). The dashed lines represent the trace of the actual motions.

Tracking results. The dashed lines represent the trace of the actual motions.Measurement likelihood found using MUSICMeasurement likelihood found using TDOA
In the following subsections we will describe the results of three experiments using the data. In Section 6.1 the accuracy of the proposed tracking method is evaluated using the Root Mean Square Error (RMSE) between the true trajectory and the estimated trajectory. Three kinds of noise covariance matrix, simply assuming white noise, using an estimate of the noise covariance matrix, and using modified noise covariance, are tested and compared. In Section 6.2, tracking results using two pseudolikelihood functions instead of (40) are shown for comparison purposes. In Section 6.3, the accuracy of the speech event detection by the proposed active speaker identification step is evaluated because one of the main applications of the proposed method is envisaged as preprocessing for speech recognition.
6.1. Tracking Experiments
We will show the results when the number of active speakers is estimated at each time step and the silence region detection step is included to eliminate the noise only frequencies. The results for this case are shown in Figure 3, and the corresponding Root Mean Square Error (RMSE) values are shown in Table 2.
Figure 3(a) shows the case where the measurement likelihood is calculated using (48) and the background noise is assumed white. Figure 3(b) shows the result when the measurement likelihood is calculated using (48) and the noise covariance is estimated from the received data using (14) and (44).
An inactive speaker location can no longer be tracked, but using the state transition probability, an estimate of an inactive speaker location can be kept, which is an advantage in updating the speaker location, once the speaker becomes active again. Therefore, the location estimates of the inactive speakers cannot be expected to be very accurate. For this reason we demonstrate the RMSE values forboth the entire data (total) and the time intervals that each speaker was determined to be active(active)in Table 2.
From Table 2, the average performance for the estimated noise case is better than that for the white noise case. This is because the performance of tracking Speaker 3 is improved by estimating the noise covariance matrix,  . However, the performances of tracking Speakers 1 and 2 for the estimated noise case became worse than those for the white noise case.
. However, the performances of tracking Speakers 1 and 2 for the estimated noise case became worse than those for the white noise case.
As a method of improving the result, we tried changing all the diagonal elements of  to the same constant value (say, 0.1). The tracking result is shown in Figure 4 and the RMSE values are shown in Table 3. From the figure and table, one can see that the performances of tracking Speakers 1 and 2 are close to those for the white noise case and the performance of tracking Speaker 3 is close to that for the case of estimated noise.
to the same constant value (say, 0.1). The tracking result is shown in Figure 4 and the RMSE values are shown in Table 3. From the figure and table, one can see that the performances of tracking Speakers 1 and 2 are close to those for the white noise case and the performance of tracking Speaker 3 is close to that for the case of estimated noise.
 are the same constant value, where the RMSE values are calculated from distance estimation in meters (m).
are the same constant value, where the RMSE values are calculated from distance estimation in meters (m).From all the results, we conclude that the tracking performance is improved by estimating  , but that if the performance is not improved, it would be advisable to change all the diagonal elements of
, but that if the performance is not improved, it would be advisable to change all the diagonal elements of  to the same constant value. It should be noted that the nondiagonal elements of
to the same constant value. It should be noted that the nondiagonal elements of  are unchanged.
are unchanged.
6.2. Other Likelihood Functions
For comparison purposes we then considered the same situation but this time the power spectrum as calculated using MUSIC and the energy from TDOA [17], as calculated using  in (49), were instead used as a pseudolikelihood function for the current tracking method:
in (49), were instead used as a pseudolikelihood function for the current tracking method:

where  =
=  and
and  = 2
= 2 .
.
Figures 5(a) and 5(b) show the results obtained by using MUSIC and TDOA, respectively. Table 4 shows the RMSE values of the results. From the results in Figures 5(a) and 5(b), MUSIC and TDOA can track at most, respectively, two speakers and one speaker. This might be because the power spectrum of MUSIC and the energy of TDOA are calculated detecting all speakers. Namely, the observations  , which include the information on all speakers, are used to calculate the likelihood function. On the other hand, the likelihood function of the proposed method is calculated for each speaker, using
, which include the information on all speakers, are used to calculate the likelihood function. On the other hand, the likelihood function of the proposed method is calculated for each speaker, using  in (34) which includes the information on each active speaker. Therefore we conclude that the proposed method using (48) is more suitable for tracking multiple speakers. Note that we are able to confirm that, even if the number of speakers is four, the proposed method can track each speaker [18].
in (34) which includes the information on each active speaker. Therefore we conclude that the proposed method using (48) is more suitable for tracking multiple speakers. Note that we are able to confirm that, even if the number of speakers is four, the proposed method can track each speaker [18].
6.3. Speech Event Detection
In this subsection, the performance of the active speaker identification step is investigated. While the recording in the experiment was being carried out, a lapel microphone was attached to each speaker so that the true period of each speech event could be hand labeled by human listeners. This labeling was then compared to the results found by the proposed active speaker identification method.
From the results given in Table 5 it can be seen that the mean rate of correct determination of the activity state is approximately  , with Speaker 3 having the lowest correct determination rate of
, with Speaker 3 having the lowest correct determination rate of  . However, since the incorrect determined active rate is low, we consider that the proposed active speaker identification method works well. Regarding the incorrectly determined inactive speakers, from the analysis of the speech segments, it turned out that there exists a situation where the speech volume is low or noisy, although the speaker is active. The incorrectly determined inactiverate is somewhat high for Speakers 2 and 3. These resultsreflectthe fact that the speech volume levels of Speakers 2 and 3 are lower than Speaker 1.
. However, since the incorrect determined active rate is low, we consider that the proposed active speaker identification method works well. Regarding the incorrectly determined inactive speakers, from the analysis of the speech segments, it turned out that there exists a situation where the speech volume is low or noisy, although the speaker is active. The incorrectly determined inactiverate is somewhat high for Speakers 2 and 3. These resultsreflectthe fact that the speech volume levels of Speakers 2 and 3 are lower than Speaker 1.
7. Conclusion
This paper proposes a novel scheme for tracking intermittently speaking multiple speakers. In the proposed tracking method, the number of active speakers can be estimated using the observed covariance matrix and the estimated noise-only-reverberant covariance matrix (see Section 3). Then the active speakers are identified using the decomposed likelihood function. Finally all speakers including inactive ones can be tracked using a particle filtering. The proposed method was evaluated using live recordings in the case of three-speakers and the results show that the proposed method produces highly accurate tracking results.
Currently we are concerned with our tracking method being applied in such fields as interfaces between humans and robots or data processing for meetings, and hence we dealt with the case of tracking speech/speakers. However, the proposed method can be applied to the tracking of other types of source, such as musical instruments or vehicles, because we do not use any special properties of speech for tracking. In this paper we tested our approach with a three speaker case. How many targets can be tracked with this approach is also an interesting future research issue.
References
Bar-Shalom Y, Fortmann TE: Tracking and Data Association. Academic Press, San Diego, Calif, USA; 1988.
Stone LD, Barlow CA, Corwin TL: Bayesian Multiple Target Tracking. Artech House, Boston, Mass, USA; 1999.
Vermaak J, Blake A: Nonlinear filtering for speaker tracking in noisy and reverberant environments. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP '01), May 2001, Salt Lake, Utah, USA 5: 3021-3024.
Ward DB, Williamson RC: Particle filter beamforming for acoustic source localization in a reverberant environment. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP '02), May 2002, Orlando, Fla, USA 2: 1777-1780.
Schmidt RO: Multiple emitter location and signal parameter estimation. IEEE Transactions on Antennas and Propagation 1986,34(3):276-280. 10.1109/TAP.1986.1143830
Checka N, Wilson KW, Siracusa MR, Darrell T: Multiple person and speaker activity tracking with a particle filter. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP '04), May 2004, Montreal, Canada 5: 881-884.
Asoh H, Hara I, Asano F, Yamamoto K: Tracking human speech events using a particle filter. Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '05), March 2005, Philadelphia, Pa, USA 2: 1153-1156.
Quinlan A, Barbot J-P, Larzabal P, Haardt M: Model order selection for short data: an exponential fitting test (EFT). EURASIP Journal on Advances in Signal Processing vol 2007, Article ID 71953 11 Pages 2007:.
Quinlan A, Asano F: Detection of overlapping speech in meeting recordings using the modified exponential fitting test. Proceedings of the 15th European Signal Processing Conference (EUSIPCO '07), 2007, Poznan, Poland
Doucet A, Freitas N, Gordon N (Eds): Sequential Monte Carlo Methods in Practice. Springer, New York, NY, USA; 2001.
Quinlan A, Kawamoto M, Asano F, Asoh H, Yamamoto K: Tracking a varying number of sound sources using particle filtering. Proceedings of the 9th IASTED International Conference on Signal and Image Processing (SIP '07), August 2007, Honolulu, Hawaii, USA 123-128.
Hirsch HG, Ehrlicher C: Noise estimation techniques for robust speech recognition. Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '95), May 1995, Detroit, Mich, USA 1: 153-156.
Rissanen J: Modelling by shortest data description length. Automatica 1978, 14: 465-471. 10.1016/0005-1098(78)90005-5
Akaike A: A new look at the statistical model identification. IEEE Transactions on Automatic Control 1974,19(6):716-723. 10.1109/TAC.1974.1100705
Quinlan A, Boland F, Barbot JP, Larzabal P: Determining the number of speakers with a limited number of samples. Proceedings of the European Signal Processing Conference (EUSIPCO '06), 2006, Florence, Italy
Miller MI, Fuhrmann DR: Maximum-likelihood narrow-band direction finding and the EM algorithm. IEEE Transactions on Acoustics, Speech, and Signal Processing 1990,38(9):1560-1577. 10.1109/29.60075
Gehrig T, Klee U, McDonough J, Ikbal S, Wölfel M, Fügen C: Tracking and beamforming for multiple simultaneous speakers with probabilistic data association filters. Proceedings of the 9th International Conference on Spoken Language Processing (INTERSPEECH '06), September 2006, Pittsburgh, Pa, USA 5: 2594-2597.
Quinlan A, Asano F: Tracking a varying number of speakers using particle filtering. Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '08), March 2008, Las Vegas, Nev, USA 297-300.
Acknowledgments
Angela Quinlan would like to acknowledge the support of the Japanese Society for the Promotion of Science (JSPS) postdoctoral fellowship. This research was partly supported by JSPS Kakenhi(A), no.18200007.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Quinlan, A., Kawamoto, M., Matsusaka, Y. et al. Tracking Intermittently Speaking Multiple Speakers Using a Particle Filter. J AUDIO SPEECH MUSIC PROC. 2009, 673202 (2009). https://doi.org/10.1155/2009/673202
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1155/2009/673202